 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Decoder Attention Network with Contour-weighted Loss Function for Data-Imbalance Medical Image Segmentation
Jan 20, 2026Image segmentation is pivotal in medical image analysis, facilitating clinical diagnosis, treatment planning, and disease evaluation. Deep learning has significantly advanced automatic segmentation methodologies by providing superior modeling capability for complex structures and fine-grained anatomical regions. However, medical images often suffer from data imbalance issues, such as large volume disparities among organs or tissues, and uneven sample distributions across different anatomical structures. This imbalance tends to bias the model toward larger organs or more frequently represented structures, while overlooking smaller or less represented structures, thereby affecting the segmentation accuracy and robustness. To address these challenges, we proposed a novel contour-weighted segmentation approach, which improves the model's capability to represent small and underrepresented structures. We developed PDANet, a lightweight and efficient segmentation network based on a partial decoder mechanism. We evaluated our method using three prominent public datasets. The experimental results show that our methodology excelled in three distinct tasks: segmenting multiple abdominal organs, brain tumors, and pelvic bone fragments with injuries. It consistently outperformed nine state-of-the-art methods. Moreover, the proposed contour-weighted strategy improved segmentation for other comparison methods across the three datasets, yielding average enhancements in Dice scores of 2.32%, 1.67%, and 3.60%, respectively. These results demonstrate that our contour-weighted segmentation method surpassed current leading approaches in both accuracy and robustness. As a model-independent strategy, it can seamlessly fit various segmentation frameworks, enhancing their performance. This flexibility highlighted its practical importance and potential for broad use in medical image analysis.
A Survey on Image Quality Assessment: Insights, Analysis, and Future Outlook
Feb 12, 2025Image quality assessment (IQA) represents a pivotal challenge in image-focused technologies, significantly influencing the advancement trajectory of image processing and computer vision. Recently, IQA has witnessed a notable surge in innovative research efforts, driven by the emergence of novel architectural paradigms and sophisticated computational techniques. This survey delivers an extensive analysis of contemporary IQA methodologies, organized according to their application scenarios, serving as a beneficial reference for both beginners and experienced researchers. We analyze the advantages and limitations of current approaches and suggest potential future research pathways. The survey encompasses both general and specific IQA methodologies, including conventional statistical measures, machine learning techniques, and cutting-edge deep learning models such as convolutional neural networks (CNNs) and Transformer models. The analysis within this survey highlights the necessity for distortion-specific IQA methods tailored to various application scenarios, emphasizing the significance of practicality, interpretability, and ease of implementation in future developments.
3D Brainformer: 3D Fusion Transformer for Brain Tumor Segmentation
Apr 28, 2023



Magnetic resonance imaging (MRI) is critically important for brain mapping in both scientific research and clinical studies. Precise segmentation of brain tumors facilitates clinical diagnosis, evaluations, and surgical planning. Deep learning has recently emerged to improve brain tumor segmentation and achieved impressive results. Convolutional architectures are widely used to implement those neural networks. By the nature of limited receptive fields, however, those architectures are subject to representing long-range spatial dependencies of the voxel intensities in MRI images. Transformers have been leveraged recently to address the above limitations of convolutional networks. Unfortunately, the majority of current Transformers-based methods in segmentation are performed with 2D MRI slices, instead of 3D volumes. Moreover, it is difficult to incorporate the structures between layers because each head is calculated independently in the Multi-Head Self-Attention mechanism (MHSA). In this work, we proposed a 3D Transformer-based segmentation approach. We developed a Fusion-Head Self-Attention mechanism (FHSA) to combine each attention head through attention logic and weight mapping, for the exploration of the long-range spatial dependencies in 3D MRI images. We implemented a plug-and-play self-attention module, named the Infinite Deformable Fusion Transformer Module (IDFTM), to extract features on any deformable feature maps. We applied our approach to the task of brain tumor segmentation, and assessed it on the public BRATS datasets. The experimental results demonstrated that our proposed approach achieved superior performance, in comparison to several state-of-the-art segmentation methods.
In Defense of Subspace Tracker: Orthogonal Embedding for Visual Tracking
Apr 17, 2022
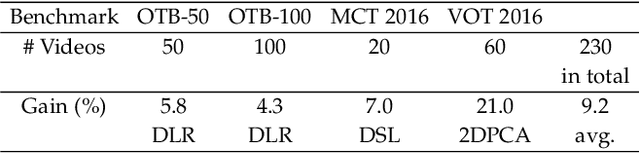
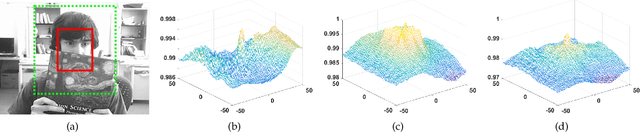
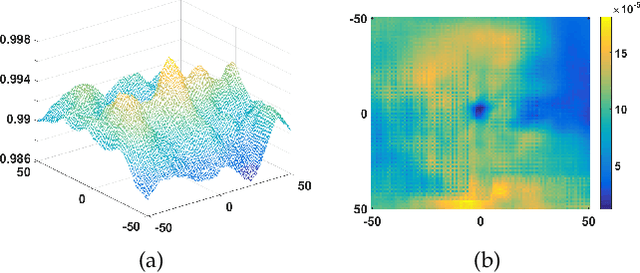
The paper focuses on a classical tracking model, subspace learning, grounded on the fact that the targets in successive frames are considered to reside in a low-dimensional subspace or manifold due to the similarity in their appearances. In recent years, a number of subspace trackers have been proposed and obtained impressive results. Inspired by the most recent results that the tracking performance is boosted by the subspace with discrimination capability learned over the recently localized targets and their immediately surrounding background, this work aims at solving such a problem: how to learn a robust low-dimensional subspace to accurately and discriminatively represent these target and background samples. To this end, a discriminative approach, which reliably separates the target from its surrounding background, is injected into the subspace learning by means of joint learning, achieving a dimension-adaptive subspace with superior discrimination capability. The proposed approach is extensively evaluated and compared with the state-of-the-art trackers on four popular tracking benchmarks. The experimental results demonstrate that the proposed tracker performs competitively against its counterparts. In particular, it achieves more than 9% performance increase compared with the state-of-the-art subspace trackers.
Vision-based Real-Time Aerial Object Localization and Tracking for UAV Sensing System
Mar 19, 2017
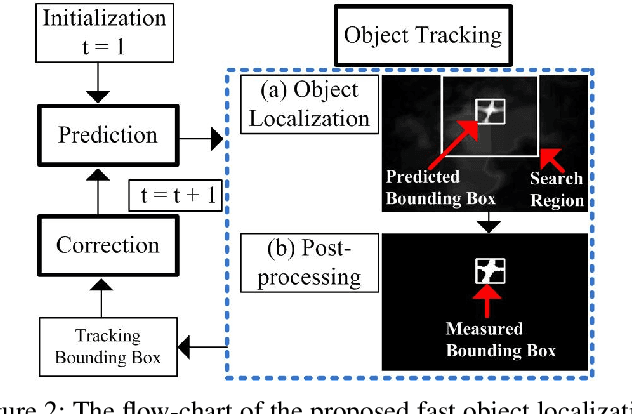

