Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAT: Parallel Attention Transformer for Visual Question Answering in Vietnamese
Paper and Code
Jul 17, 2023
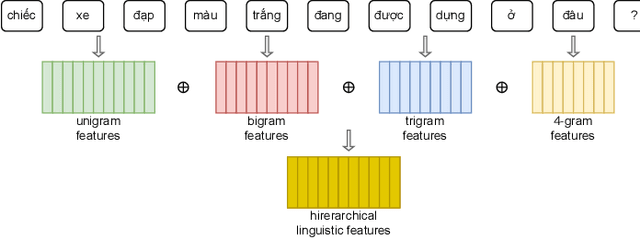


We present in this paper a novel scheme for multimodal learning named the Parallel Attention mechanism. In addition, to take into account the advantages of grammar and context in Vietnamese, we propose the Hierarchical Linguistic Features Extractor instead of using an LSTM network to extract linguistic features. Based on these two novel modules, we introduce the Parallel Attention Transformer (PAT), achieving the best accuracy compared to all baselines on the benchmark ViVQA dataset and other SOTA methods including SAAA and MCAN.
View paper on