 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs word segmentation necessary for Vietnamese sentiment classification?
Paper and Code
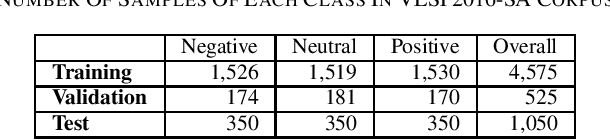
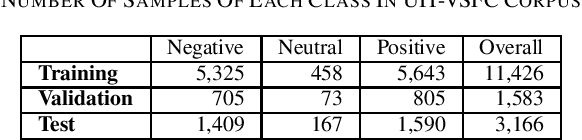
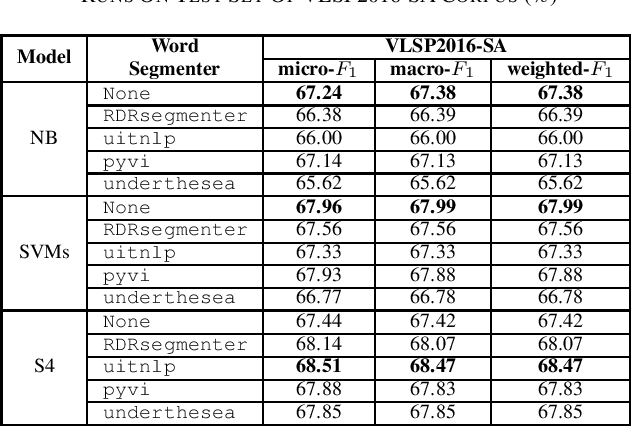
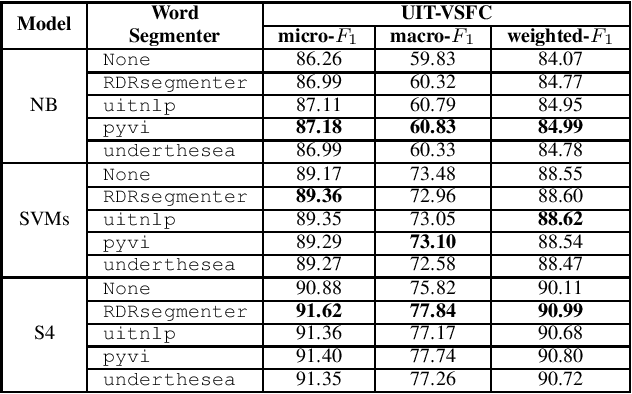
To the best of our knowledge, this paper made the first attempt to answer whether word segmentation is necessary for Vietnamese sentiment classification. To do this, we presented five pre-trained monolingual S4- based language models for Vietnamese, including one model without word segmentation, and four models using RDRsegmenter, uitnlp, pyvi, or underthesea toolkits in the pre-processing data phase. According to comprehensive experimental results on two corpora, including the VLSP2016-SA corpus of technical article reviews from the news and social media and the UIT-VSFC corpus of the educational survey, we have two suggestions. Firstly, using traditional classifiers like Naive Bayes or Support Vector Machines, word segmentation maybe not be necessary for the Vietnamese sentiment classification corpus, which comes from the social domain. Secondly, word segmentation is necessary for Vietnamese sentiment classification when word segmentation is used before using the BPE method and feeding into the deep learning model. In this way, the RDRsegmenter is the stable toolkit for word segmentation among the uitnlp, pyvi, and underthesea toolkits.