 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbusive Span Detection for Vietnamese Narrative Texts
Paper and Code
Dec 13, 2023
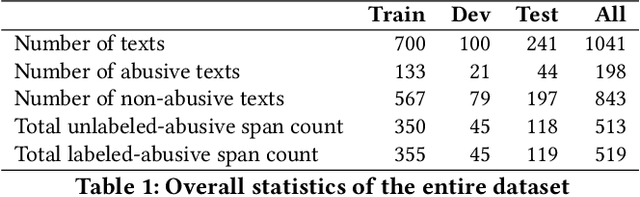

Abuse in its various forms, including physical, psychological, verbal, sexual, financial, and cultural, has a negative impact on mental health. However, there are limited studies on applying natural language processing (NLP) in this field in Vietnam. Therefore, we aim to contribute by building a human-annotated Vietnamese dataset for detecting abusive content in Vietnamese narrative texts. We sourced these texts from VnExpress, Vietnam's popular online newspaper, where readers often share stories containing abusive content. Identifying and categorizing abusive spans in these texts posed significant challenges during dataset creation, but it also motivated our research. We experimented with lightweight baseline models by freezing PhoBERT and XLM-RoBERTa and using their hidden states in a BiLSTM to assess the complexity of the dataset. According to our experimental results, PhoBERT outperforms other models in both labeled and unlabeled abusive span detection tasks. These results indicate that it has the potential for future improvements.