 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerplexity Trap: PLM-Based Retrievers Overrate Low Perplexity Documents
Mar 11, 2025



Previous studies have found that PLM-based retrieval models exhibit a preference for LLM-generated content, assigning higher relevance scores to these documents even when their semantic quality is comparable to human-written ones. This phenomenon, known as source bias, threatens the sustainable development of the information access ecosystem. However, the underlying causes of source bias remain unexplored. In this paper, we explain the process of information retrieval with a causal graph and discover that PLM-based retrievers learn perplexity features for relevance estimation, causing source bias by ranking the documents with low perplexity higher. Theoretical analysis further reveals that the phenomenon stems from the positive correlation between the gradients of the loss functions in language modeling task and retrieval task. Based on the analysis, a causal-inspired inference-time debiasing method is proposed, called Causal Diagnosis and Correction (CDC). CDC first diagnoses the bias effect of the perplexity and then separates the bias effect from the overall estimated relevance score. Experimental results across three domains demonstrate the superior debiasing effectiveness of CDC, emphasizing the validity of our proposed explanatory framework. Source codes are available at https://github.com/WhyDwelledOnAi/Perplexity-Trap.
Inference Computation Scaling for Feature Augmentation in Recommendation Systems
Feb 22, 2025Large language models have become a powerful method for feature augmentation in recommendation systems. However, existing approaches relying on quick inference often suffer from incomplete feature coverage and insufficient specificity in feature descriptions, limiting their ability to capture fine-grained user preferences and undermining overall performance. Motivated by the recent success of inference scaling in math and coding tasks, we explore whether scaling inference can address these limitations and enhance feature quality. Our experiments show that scaling inference leads to significant improvements in recommendation performance, with a 12% increase in NDCG@10. The gains can be attributed to two key factors: feature quantity and specificity. In particular, models using extended Chain-of-Thought (CoT) reasoning generate a greater number of detailed and precise features, offering deeper insights into user preferences and overcoming the limitations of quick inference. We further investigate the factors influencing feature quantity, revealing that model choice and search strategy play critical roles in generating a richer and more diverse feature set. This is the first work to apply inference scaling to feature augmentation in recommendation systems, bridging advances in reasoning tasks to enhance personalized recommendation.
Counteracting Duration Bias in Video Recommendation via Counterfactual Watch Time
Jun 12, 2024



In video recommendation, an ongoing effort is to satisfy users' personalized information needs by leveraging their logged watch time. However, watch time prediction suffers from duration bias, hindering its ability to reflect users' interests accurately. Existing label-correction approaches attempt to uncover user interests through grouping and normalizing observed watch time according to video duration. Although effective to some extent, we found that these approaches regard completely played records (i.e., a user watches the entire video) as equally high interest, which deviates from what we observed on real datasets: users have varied explicit feedback proportion when completely playing videos. In this paper, we introduce the counterfactual watch time(CWT), the potential watch time a user would spend on the video if its duration is sufficiently long. Analysis shows that the duration bias is caused by the truncation of CWT due to the video duration limitation, which usually occurs on those completely played records. Besides, a Counterfactual Watch Model (CWM) is proposed, revealing that CWT equals the time users get the maximum benefit from video recommender systems. Moreover, a cost-based transform function is defined to transform the CWT into the estimation of user interest, and the model can be learned by optimizing a counterfactual likelihood function defined over observed user watch times. Extensive experiments on three real video recommendation datasets and online A/B testing demonstrated that CWM effectively enhanced video recommendation accuracy and counteracted the duration bias.
Uncovering User Interest from Biased and Noised Watch Time in Video Recommendation
Aug 16, 2023



In the video recommendation, watch time is commonly adopted as an indicator of user interest. However, watch time is not only influenced by the matching of users' interests but also by other factors, such as duration bias and noisy watching. Duration bias refers to the tendency for users to spend more time on videos with longer durations, regardless of their actual interest level. Noisy watching, on the other hand, describes users taking time to determine whether they like a video or not, which can result in users spending time watching videos they do not like. Consequently, the existence of duration bias and noisy watching make watch time an inadequate label for indicating user interest. Furthermore, current methods primarily address duration bias and ignore the impact of noisy watching, which may limit their effectiveness in uncovering user interest from watch time. In this study, we first analyze the generation mechanism of users' watch time from a unified causal viewpoint. Specifically, we considered the watch time as a mixture of the user's actual interest level, the duration-biased watch time, and the noisy watch time. To mitigate both the duration bias and noisy watching, we propose Debiased and Denoised watch time Correction (D$^2$Co), which can be divided into two steps: First, we employ a duration-wise Gaussian Mixture Model plus frequency-weighted moving average for estimating the bias and noise terms; then we utilize a sensitivity-controlled correction function to separate the user interest from the watch time, which is robust to the estimation error of bias and noise terms. The experiments on two public video recommendation datasets and online A/B testing indicate the effectiveness of the proposed method.
Uncovering ChatGPT's Capabilities in Recommender Systems
May 11, 2023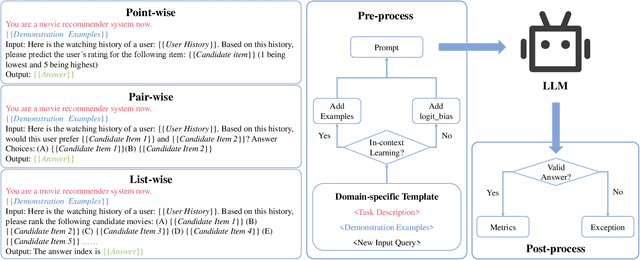
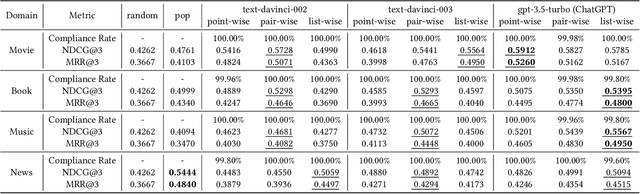

