 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025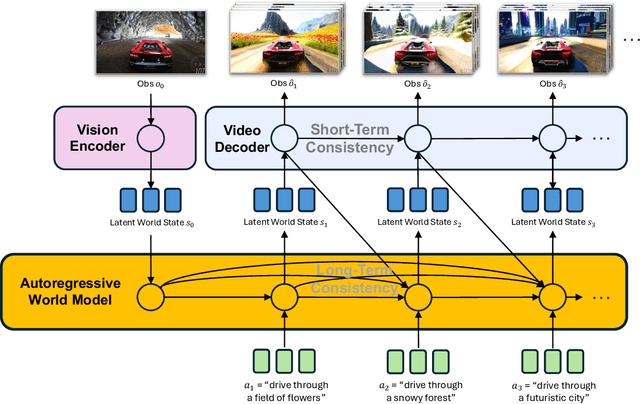
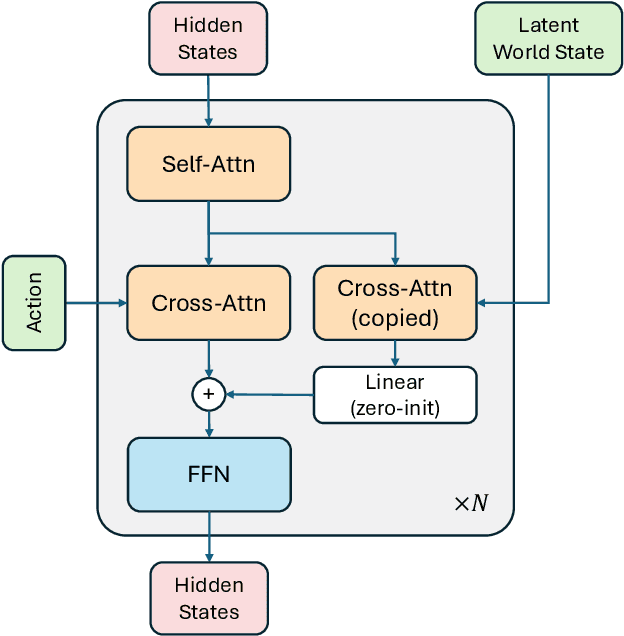
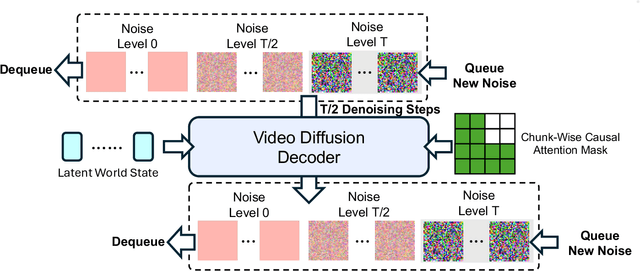
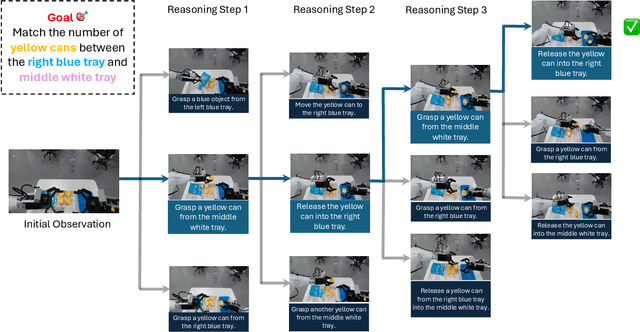
A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
Libra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Dec 24, 2024



To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.
Improving Logits-based Detector without Logits from Black-box LLMs
Jun 11, 2024



The advent of Large Language Models (LLMs) has revolutionized text generation, producing outputs that closely mimic human writing. This blurring of lines between machine- and human-written text presents new challenges in distinguishing one from the other a task further complicated by the frequent updates and closed nature of leading proprietary LLMs. Traditional logits-based detection methods leverage surrogate models for identifying LLM-generated content when the exact logits are unavailable from black-box LLMs. However, these methods grapple with the misalignment between the distributions of the surrogate and the often undisclosed target models, leading to performance degradation, particularly with the introduction of new, closed-source models. Furthermore, while current methodologies are generally effective when the source model is identified, they falter in scenarios where the model version remains unknown, or the test set comprises outputs from various source models. To address these limitations, we present Distribution-Aligned LLMs Detection (DALD), an innovative framework that redefines the state-of-the-art performance in black-box text detection even without logits from source LLMs. DALD is designed to align the surrogate model's distribution with that of unknown target LLMs, ensuring enhanced detection capability and resilience against rapid model iterations with minimal training investment. By leveraging corpus samples from publicly accessible outputs of advanced models such as ChatGPT, GPT-4 and Claude-3, DALD fine-tunes surrogate models to synchronize with unknown source model distributions effectively.