 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Perspective Data Augmentation for Few-shot Object Detection
Feb 25, 2025Recent few-shot object detection (FSOD) methods have focused on augmenting synthetic samples for novel classes, show promising results to the rise of diffusion models. However, the diversity of such datasets is often limited in representativeness because they lack awareness of typical and hard samples, especially in the context of foreground and background relationships. To tackle this issue, we propose a Multi-Perspective Data Augmentation (MPAD) framework. In terms of foreground-foreground relationships, we propose in-context learning for object synthesis (ICOS) with bounding box adjustments to enhance the detail and spatial information of synthetic samples. Inspired by the large margin principle, support samples play a vital role in defining class boundaries. Therefore, we design a Harmonic Prompt Aggregation Scheduler (HPAS) to mix prompt embeddings at each time step of the generation process in diffusion models, producing hard novel samples. For foreground-background relationships, we introduce a Background Proposal method (BAP) to sample typical and hard backgrounds. Extensive experiments on multiple FSOD benchmarks demonstrate the effectiveness of our approach. Our framework significantly outperforms traditional methods, achieving an average increase of $17.5\%$ in nAP50 over the baseline on PASCAL VOC. Code is available at https://github.com/nvakhoa/MPAD.
Efficient Finetuning Large Language Models For Vietnamese Chatbot
Sep 09, 2023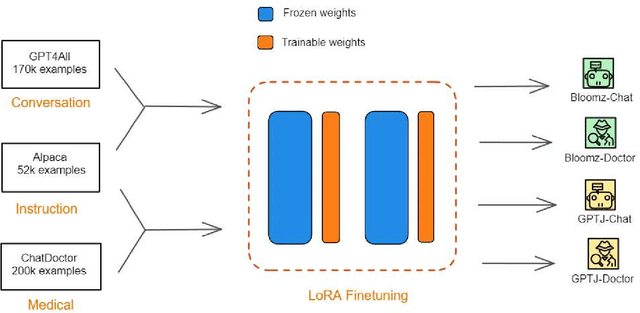

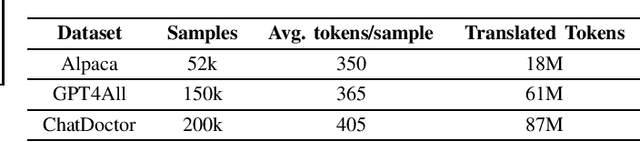
Large language models (LLMs), such as GPT-4, PaLM, and LLaMa, have been shown to achieve remarkable performance across a variety of natural language tasks. Recent advancements in instruction tuning bring LLMs with ability in following user's instructions and producing human-like responses. However, the high costs associated with training and implementing LLMs pose challenges to academic research. Furthermore, the availability of pretrained LLMs and instruction-tune datasets for Vietnamese language is limited. To tackle these concerns, we leverage large-scale instruction-following datasets from open-source projects, namely Alpaca, GPT4All, and Chat-Doctor, which cover general domain and specific medical domain. To the best of our knowledge, these are the first instructional dataset for Vietnamese. Subsequently, we utilize parameter-efficient tuning through Low-Rank Adaptation (LoRA) on two open LLMs: Bloomz (Multilingual) and GPTJ-6B (Vietnamese), resulting four models: Bloomz-Chat, Bloomz-Doctor, GPTJ-Chat, GPTJ-Doctor.Finally, we assess the effectiveness of our methodology on a per-sample basis, taking into consideration the helpfulness, relevance, accuracy, level of detail in their responses. This evaluation process entails the utilization of GPT-4 as an automated scoring mechanism. Despite utilizing a low-cost setup, our method demonstrates about 20-30\% improvement over the original models in our evaluation tasks.