 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Optimization with Smooth Guidance Rewards Learned from Sparse-Reward Demonstrations
Paper and Code
Dec 30, 2023
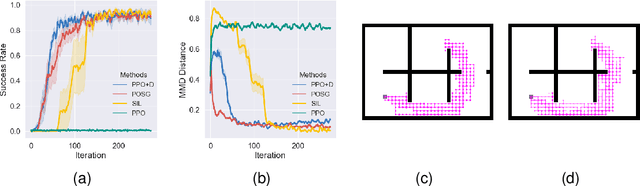
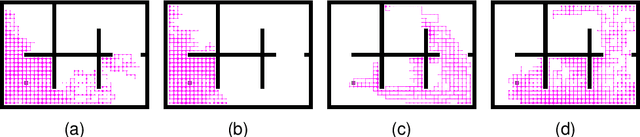
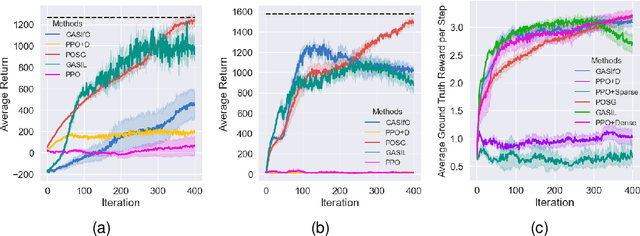
The sparsity of reward feedback remains a challenging problem in online deep reinforcement learning (DRL). Previous approaches have utilized temporal credit assignment (CA) to achieve impressive results in multiple hard tasks. However, many CA methods relied on complex architectures or introduced sensitive hyperparameters to estimate the impact of state-action pairs. Meanwhile, the premise of the feasibility of CA methods is to obtain trajectories with sparse rewards, which can be troublesome in sparse-reward environments with large state spaces. To tackle these problems, we propose a simple and efficient algorithm called Policy Optimization with Smooth Guidance (POSG) that leverages a small set of sparse-reward demonstrations to make reliable and effective long-term credit assignments while efficiently facilitating exploration. The key idea is that the relative impact of state-action pairs can be indirectly estimated using offline demonstrations rather than directly leveraging the sparse reward trajectories generated by the agent. Specifically, we first obtain the trajectory importance by considering both the trajectory-level distance to demonstrations and the returns of the relevant trajectories. Then, the guidance reward is calculated for each state-action pair by smoothly averaging the importance of the trajectories through it, merging the demonstration's distribution and reward information. We theoretically analyze the performance improvement bound caused by smooth guidance rewards and derive a new worst-case lower bound on the performance improvement. Extensive results demonstrate POSG's significant advantages in control performance and convergence speed compared to benchmark DRL algorithms. Notably, the specific metrics and quantifiable results are investigated to demonstrate the superiority of POSG.