 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Fusion-Enhanced Decision Transformer for Stable Cross-Domain Generalization
Nov 12, 2025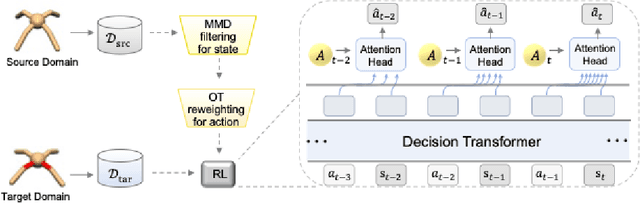
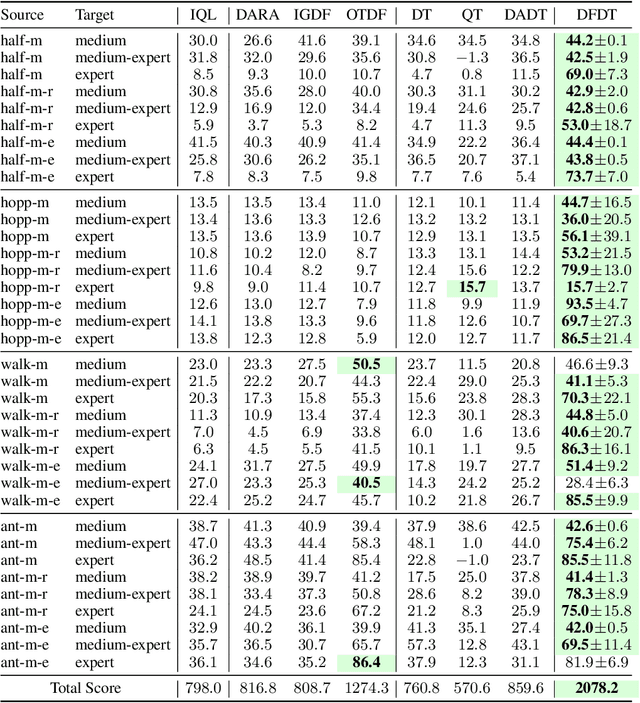
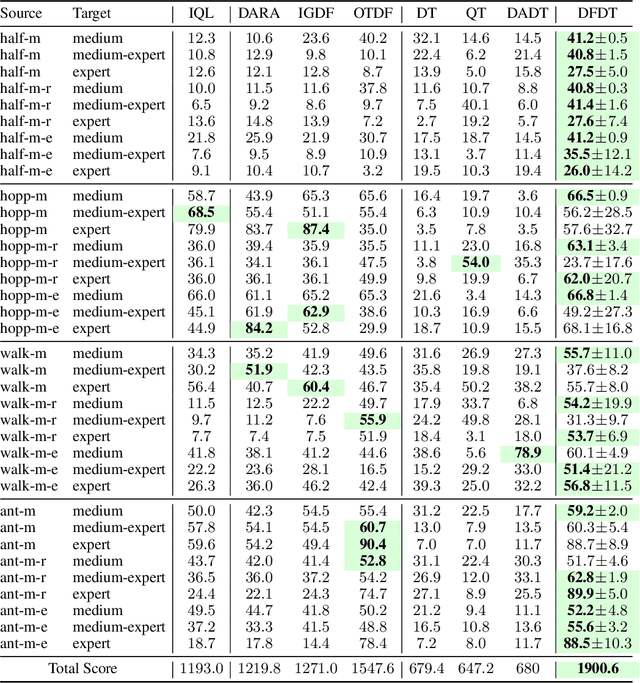
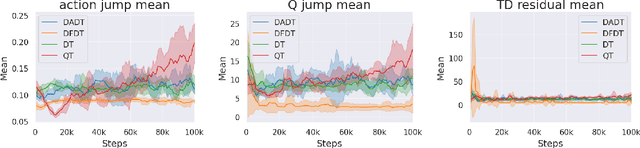
Cross-domain shifts present a significant challenge for decision transformer (DT) policies. Existing cross-domain policy adaptation methods typically rely on a single simple filtering criterion to select source trajectory fragments and stitch them together. They match either state structure or action feasibility. However, the selected fragments still have poor stitchability: state structures can misalign, the return-to-go (RTG) becomes incomparable when the reward or horizon changes, and actions may jump at trajectory junctions. As a result, RTG tokens lose continuity, which compromises DT's inference ability. To tackle these challenges, we propose Data Fusion-Enhanced Decision Transformer (DFDT), a compact pipeline that restores stitchability. Particularly, DFDT fuses scarce target data with selectively trusted source fragments via a two-level data filter, maximum mean discrepancy (MMD) mismatch for state-structure alignment, and optimal transport (OT) deviation for action feasibility. It then trains on a feasibility-weighted fusion distribution. Furthermore, DFDT replaces RTG tokens with advantage-conditioned tokens, which improves the continuity of the semantics in the token sequence. It also applies a $Q$-guided regularizer to suppress junction value and action jumps. Theoretically, we provide bounds that tie state value and policy performance gaps to the MMD-mismatch and OT-deviation measures, and show that the bounds tighten as these two measures shrink. We show that DFDT improves return and stability over strong offline RL and sequence-model baselines across gravity, kinematic, and morphology shifts on D4RL-style control tasks, and further corroborate these gains with token-stitching and sequence-semantics stability analyses.
VIPO: Value Function Inconsistency Penalized Offline Reinforcement Learning
Apr 16, 2025



