 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZ-Erase: Enabling Concept Erasure in Single-Stream Diffusion Transformers
Mar 26, 2026Concept erasure serves as a vital safety mechanism for removing unwanted concepts from text-to-image (T2I) models. While extensively studied in U-Net and dual-stream architectures (e.g., Flux), this task remains under-explored in the recent emerging paradigm of single-stream diffusion transformers (e.g., Z-Image). In this new paradigm, text and image tokens are processed as a single unified sequence via shared parameters. Consequently, directly applying prior erasure methods typically leads to generation collapse. To bridge this gap, we introduce Z-Erase, the first concept erasure method tailored for single-stream T2I models. To guarantee stable image generation, Z-Erase first proposes a Stream Disentangled Concept Erasure Framework that decouples updates and enables existing methods on single-stream models. Subsequently, within this framework, we introduce Lagrangian-Guided Adaptive Erasure Modulation, a constrained algorithm that further balances the sensitive erasure-preservation trade-off. Moreover, we provide a rigorous convergence analysis proving that Z-Erase can converge to a Pareto stationary point. Experiments demonstrate that Z-Erase successfully overcomes the generation collapse issue, achieving state-of-the-art performance across a wide range of tasks.
Towards Compositional Generalization in LLMs for Smart Contract Security: A Case Study on Reentrancy Vulnerabilities
Jan 11, 2026Large language models (LLMs) demonstrate remarkable capabilities in natural language understanding and generation. Despite being trained on large-scale, high-quality data, LLMs still fail to outperform traditional static analysis tools in specialized domains like smart contract vulnerability detection. To address this issue, this paper proposes a post-training algorithm based on atomic task decomposition and fusion. This algorithm aims to achieve combinatorial generalization under limited data by decomposing complex reasoning tasks. Specifically, we decompose the reentrancy vulnerability detection task into four linearly independent atomic tasks: identifying external calls, identifying state updates, identifying data dependencies between external calls and state updates, and determining their data flow order. These tasks form the core components of our approach. By training on synthetic datasets, we generate three compiler-verified datasets. We then employ the Slither tool to extract structural information from the control flow graph and data flow graph, which is used to fine-tune the LLM's adapter. Experimental results demonstrate that low-rank normalization fusion with the LoRA adapter improves the LLM's reentrancy vulnerability detection accuracy to 98.2%, surpassing state-of-the-art methods. On 31 real-world contracts, the algorithm achieves a 20% higher recall than traditional analysis tools.
Offline RL with Smooth OOD Generalization in Convex Hull and its Neighborhood
Jun 10, 2025Offline Reinforcement Learning (RL) struggles with distributional shifts, leading to the $Q$-value overestimation for out-of-distribution (OOD) actions. Existing methods address this issue by imposing constraints; however, they often become overly conservative when evaluating OOD regions, which constrains the $Q$-function generalization. This over-constraint issue results in poor $Q$-value estimation and hinders policy improvement. In this paper, we introduce a novel approach to achieve better $Q$-value estimation by enhancing $Q$-function generalization in OOD regions within Convex Hull and its Neighborhood (CHN). Under the safety generalization guarantees of the CHN, we propose the Smooth Bellman Operator (SBO), which updates OOD $Q$-values by smoothing them with neighboring in-sample $Q$-values. We theoretically show that SBO approximates true $Q$-values for both in-sample and OOD actions within the CHN. Our practical algorithm, Smooth Q-function OOD Generalization (SQOG), empirically alleviates the over-constraint issue, achieving near-accurate $Q$-value estimation. On the D4RL benchmarks, SQOG outperforms existing state-of-the-art methods in both performance and computational efficiency.