The paper focuses on the problem of vision-based obstacle detection and tracking for unmanned aerial vehicle navigation. A real-time object localization and tracking strategy from monocular image sequences is developed by effectively integrating the object detection and tracking into a dynamic Kalman model. At the detection stage, the object of interest is automatically detected and localized from a saliency map computed via the image background connectivity cue at each frame; at the tracking stage, a Kalman filter is employed to provide a coarse prediction of the object state, which is further refined via a local detector incorporating the saliency map and the temporal information between two consecutive frames. Compared to existing methods, the proposed approach does not require any manual initialization for tracking, runs much faster than the state-of-the-art trackers of its kind, and achieves competitive tracking performance on a large number of image sequences. Extensive experiments demonstrate the effectiveness and superior performance of the proposed approach.
Real-Time Visual Tracking: Promoting the Robustness of Correlation Filter Learning
Sep 09, 2016
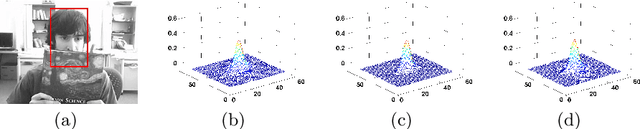
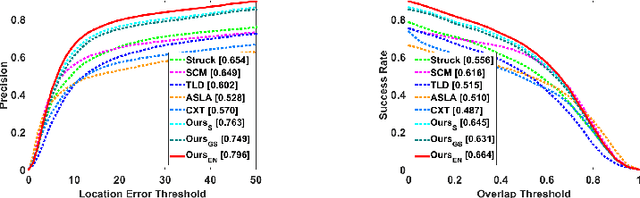
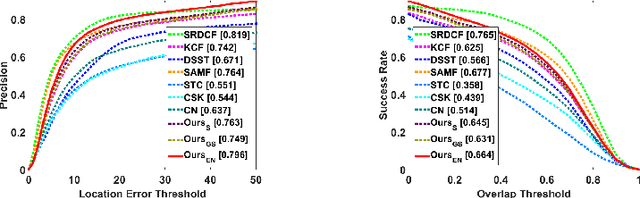
Correlation filtering based tracking model has received lots of attention and achieved great success in real-time tracking, however, the lost function in current correlation filtering paradigm could not reliably response to the appearance changes caused by occlusion and illumination variations. This study intends to promote the robustness of the correlation filter learning. By exploiting the anisotropy of the filter response, three sparsity related loss functions are proposed to alleviate the overfitting issue of previous methods and improve the overall tracking performance. As a result, three real-time trackers are implemented. Extensive experiments in various challenging situations demonstrate that the robustness of the learned correlation filter has been greatly improved via the designed loss functions. In addition, the study reveals, from an experimental perspective, how different loss functions essentially influence the tracking performance. An important conclusion is that the sensitivity of the peak values of the filter in successive frames is consistent with the tracking performance. This is a useful reference criterion in designing a robust correlation filter for visual tracking.
Tracking Completion
Sep 09, 2016


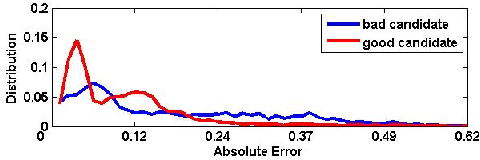
A fundamental component of modern trackers is an online learned tracking model, which is typically modeled either globally or locally. The two kinds of models perform differently in terms of effectiveness and robustness under different challenging situations. This work exploits the advantages of both models. A subspace model, from a global perspective, is learned from previously obtained targets via rank-minimization to address the tracking, and a pixel-level local observation is leveraged si- multaneously, from a local point of view, to augment the subspace model. A matrix completion method is employed to integrate the two models. Unlike previous tracking methods, which locate the target among all fully observed target candidates, the proposed approach first estimates an expected target via the matrix completion through partially observed target candidates, and then, identifies the target according to the estimation accuracy with respect to the target candidates. Specifically, the tracking is formulated as a problem of target appearance estimation. Extensive experiments on various challenging video sequences verify the effectiveness of the proposed approach and demonstrate that the proposed tracker outperforms other popular state-of-the-art trackers.