 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedNAR: Federated Optimization with Normalized Annealing Regularization
Paper and Code

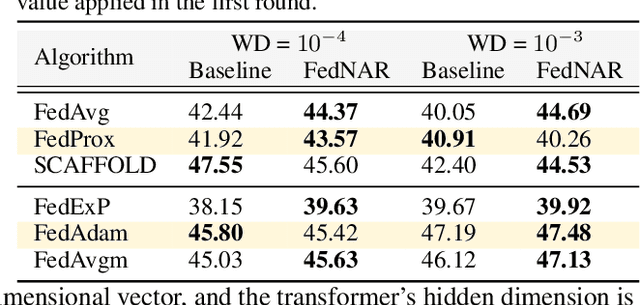
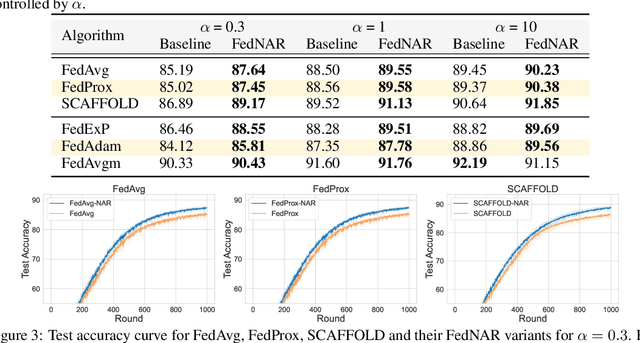

Weight decay is a standard technique to improve generalization performance in modern deep neural network optimization, and is also widely adopted in federated learning (FL) to prevent overfitting in local clients. In this paper, we first explore the choices of weight decay and identify that weight decay value appreciably influences the convergence of existing FL algorithms. While preventing overfitting is crucial, weight decay can introduce a different optimization goal towards the global objective, which is further amplified in FL due to multiple local updates and heterogeneous data distribution. To address this challenge, we develop {\it Federated optimization with Normalized Annealing Regularization} (FedNAR), a simple yet effective and versatile algorithmic plug-in that can be seamlessly integrated into any existing FL algorithms. Essentially, we regulate the magnitude of each update by performing co-clipping of the gradient and weight decay. We provide a comprehensive theoretical analysis of FedNAR's convergence rate and conduct extensive experiments on both vision and language datasets with different backbone federated optimization algorithms. Our experimental results consistently demonstrate that incorporating FedNAR into existing FL algorithms leads to accelerated convergence and heightened model accuracy. Moreover, FedNAR exhibits resilience in the face of various hyperparameter configurations. Specifically, FedNAR has the ability to self-adjust the weight decay when the initial specification is not optimal, while the accuracy of traditional FL algorithms would markedly decline. Our codes are released at \href{https://github.com/ljb121002/fednar}{https://github.com/ljb121002/fednar}.