Offline reinforcement learning (RL) learns effective policies from pre-collected datasets, offering a practical solution for applications where online interactions are risky or costly. Model-based approaches are particularly advantageous for offline RL, owing to their data efficiency and generalizability. However, due to inherent model errors, model-based methods often artificially introduce conservatism guided by heuristic uncertainty estimation, which can be unreliable. In this paper, we introduce VIPO, a novel model-based offline RL algorithm that incorporates self-supervised feedback from value estimation to enhance model training. Specifically, the model is learned by additionally minimizing the inconsistency between the value learned directly from the offline data and the one estimated from the model. We perform comprehensive evaluations from multiple perspectives to show that VIPO can learn a highly accurate model efficiently and consistently outperform existing methods. It offers a general framework that can be readily integrated into existing model-based offline RL algorithms to systematically enhance model accuracy. As a result, VIPO achieves state-of-the-art performance on almost all tasks in both D4RL and NeoRL benchmarks.
Preference-Guided Reinforcement Learning for Efficient Exploration
Jul 09, 2024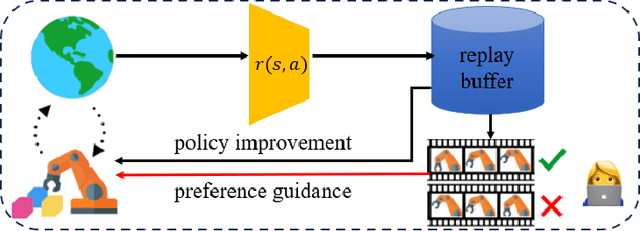
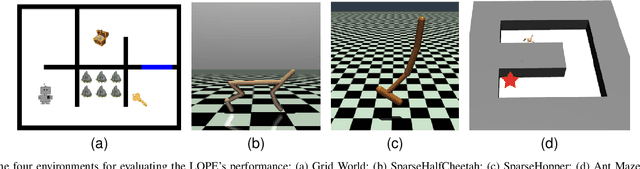
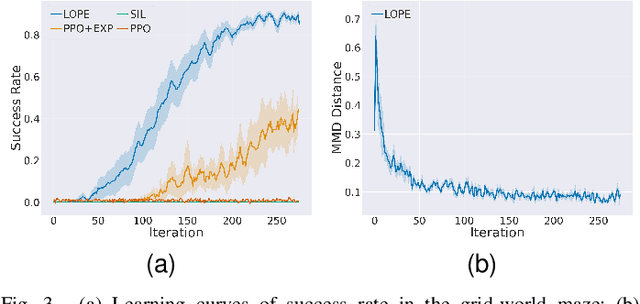
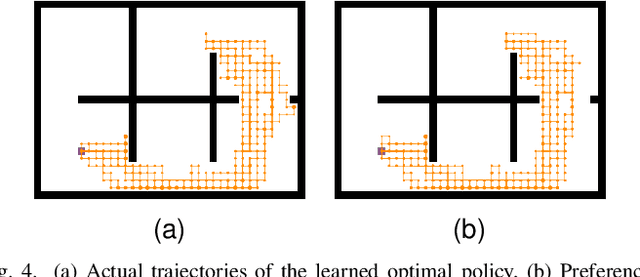
In this paper, we investigate preference-based reinforcement learning (PbRL) that allows reinforcement learning (RL) agents to learn from human feedback. This is particularly valuable when defining a fine-grain reward function is not feasible. However, this approach is inefficient and impractical for promoting deep exploration in hard-exploration tasks with long horizons and sparse rewards. To tackle this issue, we introduce LOPE: Learning Online with trajectory Preference guidancE, an end-to-end preference-guided RL framework that enhances exploration efficiency in hard-exploration tasks. Our intuition is that LOPE directly adjusts the focus of online exploration by considering human feedback as guidance, avoiding learning a separate reward model from preferences. Specifically, LOPE includes a two-step sequential policy optimization process consisting of trust-region-based policy improvement