 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombined Generative and Predictive Modeling for Speech Super-resolution
Jan 25, 2024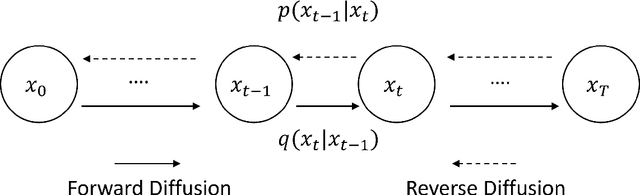
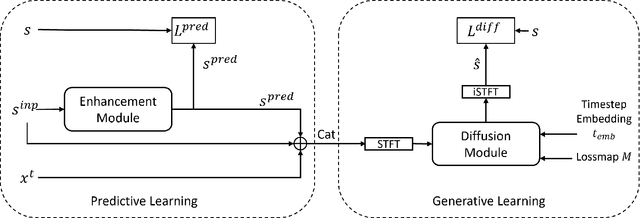
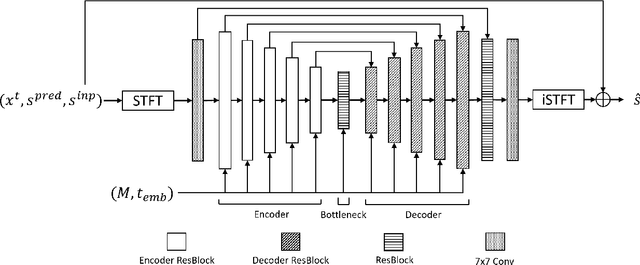
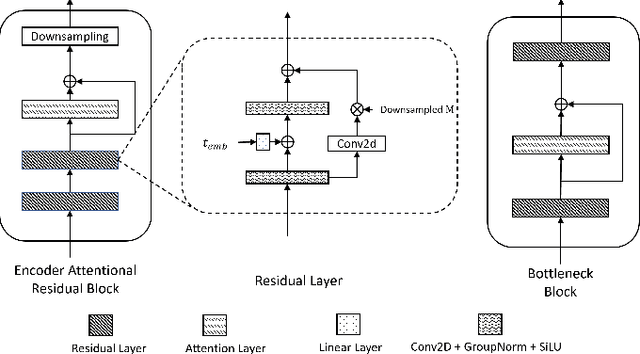
Speech super-resolution (SR) is the task that restores high-resolution speech from low-resolution input. Existing models employ simulated data and constrained experimental settings, which limit generalization to real-world SR. Predictive models are known to perform well in fixed experimental settings, but can introduce artifacts in adverse conditions. On the other hand, generative models learn the distribution of target data and have a better capacity to perform well on unseen conditions. In this study, we propose a novel two-stage approach that combines the strengths of predictive and generative models. Specifically, we employ a diffusion-based model that is conditioned on the output of a predictive model. Our experiments demonstrate that the model significantly outperforms single-stage counterparts and existing strong baselines on benchmark SR datasets. Furthermore, we introduce a repainting technique during the inference of the diffusion process, enabling the proposed model to regenerate high-frequency components even in mismatched conditions. An additional contribution is the collection of and evaluation on real SR recordings, using the same microphone at different native sampling rates. We make this dataset freely accessible, to accelerate progress towards real-world speech super-resolution.