 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViConsFormer: Constituting Meaningful Phrases of Scene Texts using Transformer-based Method in Vietnamese Text-based Visual Question Answering
Oct 24, 2024
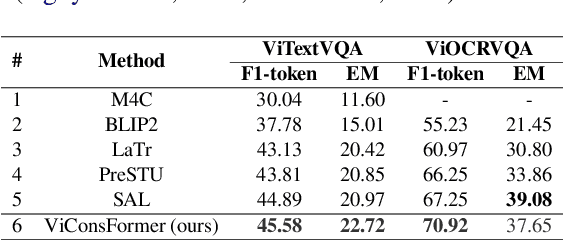
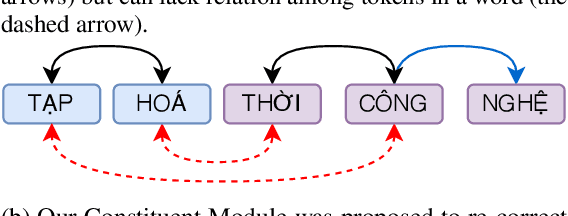
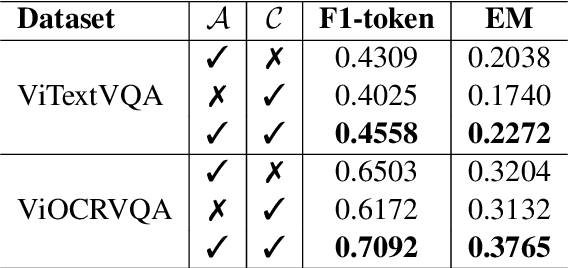
Text-based VQA is a challenging task that requires machines to use scene texts in given images to yield the most appropriate answer for the given question. The main challenge of text-based VQA is exploiting the meaning and information from scene texts. Recent studies tackled this challenge by considering the spatial information of scene texts in images via embedding 2D coordinates of their bounding boxes. In this study, we follow the definition of meaning from linguistics to introduce a novel method that effectively exploits the information from scene texts written in Vietnamese. Experimental results show that our proposed method obtains state-of-the-art results on two large-scale Vietnamese Text-based VQA datasets. The implementation can be found at this link.