 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvert and Speak: Zero-shot Accent Conversion with Minimum Supervision
Aug 22, 2024Low resource of parallel data is the key challenge of accent conversion(AC) problem in which both the pronunciation units and prosody pattern need to be converted. We propose a two-stage generative framework "convert-and-speak" in which the conversion is only operated on the semantic token level and the speech is synthesized conditioned on the converted semantic token with a speech generative model in target accent domain. The decoupling design enables the "speaking" module to use massive amount of target accent speech and relieves the parallel data required for the "conversion" module. Conversion with the bridge of semantic token also relieves the requirement for the data with text transcriptions and unlocks the usage of language pre-training technology to further efficiently reduce the need of parallel accent speech data. To reduce the complexity and latency of "speaking", a single-stage AR generative model is designed to achieve good quality as well as lower computation cost. Experiments on Indian-English to general American-English conversion show that the proposed framework achieves state-of-the-art performance in accent similarity, speech quality, and speaker maintenance with only 15 minutes of weakly parallel data which is not constrained to the same speaker. Extensive experimentation with diverse accent types suggests that this framework possesses a high degree of adaptability, making it readily scalable to accommodate other accents with low-resource data. Audio samples are available at https://www.microsoft.com/en-us/research/project/convert-and-speak-zero-shot-accent-conversion-with-minimumsupervision/.
Low-latency Speech Enhancement via Speech Token Generation
Oct 20, 2023Existing deep learning based speech enhancement mainly employ a data-driven approach, which leverage large amounts of data with a variety of noise types to achieve noise removal from noisy signal. However, the high dependence on the data limits its generalization on the unseen complex noises in real-life environment. In this paper, we focus on the low-latency scenario and regard speech enhancement as a speech generation problem conditioned on the noisy signal, where we generate clean speech instead of identifying and removing noises. Specifically, we propose a conditional generative framework for speech enhancement, which models clean speech by acoustic codes of a neural speech codec and generates the speech codes conditioned on past noisy frames in an auto-regressive way. Moreover, we propose an explicit-alignment approach to align noisy frames with the generated speech tokens to improve the robustness and scalability to different input lengths. Different from other methods that leverage multiple stages to generate speech codes, we leverage a single-stage speech generation approach based on the TF-Codec neural codec to achieve high speech quality with low latency. Extensive results on both synthetic and real-recorded test set show its superiority over data-driven approaches in terms of noise robustness and temporal speech coherence.
Contrast-PLC: Contrastive Learning for Packet Loss Concealment