and preference guidance steps. We reformulate preference guidance as a novel trajectory-wise state marginal matching problem that minimizes the maximum mean discrepancy distance between the preferred trajectories and the learned policy. Furthermore, we provide a theoretical analysis to characterize the performance improvement bound and evaluate the LOPE's effectiveness. When assessed in various challenging hard-exploration environments, LOPE outperforms several state-of-the-art methods regarding convergence rate and overall performance. The code used in this study is available at \url{https://github.com/buaawgj/LOPE}.
Learning Diverse Policies with Soft Self-Generated Guidance
Feb 07, 2024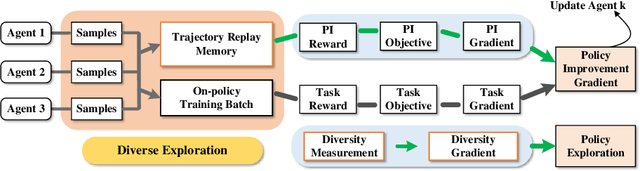


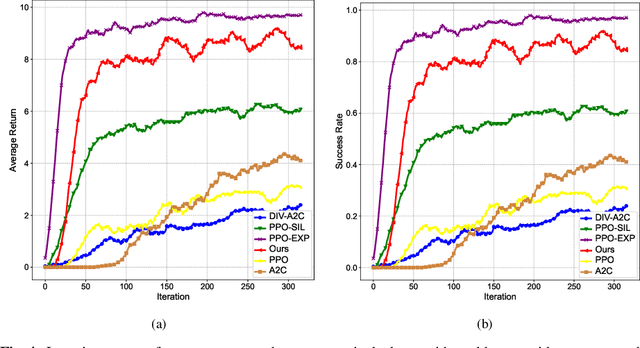
Reinforcement learning (RL) with sparse and deceptive rewards is challenging because non-zero rewards are rarely obtained. Hence, the gradient calculated by the agent can be stochastic and without valid information. Recent studies that utilize memory buffers of previous experiences can lead to a more efficient learning process. However, existing methods often require these experiences to be successful and may overly exploit them, which can cause the agent to adopt suboptimal behaviors. This paper develops an approach that uses diverse past trajectories for faster and more efficient online RL, even if these trajectories are suboptimal or not highly rewarded. The proposed algorithm combines a policy improvement step with an additional exploration step using offline demonstration data. The main contribution of this paper is that by regarding diverse past trajectories as guidance, instead of imitating them, our method directs its policy to follow and expand past trajectories while still being able to learn without rewards and approach optimality. Furthermore, a novel diversity measurement is introduced to maintain the team's diversity and regulate exploration. The proposed algorithm is evaluated on discrete and continuous control tasks with sparse and deceptive rewards. Compared with the existing RL methods, the experimental results indicate that our proposed algorithm is significantly better than the baseline methods regarding diverse exploration and avoiding local optima.
