 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-sequence Singing Voice Synthesis with Perceptual Entropy Loss
Paper and Code
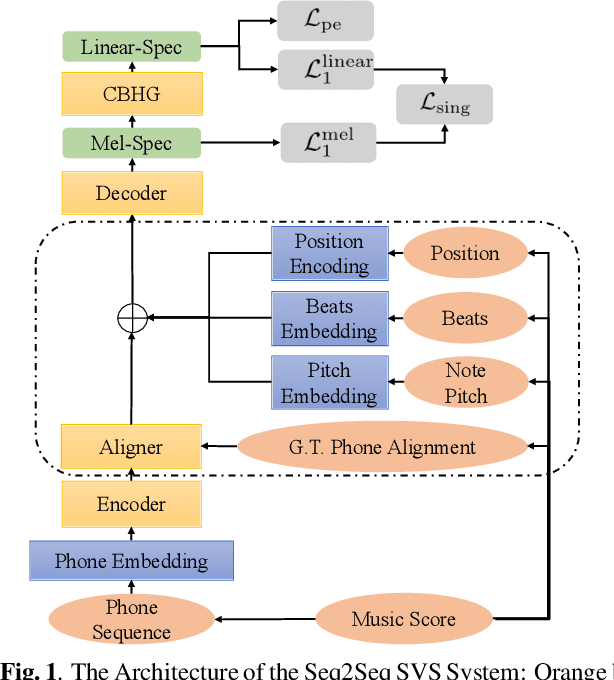
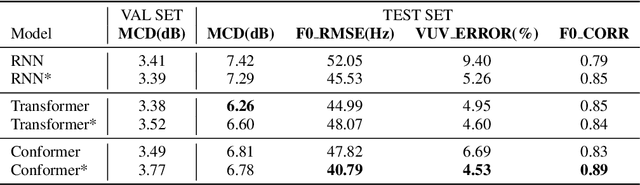
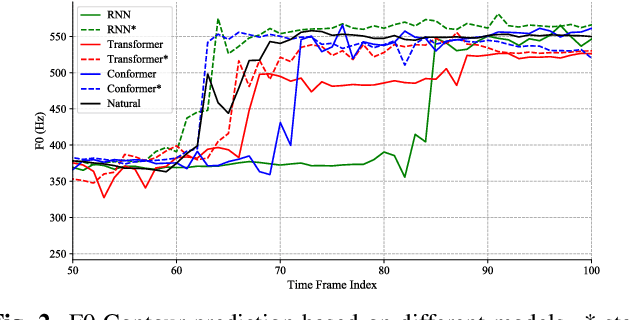
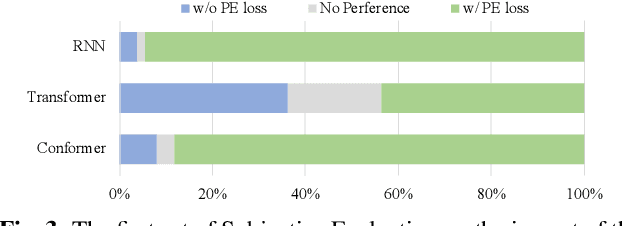
The neural network (NN) based singing voice synthesis (SVS) systems require sufficient data to train well. However, due to high data acquisition and annotation cost, we often encounter data limitation problem in building SVS systems. The NN based models are prone to over-fitting due to data scarcity. In this work, we propose a Perceptual Entropy (PE) loss derived from a psycho-acoustic hearing model to regularize the network. With a one-hour open-source singing voice database, we explore the impact of the PE loss on various mainstream sequence-to-sequence models, including the RNN-based model, transformer-based model, and conformer-based model. Our experiments show that the PE loss can mitigate the over-fitting problem and significantly improve the synthesized singing quality reflected in objective and subjective evaluations. Furthermore, incorporating the PE loss in model training is shown to help the F0-contour and high-frequency-band spectrum prediction.