 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile-MMLU: A Mobile Intelligence Language Understanding Benchmark
Mar 26, 2025
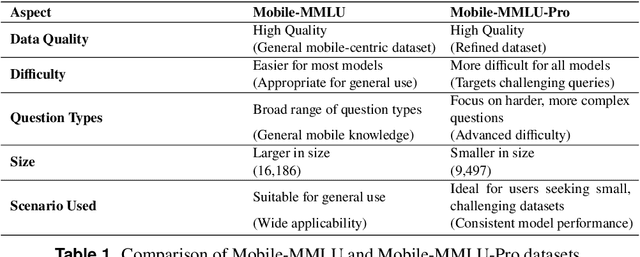

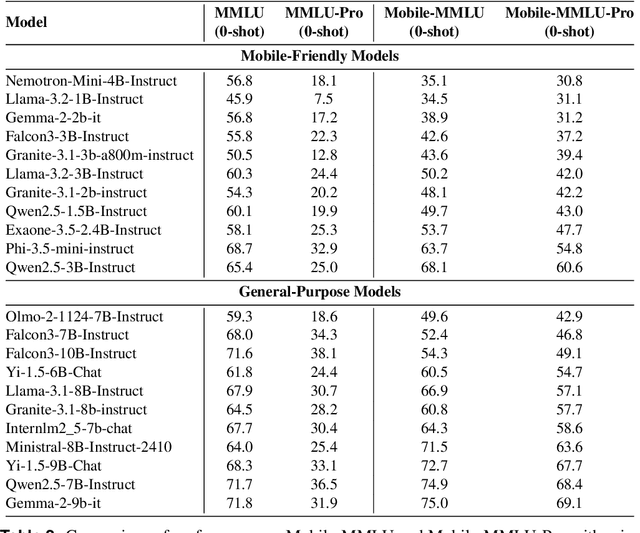
Rapid advancements in large language models (LLMs) have increased interest in deploying them on mobile devices for on-device AI applications. Mobile users interact differently with LLMs compared to desktop users, creating unique expectations and data biases. Current benchmark datasets primarily target at server and desktop environments, and there is a notable lack of extensive datasets specifically designed for mobile contexts. Additionally, mobile devices face strict limitations in storage and computing resources, constraining model size and capabilities, thus requiring optimized efficiency and prioritized knowledge. To address these challenges, we introduce Mobile-MMLU, a large-scale benchmark dataset tailored for mobile intelligence. It consists of 16,186 questions across 80 mobile-related fields, designed to evaluate LLM performance in realistic mobile scenarios. A challenging subset, Mobile-MMLU-Pro, provides advanced evaluation similar in size to MMLU-Pro but significantly more difficult than our standard full set. Both benchmarks use multiple-choice, order-invariant questions focused on practical mobile interactions, such as recipe suggestions, travel planning, and essential daily tasks. The dataset emphasizes critical mobile-specific metrics like inference latency, energy consumption, memory usage, and response quality, offering comprehensive insights into model performance under mobile constraints. Moreover, it prioritizes privacy and adaptability, assessing models' ability to perform on-device processing, maintain user privacy, and adapt to personalized usage patterns. Mobile-MMLU family offers a standardized framework for developing and comparing mobile-optimized LLMs, enabling advancements in productivity and decision-making within mobile computing environments. Our code and data are available at: https://github.com/VILA-Lab/Mobile-MMLU.
Open-LLM-Leaderboard: From Multi-choice to Open-style Questions for LLMs Evaluation, Benchmark, and Arena
Jun 11, 2024



Multiple-choice questions (MCQ) are frequently used to assess large language models (LLMs). Typically, an LLM is given a question and selects the answer deemed most probable after adjustments for factors like length. Unfortunately, LLMs may inherently favor certain answer choice IDs, such as A/B/C/D, due to inherent biases of priori unbalanced probabilities, influencing the prediction of answers based on these IDs. Previous research has introduced methods to reduce this ''selection bias'' by simply permutating options on a few test samples and applying to new ones. Another problem of MCQ is the lottery ticket choice by ''random guessing''. The LLM does not learn particular knowledge, but the option is guessed correctly. This situation is especially serious for those small-scale LLMs. To address them, a more thorough approach involves shifting from MCQ to open-style questions, which can fundamentally eliminate selection bias and random guessing issues. However, transitioning causes its own set of challenges in (1) identifying suitable open-style questions and (2) validating the correctness of LLM open-style responses against human-annotated ground-truths. This work aims to tackle these significant difficulties, and establish a new LLM evaluation benchmark through entirely open-style questions. Consequently, we introduce the Open-LLM-Leaderboard to track various LLMs' performance and reflect true capability of them, such as GPT-4o/4/3.5, Claude 3, Gemini, etc. Our code and dataset are available at https://github.com/VILA-Lab/Open-LLM-Leaderboard.
Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4
Dec 26, 2023



This paper introduces 26 guiding principles designed to streamline the process of querying and prompting large language models. Our goal is to simplify the underlying concepts of formulating questions for various scales of large language models, examining their abilities, and enhancing user comprehension on the behaviors of different scales of large language models when feeding into different prompts. Extensive experiments are conducted on LLaMA-1/2 (7B, 13B and 70B), GPT-3.5/4 to verify the effectiveness of the proposed principles on instructions and prompts design. We hope that this work provides a better guide for researchers working on the prompting of large language models. Project page is available at https://github.com/VILA-Lab/ATLAS.