* 23 pages, 19 figures
Trajectory-Oriented Policy Optimization with Sparse Rewards
Jan 04, 2024
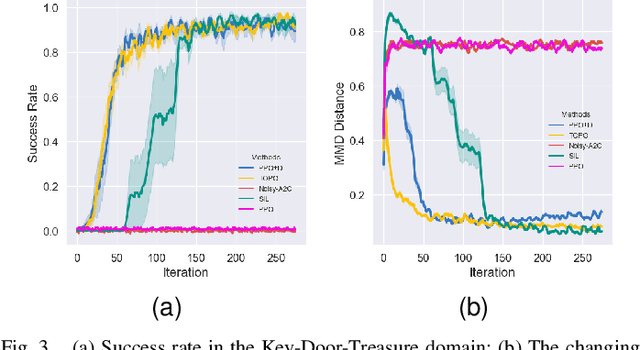
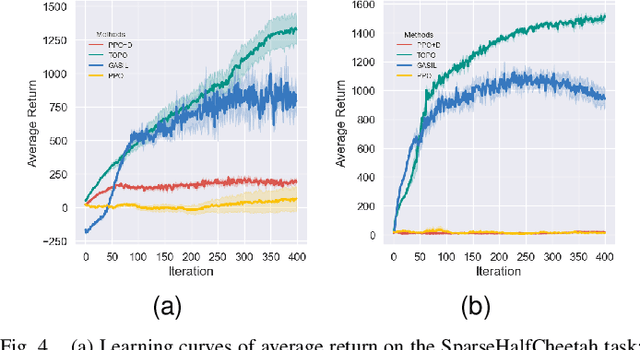
Deep reinforcement learning (DRL) remains challenging in tasks with sparse rewards. These sparse rewards often only indicate whether the task is partially or fully completed, meaning that many exploration actions must be performed before the agent obtains useful feedback. Hence, most existing DRL algorithms fail to learn feasible policies within a reasonable time frame. To overcome this problem, we develop an approach that exploits offline demonstration trajectories for faster and more efficient online RL in sparse reward settings. Our key insight is that by regarding offline demonstration trajectories as guidance, instead of imitating them, our method learns a policy whose state-action visitation marginal distribution matches that of offline demonstrations. Specifically, we introduce a novel trajectory distance based on maximum mean discrepancy (MMD) and formulate policy optimization as a distance-constrained optimization problem. Then, we show that this distance-constrained optimization problem can be reduced into a policy-gradient algorithm with shaped rewards learned from offline demonstrations. The proposed algorithm is evaluated on extensive discrete and continuous control tasks with sparse and deceptive rewards. The experimental results indicate that our proposed algorithm is significantly better than the baseline methods regarding diverse exploration and learning the optimal policy.
