 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCValues: Measuring the Values of Chinese Large Language Models from Safety to Responsibility
Jul 19, 2023With the rapid evolution of large language models (LLMs), there is a growing concern that they may pose risks or have negative social impacts. Therefore, evaluation of human values alignment is becoming increasingly important. Previous work mainly focuses on assessing the performance of LLMs on certain knowledge and reasoning abilities, while neglecting the alignment to human values, especially in a Chinese context. In this paper, we present CValues, the first Chinese human values evaluation benchmark to measure the alignment ability of LLMs in terms of both safety and responsibility criteria. As a result, we have manually collected adversarial safety prompts across 10 scenarios and induced responsibility prompts from 8 domains by professional experts. To provide a comprehensive values evaluation of Chinese LLMs, we not only conduct human evaluation for reliable comparison, but also construct multi-choice prompts for automatic evaluation. Our findings suggest that while most Chinese LLMs perform well in terms of safety, there is considerable room for improvement in terms of responsibility. Moreover, both the automatic and human evaluation are important for assessing the human values alignment in different aspects. The benchmark and code is available on ModelScope and Github.
Generating Disentangled Arguments with Prompts: A Simple Event Extraction Framework that Works
Oct 09, 2021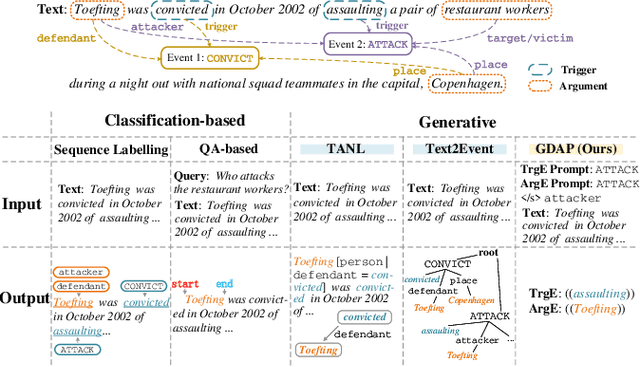
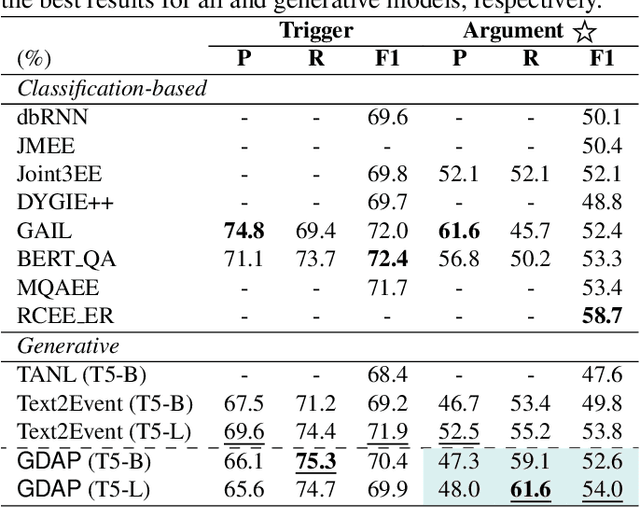
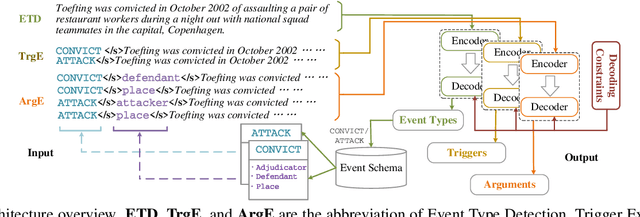
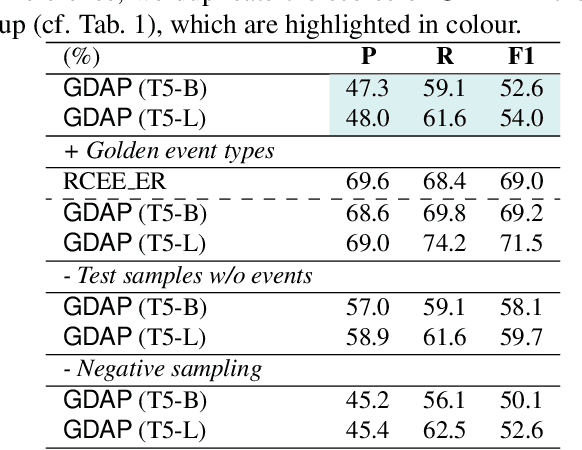
Event Extraction bridges the gap between text and event signals. Based on the assumption of trigger-argument dependency, existing approaches have achieved state-of-the-art performance with expert-designed templates or complicated decoding constraints. In this paper, for the first time we introduce the prompt-based learning strategy to the domain of Event Extraction, which empowers the automatic exploitation of label semantics on both input and output sides. To validate the effectiveness of the proposed generative method, we conduct extensive experiments with 11 diverse baselines. Empirical results show that, in terms of F1 score on Argument Extraction, our simple architecture is stronger than any other generative counterpart and even competitive with algorithms that require template engineering. Regarding the measure of recall, it sets new overall records for both Argument and Trigger Extractions. We hereby recommend this framework to the community, with the code publicly available at https://git.io/GDAP.