Preference-Guided Reinforcement Learning for Efficient Exploration
Jul 09, 2024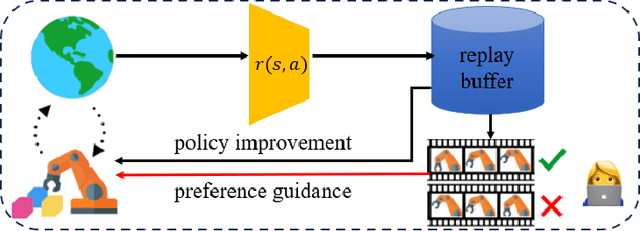
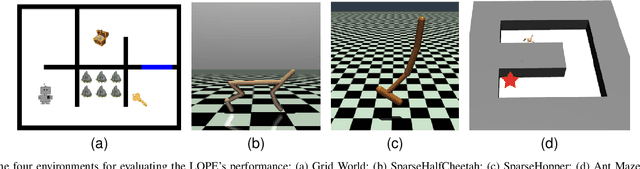
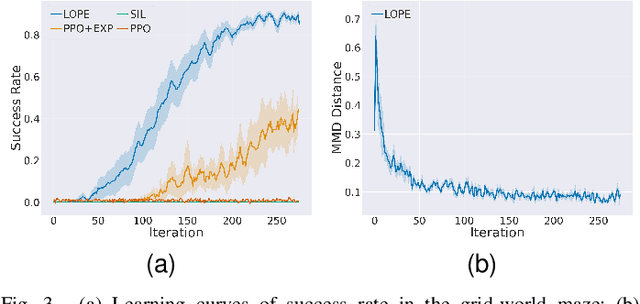
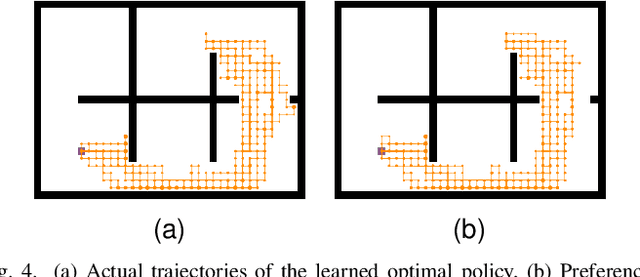
In this paper, we investigate preference-based reinforcement learning (PbRL) that allows reinforcement learning (RL) agents to learn from human feedback. This is particularly valuable when defining a fine-grain reward function is not feasible. However, this approach is inefficient and impractical for promoting deep exploration in hard-exploration tasks with long horizons and sparse rewards. To tackle this issue, we introduce LOPE: Learning Online with trajectory Preference guidancE, an end-to-end preference-guided RL framework that enhances exploration efficiency in hard-exploration tasks. Our intuition is that LOPE directly adjusts the focus of online exploration by considering human feedback as guidance, avoiding learning a separate reward model from preferences. Specifically, LOPE includes a two-step sequential policy optimization process consisting of trust-region-based policy improvement and preference guidance steps. We reformulate preference guidance as a novel trajectory-wise state marginal matching problem that minimizes the maximum mean discrepancy distance between the preferred trajectories and the learned policy. Furthermore, we provide a theoretical analysis to characterize the performance improvement bound and evaluate the LOPE's effectiveness. When assessed in various challenging hard-exploration environments, LOPE outperforms several state-of-the-art methods regarding convergence rate and overall performance. The code used in this study is available at \url{https://github.com/buaawgj/LOPE}.
Learning Diverse Policies with Soft Self-Generated Guidance
Feb 07, 2024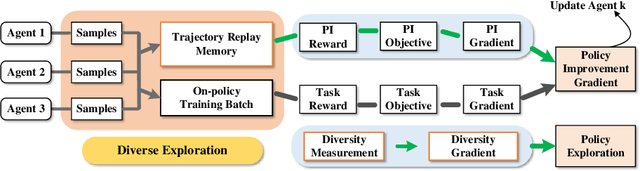


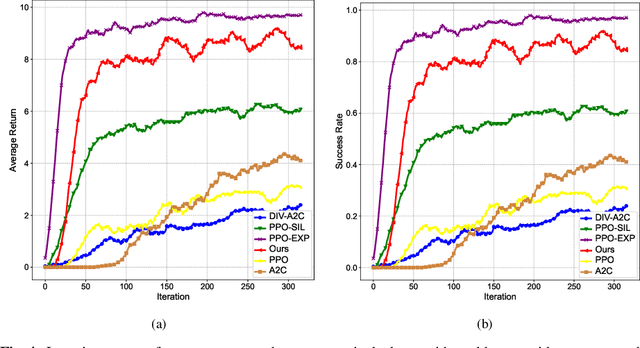
Reinforcement learning (RL) with sparse and deceptive rewards is challenging because non-zero rewards are rarely obtained. Hence, the gradient calculated by the agent can be stochastic and without valid information. Recent studies that utilize memory buffers of previous experiences can lead to a more efficient learning process. However, existing methods often require these experiences to be successful and may overly exploit them, which can cause the agent to adopt suboptimal behaviors. This paper develops an approach that uses diverse past trajectories for faster and more efficient online RL, even if these trajectories are suboptimal or not highly rewarded. The proposed algorithm combines a policy improvement step with an additional exploration step using offline demonstration data. The main contribution of this paper is that by regarding diverse past trajectories as guidance, instead of imitating them, our method directs its policy to follow and expand past trajectories while still being able to learn without rewards and approach optimality. Furthermore, a novel diversity measurement is introduced to maintain the team's diversity and regulate exploration. The proposed algorithm is evaluated on discrete and continuous control tasks with sparse and deceptive rewards. Compared with the existing RL methods, the experimental results indicate that our proposed algorithm is significantly better than the baseline methods regarding diverse exploration and avoiding local optima.