Policy Optimization with Smooth Guidance Rewards Learned from Sparse-Reward Demonstrations
Dec 30, 2023
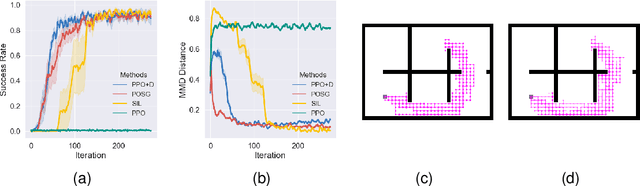
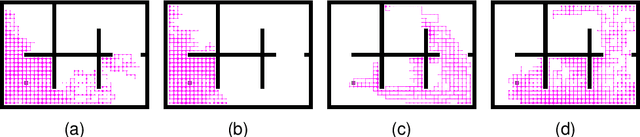
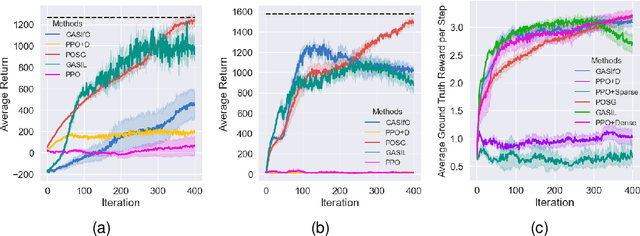
The sparsity of reward feedback remains a challenging problem in online deep reinforcement learning (DRL). Previous approaches have utilized temporal credit assignment (CA) to achieve impressive results in multiple hard tasks. However, many CA methods relied on complex architectures or introduced sensitive hyperparameters to estimate the impact of state-action pairs. Meanwhile, the premise of the feasibility of CA methods is to obtain trajectories with sparse rewards, which can be troublesome in sparse-reward environments with large state spaces. To tackle these problems, we propose a simple and efficient algorithm called Policy Optimization with Smooth Guidance (POSG) that leverages a small set of sparse-reward demonstrations to make reliable and effective long-term credit assignments while efficiently facilitating exploration. The key idea is that the relative impact of state-action pairs can be indirectly estimated using offline demonstrations rather than directly leveraging the sparse reward trajectories generated by the agent. Specifically, we first obtain the trajectory importance by considering both the trajectory-level distance to demonstrations and the returns of the relevant trajectories. Then, the guidance reward is calculated for each state-action pair by smoothly averaging the importance of the trajectories through it, merging the demonstration's distribution and reward information. We theoretically analyze the performance improvement bound caused by smooth guidance rewards and derive a new worst-case lower bound on the performance improvement. Extensive results demonstrate POSG's significant advantages in control performance and convergence speed compared to benchmark DRL algorithms. Notably, the specific metrics and quantifiable results are investigated to demonstrate the superiority of POSG.
Adaptive trajectory-constrained exploration strategy for deep reinforcement learning
Dec 27, 2023
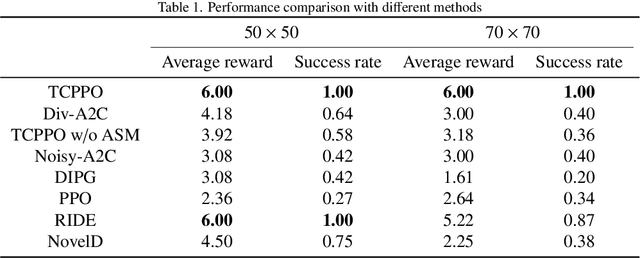


Deep reinforcement learning (DRL) faces significant challenges in addressing the hard-exploration problems in tasks with sparse or deceptive rewards and large state spaces. These challenges severely limit the practical application of DRL. Most previous exploration methods relied on complex architectures to estimate state novelty or introduced sensitive hyperparameters, resulting in instability. To mitigate these issues, we propose an efficient adaptive trajectory-constrained exploration strategy for DRL. The proposed method guides the policy of the agent away from suboptimal solutions by leveraging incomplete offline demonstrations as references. This approach gradually expands the exploration scope of the agent and strives for optimality in a constrained optimization manner. Additionally, we introduce a novel policy-gradient-based optimization algorithm that utilizes adaptively clipped trajectory-distance rewards for both single- and multi-agent reinforcement learning. We provide a theoretical analysis of our method, including a deduction of the worst-case approximation error bounds, highlighting the validity of our approach for enhancing exploration. To evaluate the effectiveness of the proposed method, we conducted experiments on two large 2D grid world mazes and several MuJoCo tasks. The extensive experimental results demonstrate the significant advantages of our method in achieving temporally extended exploration and avoiding myopic and suboptimal behaviors in both single- and multi-agent settings. Notably, the specific metrics and quantifiable results further support these findings. The code used in the study is available at \url{https://github.com/buaawgj/TACE}.
* 35 pages, 36 figures; accepted by Knowledge-Based Systems, not published