 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Top-k Learning to Rank with Causal Likelihood Decomposition
Paper and Code
Apr 02, 2022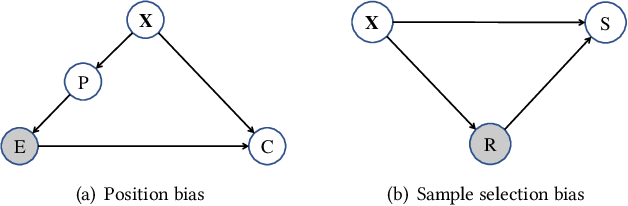


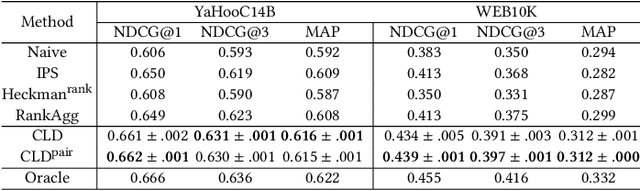
Unbiased learning to rank has been proposed to alleviate the biases in the search ranking, making it possible to train ranking models with user interaction data. In real applications, search engines are designed to display only the most relevant k documents from the retrieved candidate set. The rest candidates are discarded. As a consequence, position bias and sample selection bias usually occur simultaneously. Existing unbiased learning to rank approaches either focus on one type of bias (e.g., position bias) or mitigate the position bias and sample selection bias with separate components, overlooking their associations. In this study, we first analyze the mechanisms and associations of position bias and sample selection bias from the viewpoint of a causal graph. Based on the analysis, we propose Causal Likelihood Decomposition (CLD), a unified approach to simultaneously mitigating these two biases in top-k learning to rank. By decomposing the log-likelihood of the biased data as an unbiased term that only related to relevance, plus other terms related to biases, CLD successfully detaches the relevance from position bias and sample selection bias. An unbiased ranking model can be obtained from the unbiased term, via maximizing the whole likelihood. An extension to the pairwise neural ranking is also developed. Advantages of CLD include theoretical soundness and a unified framework for pointwise and pairwise unbiased top-k learning to rank. Extensive experimental results verified that CLD, including its pairwise neural extension, outperformed the baselines by mitigating both the position bias and the sample selection bias. Empirical studies also showed that CLD is robust to the variation of bias severity and the click noise.