 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Neural Speech Coding
Paper and Code
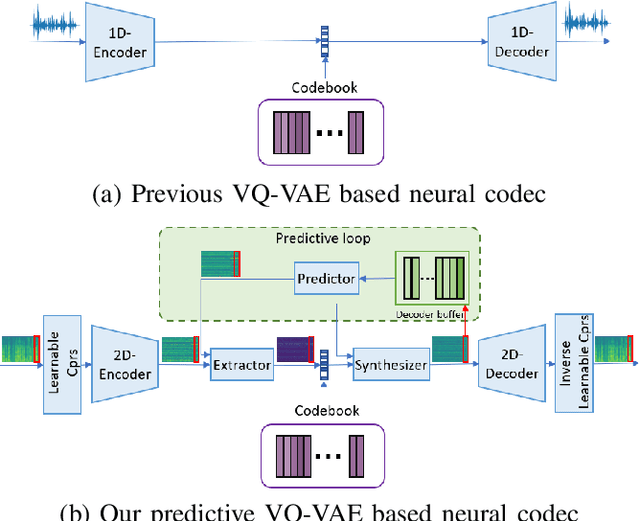
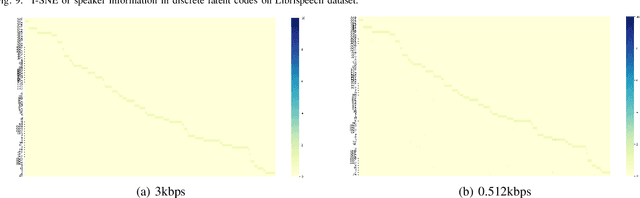
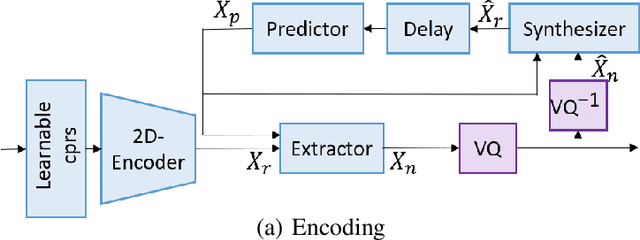
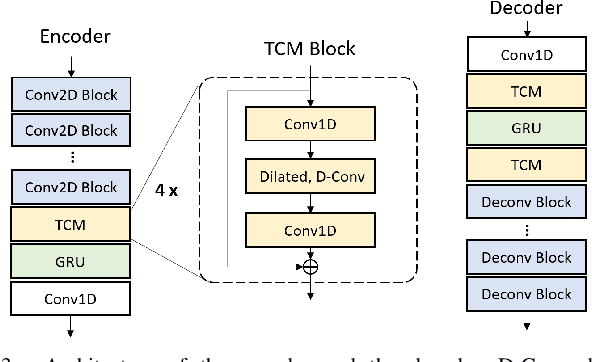
Neural audio/speech coding has shown its capability to deliver a high quality at much lower bitrates than traditional methods recently. However, existing neural audio/speech codecs employ either acoustic features or learned blind features with a convolutional neural network for encoding, by which there are still temporal redundancies inside encoded features. This paper introduces latent-domain predictive coding into the VQ-VAE framework to fully remove such redundancies and proposes the TF-Codec for low-latency neural speech coding in an end-to-end way. Specifically, the extracted features are encoded conditioned on a prediction from past quantized latent frames so that temporal correlations are further removed. What's more, we introduce a learnable compression on the time-frequency input to adaptively adjust the attention paid on main frequencies and details at different bitrates. A differentiable vector quantization scheme based on distance-to-soft mapping and Gumbel-Softmax is proposed to better model the latent distributions with rate constraint. Subjective results on multilingual speech datasets show that with a latency of 40ms, the proposed TF-Codec at 1kbps can achieve a much better quality than Opus 9kbps and TF-Codec at 3kbps outperforms both EVS 9.6kbps and Opus 12kbps. Numerous studies are conducted to show the effectiveness of these techniques.