 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2GQA: Retriever-Reader-Generator Question Answering System to Support Students Understanding Legal Regulations in Higher Education
Paper and Code
Sep 04, 2024
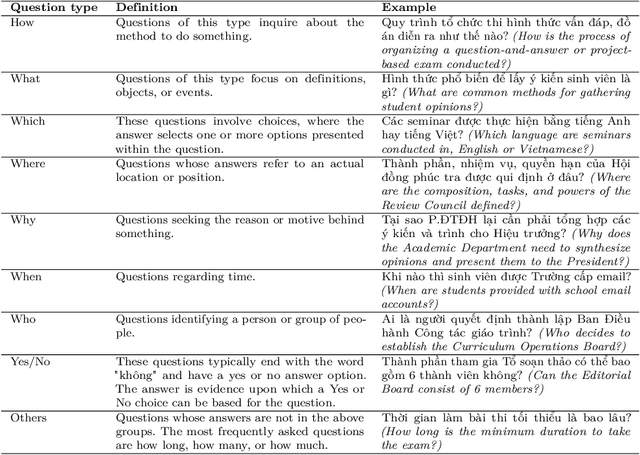


In this article, we propose the R2GQA system, a Retriever-Reader-Generator Question Answering system, consisting of three main components: Document Retriever, Machine Reader, and Answer Generator. The Retriever module employs advanced information retrieval techniques to extract the context of articles from a dataset of legal regulation documents. The Machine Reader module utilizes state-of-the-art natural language understanding algorithms to comprehend the retrieved documents and extract answers. Finally, the Generator module synthesizes the extracted answers into concise and informative responses to questions of students regarding legal regulations. Furthermore, we built the ViRHE4QA dataset in the domain of university training regulations, comprising 9,758 question-answer pairs with a rigorous construction process. This is the first Vietnamese dataset in the higher regulations domain with various types of answers, both extractive and abstractive. In addition, the R2GQA system is the first system to offer abstractive answers in Vietnamese. This paper discusses the design and implementation of each module within the R2GQA system on the ViRHE4QA dataset, highlighting their functionalities and interactions. Furthermore, we present experimental results demonstrating the effectiveness and utility of the proposed system in supporting the comprehension of students of legal regulations in higher education settings. In general, the R2GQA system and the ViRHE4QA dataset promise to contribute significantly to related research and help students navigate complex legal documents and regulations, empowering them to make informed decisions and adhere to institutional policies effectively. Our dataset is available for research purposes.