 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline RL with Smooth OOD Generalization in Convex Hull and its Neighborhood
Jun 10, 2025Offline Reinforcement Learning (RL) struggles with distributional shifts, leading to the $Q$-value overestimation for out-of-distribution (OOD) actions. Existing methods address this issue by imposing constraints; however, they often become overly conservative when evaluating OOD regions, which constrains the $Q$-function generalization. This over-constraint issue results in poor $Q$-value estimation and hinders policy improvement. In this paper, we introduce a novel approach to achieve better $Q$-value estimation by enhancing $Q$-function generalization in OOD regions within Convex Hull and its Neighborhood (CHN). Under the safety generalization guarantees of the CHN, we propose the Smooth Bellman Operator (SBO), which updates OOD $Q$-values by smoothing them with neighboring in-sample $Q$-values. We theoretically show that SBO approximates true $Q$-values for both in-sample and OOD actions within the CHN. Our practical algorithm, Smooth Q-function OOD Generalization (SQOG), empirically alleviates the over-constraint issue, achieving near-accurate $Q$-value estimation. On the D4RL benchmarks, SQOG outperforms existing state-of-the-art methods in both performance and computational efficiency.
Preference-Guided Reinforcement Learning for Efficient Exploration
Jul 09, 2024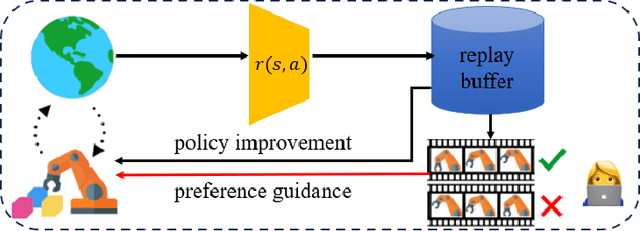
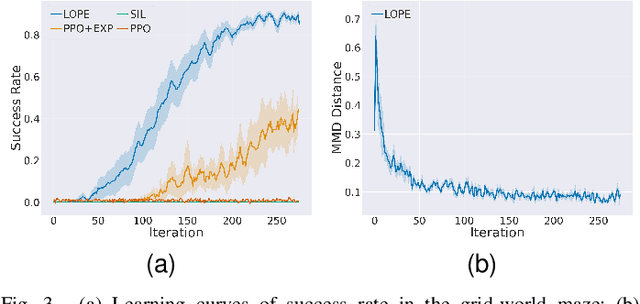
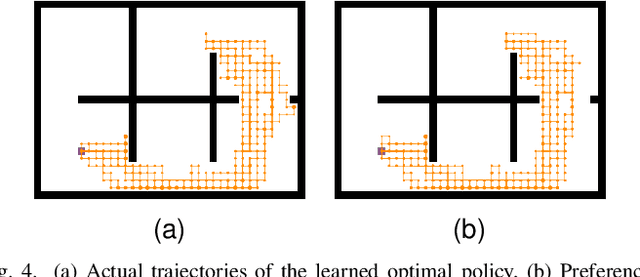
In this paper, we investigate preference-based reinforcement learning (PbRL) that allows reinforcement learning (RL) agents to learn from human feedback. This is particularly valuable when defining a fine-grain reward function is not feasible. However, this approach is inefficient and impractical for promoting deep exploration in hard-exploration tasks with long horizons and sparse rewards. To tackle this issue, we introduce LOPE: Learning Online with trajectory Preference guidancE, an end-to-end preference-guided RL framework that enhances exploration efficiency in hard-exploration tasks. Our intuition is that LOPE directly adjusts the focus of online exploration by considering human feedback as guidance, avoiding learning a separate reward model from preferences. Specifically, LOPE includes a two-step sequential policy optimization process consisting of trust-region-based policy improvement and preference guidance steps. We reformulate preference guidance as a novel trajectory-wise state marginal matching problem that minimizes the maximum mean discrepancy distance between the preferred trajectories and the learned policy. Furthermore, we provide a theoretical analysis to characterize the performance improvement bound and evaluate the LOPE's effectiveness. When assessed in various challenging hard-exploration environments, LOPE outperforms several state-of-the-art methods regarding convergence rate and overall performance. The code used in this study is available at \url{https://github.com/buaawgj/LOPE}.
Policy Optimization with Smooth Guidance Rewards Learned from Sparse-Reward Demonstrations
Dec 30, 2023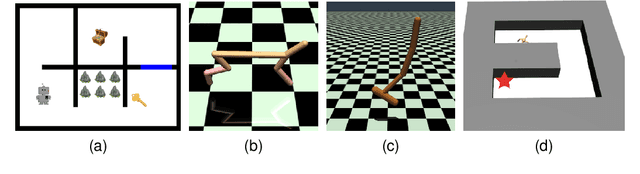
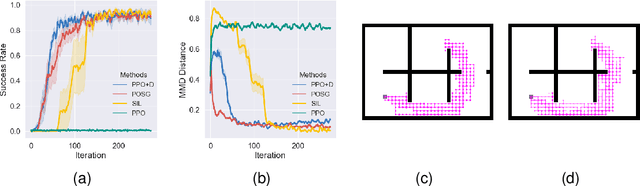
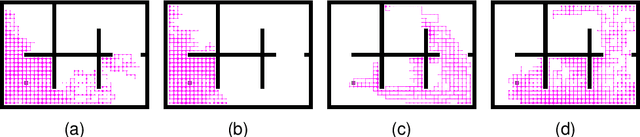
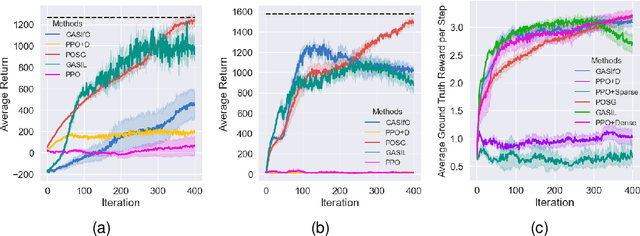
The sparsity of reward feedback remains a challenging problem in online deep reinforcement learning (DRL). Previous approaches have utilized temporal credit assignment (CA) to achieve impressive results in multiple hard tasks. However, many CA methods relied on complex architectures or introduced sensitive hyperparameters to estimate the impact of state-action pairs. Meanwhile, the premise of the feasibility of CA methods is to obtain trajectories with sparse rewards, which can be troublesome in sparse-reward environments with large state spaces. To tackle these problems, we propose a simple and efficient algorithm called Policy Optimization with Smooth Guidance (POSG) that leverages a small set of sparse-reward demonstrations to make reliable and effective long-term credit assignments while efficiently facilitating exploration. The key idea is that the relative impact of state-action pairs can be indirectly estimated using offline demonstrations rather than directly leveraging the sparse reward trajectories generated by the agent. Specifically, we first obtain the trajectory importance by considering both the trajectory-level distance to demonstrations and the returns of the relevant trajectories. Then, the guidance reward is calculated for each state-action pair by smoothly averaging the importance of the trajectories through it, merging the demonstration's distribution and reward information. We theoretically analyze the performance improvement bound caused by smooth guidance rewards and derive a new worst-case lower bound on the performance improvement. Extensive results demonstrate POSG's significant advantages in control performance and convergence speed compared to benchmark DRL algorithms. Notably, the specific metrics and quantifiable results are investigated to demonstrate the superiority of POSG.