 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUIT-DarkCow team at ImageCLEFmedical Caption 2024: Diagnostic Captioning for Radiology Images Efficiency with Transformer Models
May 28, 2024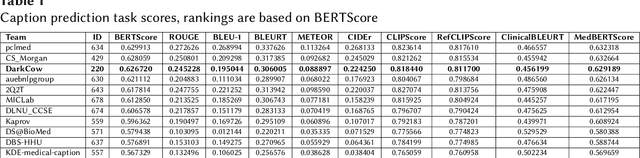

Purpose: This study focuses on the development of automated text generation from radiology images, termed diagnostic captioning, to assist medical professionals in reducing clinical errors and improving productivity. The aim is to provide tools that enhance report quality and efficiency, which can significantly impact both clinical practice and deep learning research in the biomedical field. Methods: In our participation in the ImageCLEFmedical2024 Caption evaluation campaign, we explored caption prediction tasks using advanced Transformer-based models. We developed methods incorporating Transformer encoder-decoder and Query Transformer architectures. These models were trained and evaluated to generate diagnostic captions from radiology images. Results: Experimental evaluations demonstrated the effectiveness of our models, with the VisionDiagnostor-BioBART model achieving the highest BERTScore of 0.6267. This performance contributed to our team, DarkCow, achieving third place on the leaderboard. Conclusion: Our diagnostic captioning models show great promise in aiding medical professionals by generating high-quality reports efficiently. This approach can facilitate better data processing and performance optimization in medical imaging departments, ultimately benefiting healthcare delivery.
ViOCRVQA: Novel Benchmark Dataset and Vision Reader for Visual Question Answering by Understanding Vietnamese Text in Images
Apr 29, 2024



Optical Character Recognition - Visual Question Answering (OCR-VQA) is the task of answering text information contained in images that have just been significantly developed in the English language in recent years. However, there are limited studies of this task in low-resource languages such as Vietnamese. To this end, we introduce a novel dataset, ViOCRVQA (Vietnamese Optical Character Recognition - Visual Question Answering dataset), consisting of 28,000+ images and 120,000+ question-answer pairs. In this dataset, all the images contain text and questions about the information relevant to the text in the images. We deploy ideas from state-of-the-art methods proposed for English to conduct experiments on our dataset, revealing the challenges and difficulties inherent in a Vietnamese dataset. Furthermore, we introduce a novel approach, called VisionReader, which achieved 0.4116 in EM and 0.6990 in the F1-score on the test set. Through the results, we found that the OCR system plays a very important role in VQA models on the ViOCRVQA dataset. In addition, the objects in the image also play a role in improving model performance. We open access to our dataset at link (https://github.com/qhnhynmm/ViOCRVQA.git) for further research in OCR-VQA task in Vietnamese.
ViTextVQA: A Large-Scale Visual Question Answering Dataset for Evaluating Vietnamese Text Comprehension in Images
Apr 16, 2024



Visual Question Answering (VQA) is a complicated task that requires the capability of simultaneously processing natural language and images. Initially, this task was researched, focusing on methods to help machines understand objects and scene contexts in images. However, some text appearing in the image that carries explicit information about the full content of the image is not mentioned. Along with the continuous development of the AI era, there have been many studies on the reading comprehension ability of VQA models in the world. As a developing country, conditions are still limited, and this task is still open in Vietnam. Therefore, we introduce the first large-scale dataset in Vietnamese specializing in the ability to understand text appearing in images, we call it ViTextVQA (\textbf{Vi}etnamese \textbf{Text}-based \textbf{V}isual \textbf{Q}uestion \textbf{A}nswering dataset) which contains \textbf{over 16,000} images and \textbf{over 50,000} questions with answers. Through meticulous experiments with various state-of-the-art models, we uncover the significance of the order in which tokens in OCR text are processed and selected to formulate answers. This finding helped us significantly improve the performance of the baseline models on the ViTextVQA dataset. Our dataset is available at this \href{https://github.com/minhquan6203/ViTextVQA-Dataset}{link} for research purposes.