* 23 pages, 19 figures
Trajectory-Oriented Policy Optimization with Sparse Rewards
Jan 04, 2024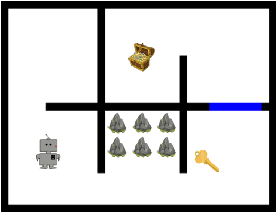
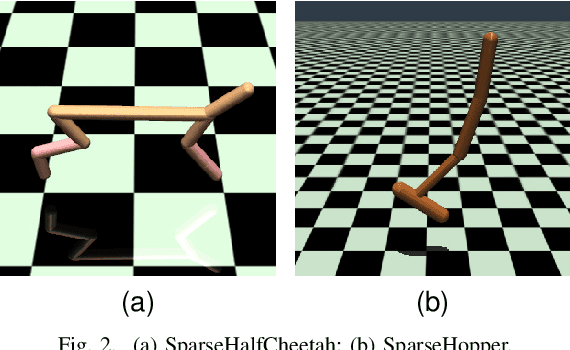
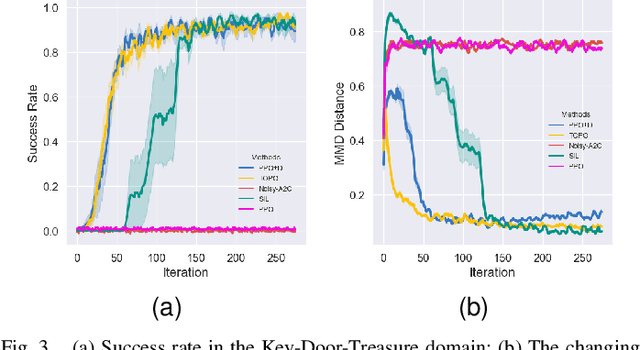
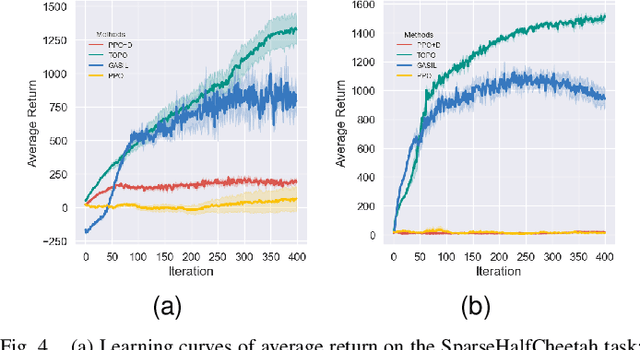
Deep reinforcement learning (DRL) remains challenging in tasks with sparse rewards. These sparse rewards often only indicate whether the task is partially or fully completed, meaning that many exploration actions must be performed before the agent obtains useful feedback. Hence, most existing DRL algorithms fail to learn feasible policies within a reasonable time frame. To overcome this problem, we develop an approach that exploits offline demonstration trajectories for faster and more efficient online RL in sparse reward settings. Our key insight is that by regarding offline demonstration trajectories as guidance, instead of imitating them, our method learns a policy whose state-action visitation marginal distribution matches that of offline demonstrations. Specifically, we introduce a novel trajectory distance based on maximum mean discrepancy (MMD) and formulate policy optimization as a distance-constrained optimization problem. Then, we show that this distance-constrained optimization problem can be reduced into a policy-gradient algorithm with shaped rewards learned from offline demonstrations. The proposed algorithm is evaluated on extensive discrete and continuous control tasks with sparse and deceptive rewards. The experimental results indicate that our proposed algorithm is significantly better than the baseline methods regarding diverse exploration and learning the optimal policy.