Feb 26, 2023Packet loss concealment (PLC) is challenging in concealing missing contents both plausibly and naturally when there are only limited available context to use. Recently deep-learning based PLC algorithms have demonstrated their superiority over traditional counterparts; but their concealment ability is still mostly limited to a maximum of 120ms loss. Even with strong GAN-based generative models, it is still very challenging to predict long burst losses that could happen within/in-between phonemes. In this paper, we propose to use contrastive learning to learn a loss-robust semantic representation for PLC. A hybrid neural PLC architecture combining the semantic prediction and GAN-based generative model is designed to verify its effectiveness. Results on the blind test set of Interspeech2022 PLC Challenge show its superiority over commonly used UNet-style framework and the one without contrastive learning, especially for the longer burst loss at (120, 220] ms.
Predictive Neural Speech Coding
Jul 18, 2022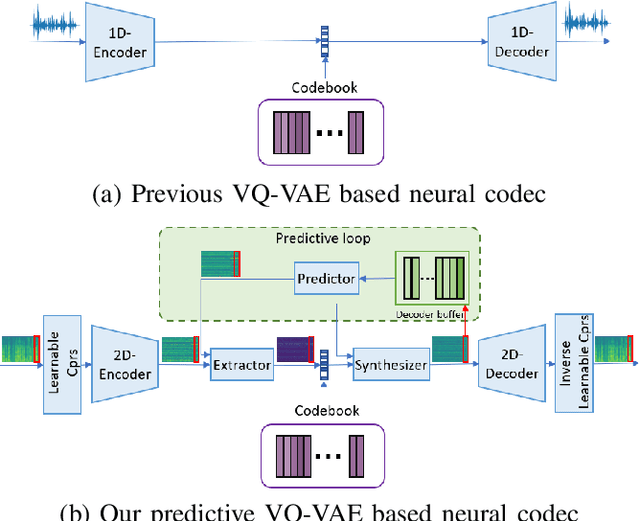
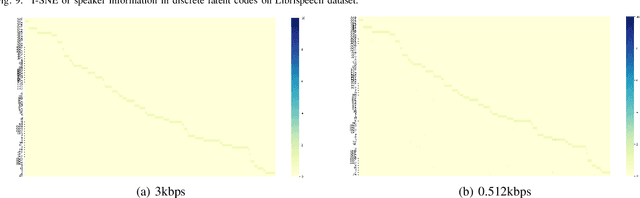
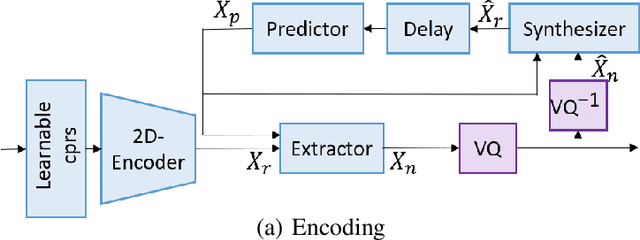
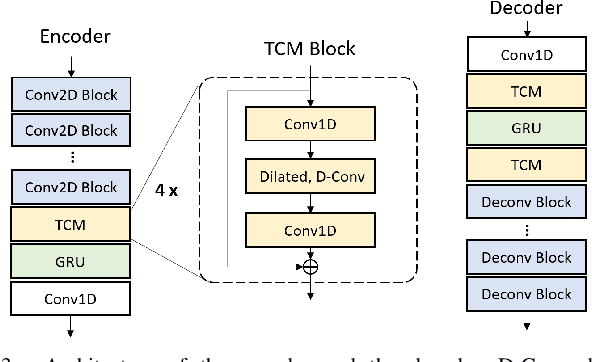
Neural audio/speech coding has shown its capability to deliver a high quality at much lower bitrates than traditional methods recently. However, existing neural audio/speech codecs employ either acoustic features or learned blind features with a convolutional neural network for encoding, by which there are still temporal redundancies inside encoded features. This paper introduces latent-domain predictive coding into the VQ-VAE framework to fully remove such redundancies and proposes the TF-Codec for low-latency neural speech coding in an end-to-end way. Specifically, the extracted features are encoded conditioned on a prediction from past quantized latent frames so that temporal correlations are further removed. What's more, we introduce a learnable compression on the time-frequency input to adaptively adjust the attention paid on main frequencies and details at different bitrates. A differentiable vector quantization scheme based on distance-to-soft mapping and Gumbel-Softmax is proposed to better model the latent distributions with rate constraint. Subjective results on multilingual speech datasets show that with a latency of 40ms, the proposed TF-Codec at 1kbps can achieve a much better quality than Opus 9kbps and TF-Codec at 3kbps outperforms both EVS 9.6kbps and Opus 12kbps. Numerous studies are conducted to show the effectiveness of these techniques.
Cross-Scale Vector Quantization for Scalable Neural Speech Coding
Jul 07, 2022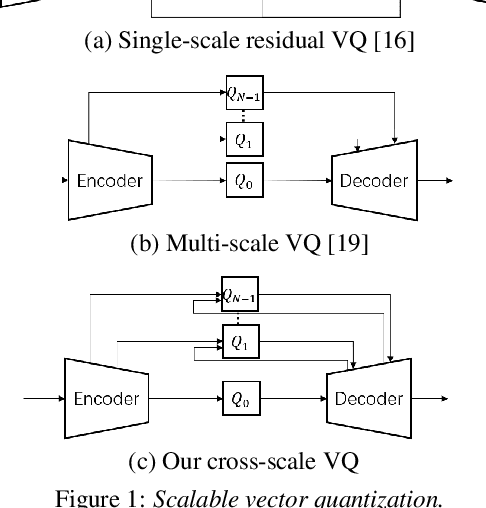
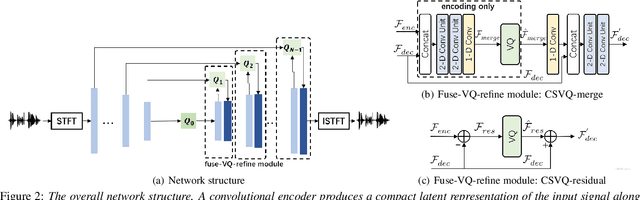
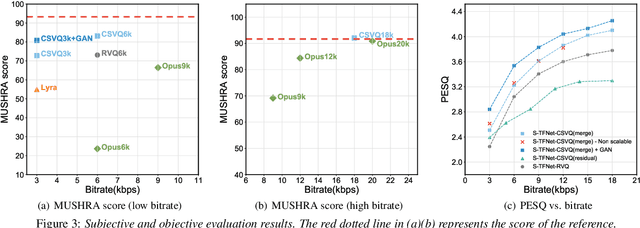
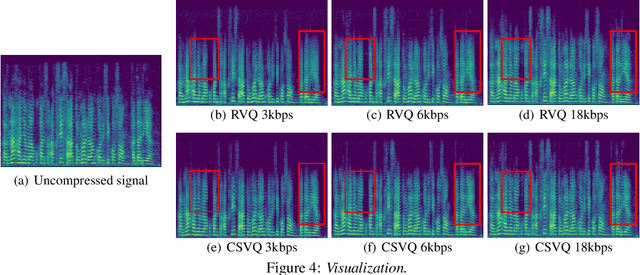
Bitrate scalability is a desirable feature for audio coding in real-time communications. Existing neural audio codecs usually enforce a specific bitrate during training, so different models need to be trained for each target bitrate, which increases the memory footprint at the sender and the receiver side and transcoding is often needed to support multiple receivers. In this paper, we introduce a cross-scale scalable vector quantization scheme (CSVQ), in which multi-scale features are encoded progressively with stepwise feature fusion and refinement. In this way, a coarse-level signal is reconstructed if only a portion of the bitstream is received, and progressively improves the quality as more bits are available. The proposed CSVQ scheme can be flexibly applied to any neural audio coding network with a mirrored auto-encoder structure to achieve bitrate scalability. Subjective results show that the proposed scheme outperforms the classical residual VQ (RVQ) with scalability. Moreover, the proposed CSVQ at 3 kbps outperforms Opus at 9 kbps and Lyra at 3kbps and it could provide a graceful quality boost with bitrate increase.