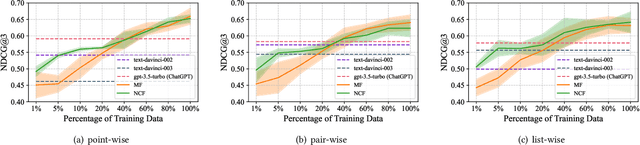
The debut of ChatGPT has recently attracted the attention of the natural language processing (NLP) community and beyond. Existing studies have demonstrated that ChatGPT shows significant improvement in a range of downstream NLP tasks, but the capabilities and limitations of ChatGPT in terms of recommendations remain unclear. In this study, we aim to conduct an empirical analysis of ChatGPT's recommendation ability from an Information Retrieval (IR) perspective, including point-wise, pair-wise, and list-wise ranking. To achieve this goal, we re-formulate the above three recommendation policies into a domain-specific prompt format. Through extensive experiments on four datasets from different domains, we demonstrate that ChatGPT outperforms other large language models across all three ranking policies. Based on the analysis of unit cost improvements, we identify that ChatGPT with list-wise ranking achieves the best trade-off between cost and performance compared to point-wise and pair-wise ranking. Moreover, ChatGPT shows the potential for mitigating the cold start problem and explainable recommendation. To facilitate further explorations in this area, the full code and detailed original results are open-sourced at https://github.com/rainym00d/LLM4RS.
Unbiased Top-k Learning to Rank with Causal Likelihood Decomposition
Apr 02, 2022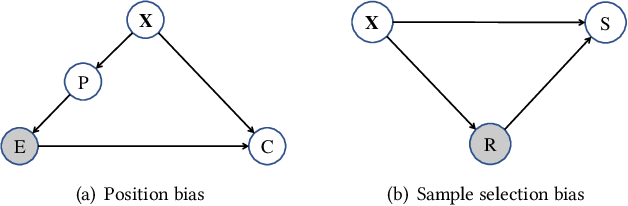


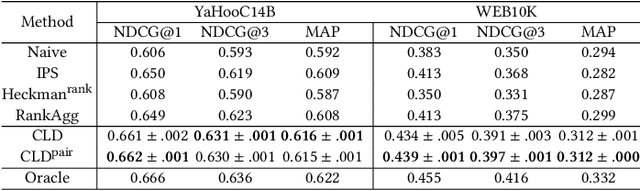
Unbiased learning to rank has been proposed to alleviate the biases in the search ranking, making it possible to train ranking models with user interaction data. In real applications, search engines are designed to display only the most relevant k documents from the retrieved candidate set. The rest candidates are discarded. As a consequence, position bias and sample selection bias usually occur simultaneously. Existing unbiased learning to rank approaches either focus on one type of bias (e.g., position bias) or mitigate the position bias and sample selection bias with separate components, overlooking their associations. In this study, we first analyze the mechanisms and associations of position bias and sample selection bias from the viewpoint of a causal graph. Based on the analysis, we propose Causal Likelihood Decomposition (CLD), a unified approach to simultaneously mitigating these two biases in top-k learning to rank. By decomposing the log-likelihood of the biased data as an unbiased term that only related to relevance, plus other terms related to biases, CLD successfully detaches the relevance from position bias and sample selection bias. An unbiased ranking model can be obtained from the unbiased term, via maximizing the whole likelihood. An extension to the pairwise neural ranking is also developed. Advantages of CLD include theoretical soundness and a unified framework for pointwise and pairwise unbiased top-k learning to rank. Extensive experimental results verified that CLD, including its pairwise neural extension, outperformed the baselines by mitigating both the position bias and the sample selection bias. Empirical studies also showed that CLD is robust to the variation of bias severity and the click noise.