Policy Optimization with Smooth Guidance Rewards Learned from Sparse-Reward Demonstrations
Dec 30, 2023
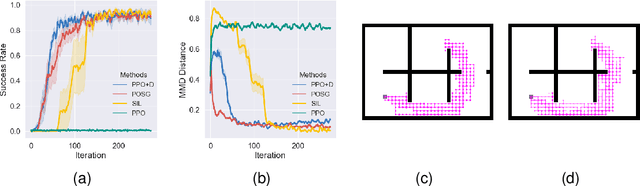
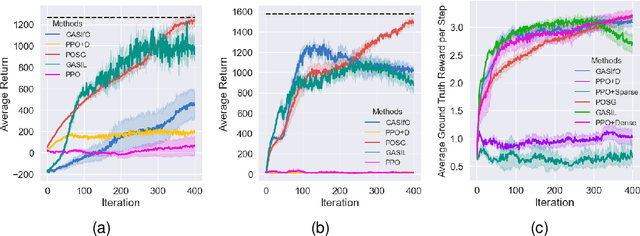
The sparsity of reward feedback remains a challenging problem in online deep reinforcement learning (DRL). Previous approaches have utilized temporal credit assignment (CA) to achieve impressive results in multiple hard tasks. However, many CA methods relied on complex architectures or introduced sensitive hyperparameters to estimate the impact of state-action pairs. Meanwhile, the premise of the feasibility of CA methods is to obtain trajectories with sparse rewards, which can be troublesome in sparse-reward environments with large state spaces. To tackle these problems, we propose a simple and efficient algorithm called Policy Optimization with Smooth Guidance (POSG) that leverages a small set of sparse-reward demonstrations to make reliable and effective long-term credit assignments while efficiently facilitating exploration. The key idea is that the relative impact of state-action pairs can be indirectly estimated using offline demonstrations rather than directly leveraging the sparse reward trajectories generated by the agent. Specifically, we first obtain the trajectory importance by considering both the trajectory-level distance to demonstrations and the returns of the relevant trajectories. Then, the guidance reward is calculated for each state-action pair by smoothly averaging the importance of the trajectories through it, merging the demonstration's distribution and reward information. We theoretically analyze the performance improvement bound caused by smooth guidance rewards and derive a new worst-case lower bound on the performance improvement. Extensive results demonstrate POSG's significant advantages in control performance and convergence speed compared to benchmark DRL algorithms. Notably, the specific metrics and quantifiable results are investigated to demonstrate the superiority of POSG.
Adaptive trajectory-constrained exploration strategy for deep reinforcement learning
Dec 27, 2023


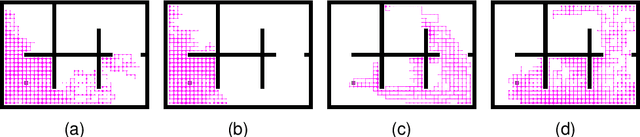
Deep reinforcement learning (DRL) faces significant challenges in addressing the hard-exploration problems in tasks with sparse or deceptive rewards and large state spaces. These challenges severely limit the practical application of DRL. Most previous exploration methods relied on complex architectures to estimate state novelty or introduced sensitive hyperparameters, resulting in instability. To mitigate these issues, we propose an efficient adaptive trajectory-constrained exploration strategy for DRL. The proposed method guides the policy of the agent away from suboptimal solutions by leveraging incomplete offline demonstrations as references. This approach gradually expands the exploration scope of the agent and strives for optimality in a constrained optimization manner. Additionally, we introduce a novel policy-gradient-based optimization algorithm that utilizes adaptively clipped trajectory-distance rewards for both single- and multi-agent reinforcement learning. We provide a theoretical analysis of our method, including a deduction of the worst-case approximation error bounds, highlighting the validity of our approach for enhancing exploration. To evaluate the effectiveness of the proposed method, we conducted experiments on two large 2D grid world mazes and several MuJoCo tasks. The extensive experimental results demonstrate the significant advantages of our method in achieving temporally extended exploration and avoiding myopic and suboptimal behaviors in both single- and multi-agent settings. Notably, the specific metrics and quantifiable results further support these findings. The code used in the study is available at \url{https://github.com/buaawgj/TACE}.
* 35 pages, 36 figures; accepted by Knowledge-Based Systems, not published
PINF: Continuous Normalizing Flows for Physics-Constrained Deep Learning
Sep 26, 2023The normalization constraint on probability density poses a significant challenge for solving the Fokker-Planck equation. Normalizing Flow, an invertible generative model leverages the change of variables formula to ensure probability density conservation and enable the learning of complex data distributions. In this paper, we introduce Physics-Informed Normalizing Flows (PINF), a novel extension of continuous normalizing flows, incorporating diffusion through the method of characteristics. Our method, which is mesh-free and causality-free, can efficiently solve high dimensional time-dependent and steady-state Fokker-Planck equations.