 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUIT-OpenViIC: A Novel Benchmark for Evaluating Image Captioning in Vietnamese
Paper and Code

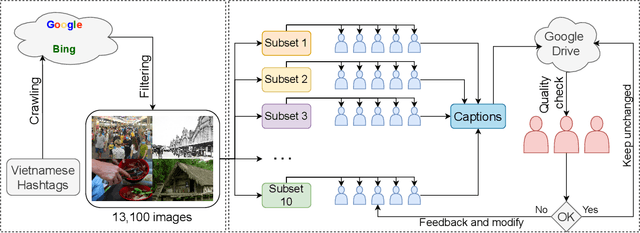
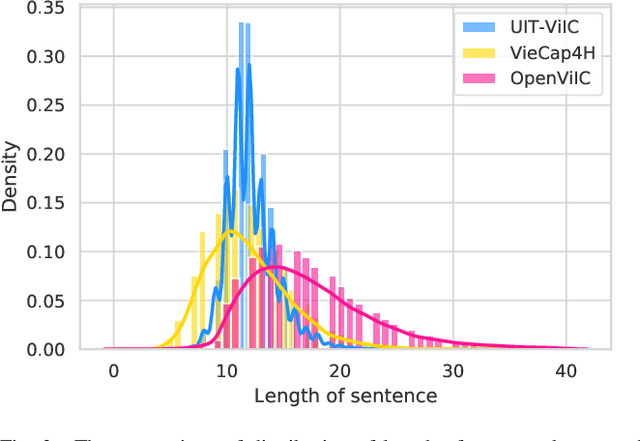
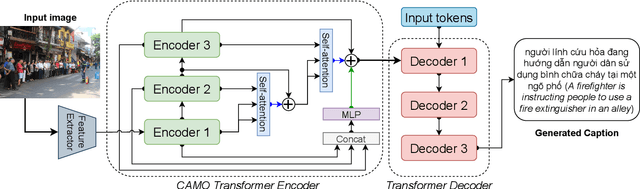
Image Captioning is one of the vision-language tasks that still interest the research community worldwide in the 2020s. MS-COCO Caption benchmark is commonly used to evaluate the performance of advanced captioning models, although it was published in 2015. Recent captioning models trained on the MS-COCO Caption dataset only have good performance in language patterns of English; they do not have such good performance in contexts captured in Vietnam or fluently caption images using Vietnamese. To contribute to the low-resources research community as in Vietnam, we introduce a novel image captioning dataset in Vietnamese, the Open-domain Vietnamese Image Captioning dataset (UIT-OpenViIC). The introduced dataset includes complex scenes captured in Vietnam and manually annotated by Vietnamese under strict rules and supervision. In this paper, we present in more detail the dataset creation process. From preliminary analysis, we show that our dataset is challenging to recent state-of-the-art (SOTA) Transformer-based baselines, which performed well on the MS COCO dataset. Then, the modest results prove that UIT-OpenViIC has room to grow, which can be one of the standard benchmarks in Vietnamese for the research community to evaluate their captioning models. Furthermore, we present a CAMO approach that effectively enhances the image representation ability by a multi-level encoder output fusion mechanism, which helps improve the quality of generated captions compared to previous captioning models.