 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline RL with Smooth OOD Generalization in Convex Hull and its Neighborhood
Jun 10, 2025Offline Reinforcement Learning (RL) struggles with distributional shifts, leading to the $Q$-value overestimation for out-of-distribution (OOD) actions. Existing methods address this issue by imposing constraints; however, they often become overly conservative when evaluating OOD regions, which constrains the $Q$-function generalization. This over-constraint issue results in poor $Q$-value estimation and hinders policy improvement. In this paper, we introduce a novel approach to achieve better $Q$-value estimation by enhancing $Q$-function generalization in OOD regions within Convex Hull and its Neighborhood (CHN). Under the safety generalization guarantees of the CHN, we propose the Smooth Bellman Operator (SBO), which updates OOD $Q$-values by smoothing them with neighboring in-sample $Q$-values. We theoretically show that SBO approximates true $Q$-values for both in-sample and OOD actions within the CHN. Our practical algorithm, Smooth Q-function OOD Generalization (SQOG), empirically alleviates the over-constraint issue, achieving near-accurate $Q$-value estimation. On the D4RL benchmarks, SQOG outperforms existing state-of-the-art methods in both performance and computational efficiency.
Learning Diverse Policies with Soft Self-Generated Guidance
Feb 07, 2024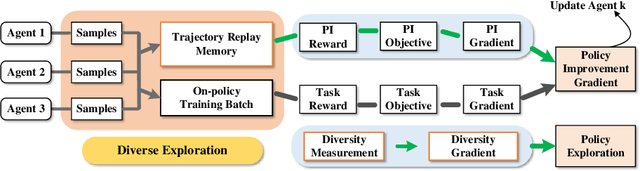


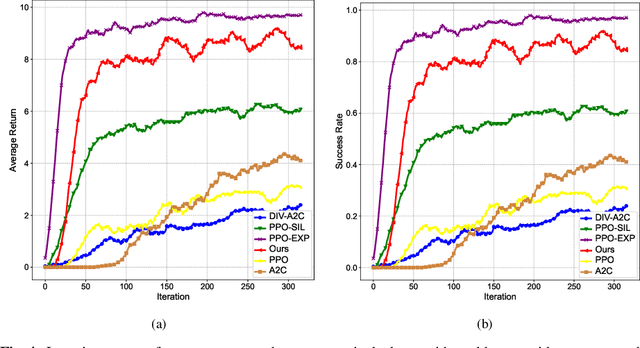
Reinforcement learning (RL) with sparse and deceptive rewards is challenging because non-zero rewards are rarely obtained. Hence, the gradient calculated by the agent can be stochastic and without valid information. Recent studies that utilize memory buffers of previous experiences can lead to a more efficient learning process. However, existing methods often require these experiences to be successful and may overly exploit them, which can cause the agent to adopt suboptimal behaviors. This paper develops an approach that uses diverse past trajectories for faster and more efficient online RL, even if these trajectories are suboptimal or not highly rewarded. The proposed algorithm combines a policy improvement step with an additional exploration step using offline demonstration data. The main contribution of this paper is that by regarding diverse past trajectories as guidance, instead of imitating them, our method directs its policy to follow and expand past trajectories while still being able to learn without rewards and approach optimality. Furthermore, a novel diversity measurement is introduced to maintain the team's diversity and regulate exploration. The proposed algorithm is evaluated on discrete and continuous control tasks with sparse and deceptive rewards. Compared with the existing RL methods, the experimental results indicate that our proposed algorithm is significantly better than the baseline methods regarding diverse exploration and avoiding local optima.
* 23 pages, 19 figures