Towards Error-Resilient Neural Speech Coding
Jul 03, 2022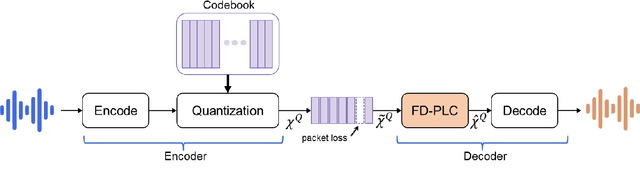
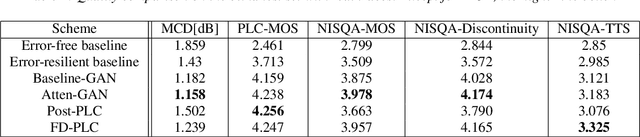

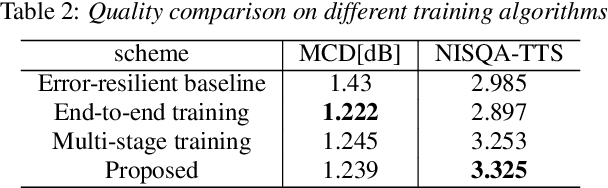
Neural audio coding has shown very promising results recently in the literature to largely outperform traditional codecs but limited attention has been paid on its error resilience. Neural codecs trained considering only source coding tend to be extremely sensitive to channel noises, especially in wireless channels with high error rate. In this paper, we investigate how to elevate the error resilience of neural audio codecs for packet losses that often occur during real-time communications. We propose a feature-domain packet loss concealment algorithm (FD-PLC) for real-time neural speech coding. Specifically, we introduce a self-attention-based module on the received latent features to recover lost frames in the feature domain before the decoder. A hybrid segment-level and frame-level frequency-domain discriminator is employed to guide the network to focus on both the generative quality of lost frames and the continuity with neighbouring frames. Experimental results on several error patterns show that the proposed scheme can achieve better robustness compared with the corresponding error-free and error-resilient baselines. We also show that feature-domain concealment is superior to waveform-domain counterpart as post-processing.
End-to-End Neural Audio Coding for Real-Time Communications
Jan 25, 2022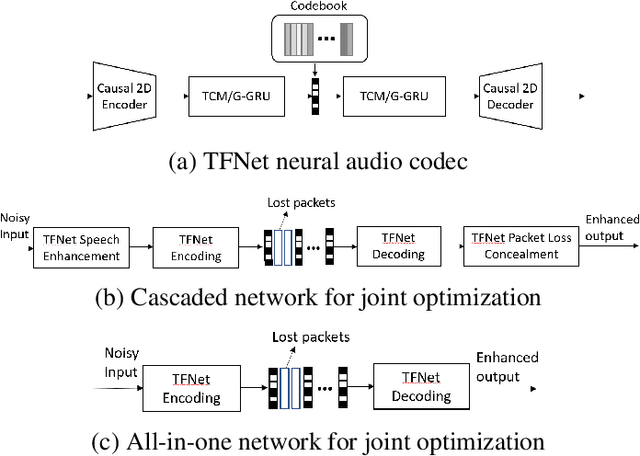
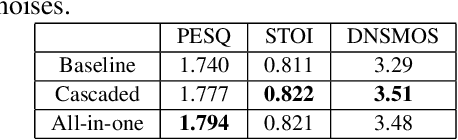
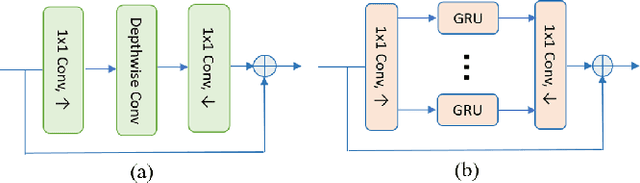
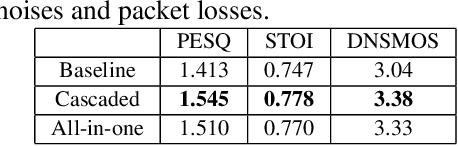
Deep-learning based methods have shown their advantages in audio coding over traditional ones but limited attention has been paid on real-time communications (RTC). This paper proposes the TFNet, an end-to-end neural audio codec with low latency for RTC. It takes an encoder-temporal filtering-decoder paradigm that seldom being investigated in audio coding. An interleaved structure is proposed for temporal filtering to capture both short-term and long-term temporal dependencies. Furthermore, with end-to-end optimization, the TFNet is jointly optimized with speech enhancement and packet loss concealment, yielding a one-for-all network for three tasks. Both subjective and objective results demonstrate the efficiency of the proposed TFNet.