 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive trajectory-constrained exploration strategy for deep reinforcement learning
Paper and Code

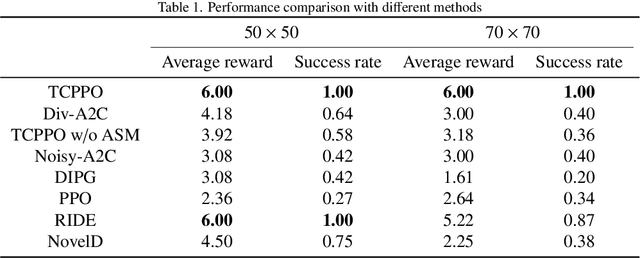


Deep reinforcement learning (DRL) faces significant challenges in addressing the hard-exploration problems in tasks with sparse or deceptive rewards and large state spaces. These challenges severely limit the practical application of DRL. Most previous exploration methods relied on complex architectures to estimate state novelty or introduced sensitive hyperparameters, resulting in instability. To mitigate these issues, we propose an efficient adaptive trajectory-constrained exploration strategy for DRL. The proposed method guides the policy of the agent away from suboptimal solutions by leveraging incomplete offline demonstrations as references. This approach gradually expands the exploration scope of the agent and strives for optimality in a constrained optimization manner. Additionally, we introduce a novel policy-gradient-based optimization algorithm that utilizes adaptively clipped trajectory-distance rewards for both single- and multi-agent reinforcement learning. We provide a theoretical analysis of our method, including a deduction of the worst-case approximation error bounds, highlighting the validity of our approach for enhancing exploration. To evaluate the effectiveness of the proposed method, we conducted experiments on two large 2D grid world mazes and several MuJoCo tasks. The extensive experimental results demonstrate the significant advantages of our method in achieving temporally extended exploration and avoiding myopic and suboptimal behaviors in both single- and multi-agent settings. Notably, the specific metrics and quantifiable results further support these findings. The code used in the study is available at \url{https://github.com/buaawgj/TACE}.