 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Variance Aware Real-Time Speech Enhancement
Paper and Code
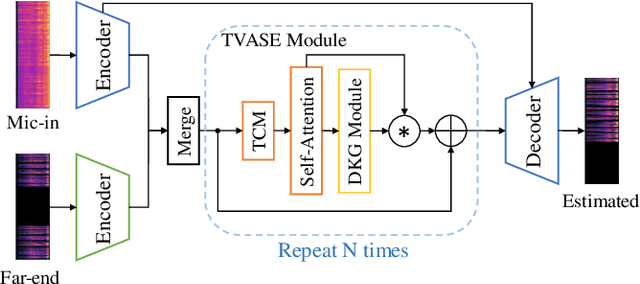
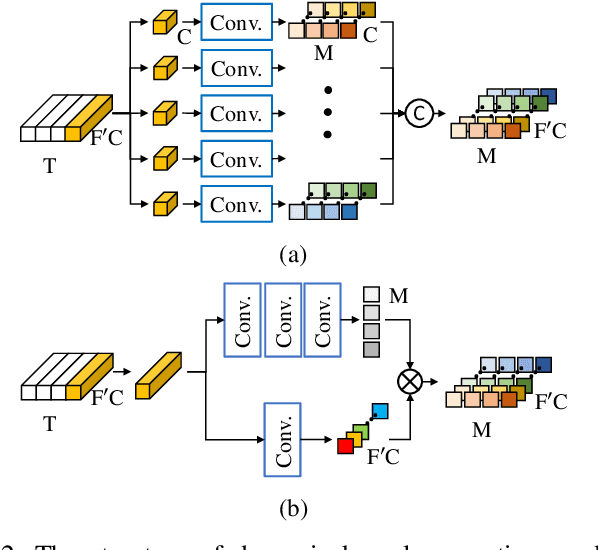
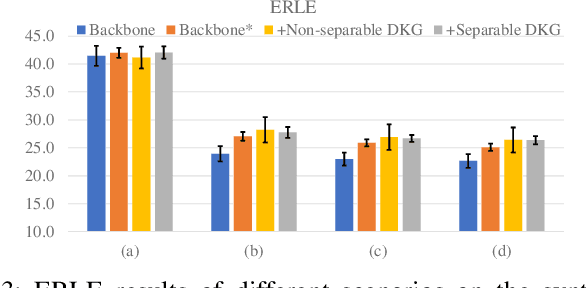
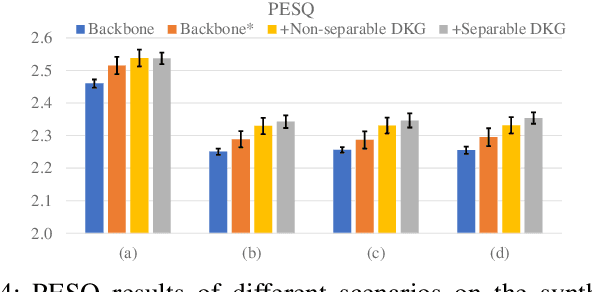
Time-variant factors often occur in real-world full-duplex communication applications. Some of them are caused by the complex environment such as non-stationary environmental noises and varying acoustic path while some are caused by the communication system such as the dynamic delay between the far-end and near-end signals. Current end-to-end deep neural network (DNN) based methods usually model the time-variant components implicitly and can hardly handle the unpredictable time-variance in real-time speech enhancement. To explicitly capture the time-variant components, we propose a dynamic kernel generation (DKG) module that can be introduced as a learnable plug-in to a DNN-based end-to-end pipeline. Specifically, the DKG module generates a convolutional kernel regarding to each input audio frame, so that the DNN model is able to dynamically adjust its weights according to the input signal during inference. Experimental results verify that DKG module improves the performance of the model under time-variant scenarios, in the joint acoustic echo cancellation (AEC) and deep noise suppression (DNS) tasks.