 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Poisoning Attack Against Reinforcement Learning under Black-box Environments
Paper and Code
Dec 01, 2024
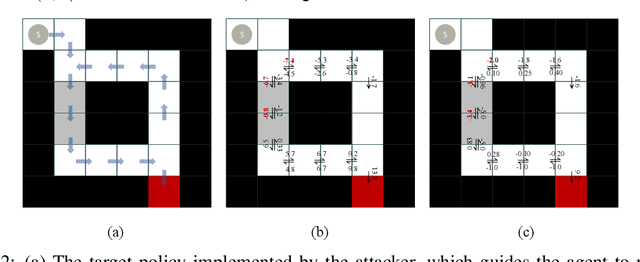
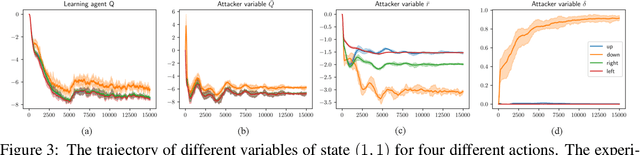
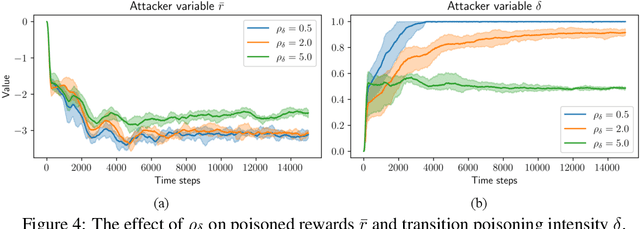
This paper proposes an online environment poisoning algorithm tailored for reinforcement learning agents operating in a black-box setting, where an adversary deliberately manipulates training data to lead the agent toward a mischievous policy. In contrast to prior studies that primarily investigate white-box settings, we focus on a scenario characterized by \textit{unknown} environment dynamics to the attacker and a \textit{flexible} reinforcement learning algorithm employed by the targeted agent. We first propose an attack scheme that is capable of poisoning the reward functions and state transitions. The poisoning task is formalized as a constrained optimization problem, following the framework of \cite{ma2019policy}. Given the transition probabilities are unknown to the attacker in a black-box environment, we apply a stochastic gradient descent algorithm, where the exact gradients are approximated using sample-based estimates. A penalty-based method along with a bilevel reformulation is then employed to transform the problem into an unconstrained counterpart and to circumvent the double-sampling issue. The algorithm's effectiveness is validated through a maze environment.