 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightBTSeg: A lightweight breast tumor segmentation model using ultrasound images via dual-path joint knowledge distillation
Nov 18, 2023The accurate segmentation of breast tumors is an important prerequisite for lesion detection, which has significant clinical value for breast tumor research. The mainstream deep learning-based methods have achieved a breakthrough. However, these high-performance segmentation methods are formidable to implement in clinical scenarios since they always embrace high computation complexity, massive parameters, slow inference speed, and huge memory consumption. To tackle this problem, we propose LightBTSeg, a dual-path joint knowledge distillation framework, for lightweight breast tumor segmentation. Concretely, we design a double-teacher model to represent the fine-grained feature of breast ultrasound according to different semantic feature realignments of benign and malignant breast tumors. Specifically, we leverage the bottleneck architecture to reconstruct the original Attention U-Net. It is regarded as a lightweight student model named Simplified U-Net. Then, the prior knowledge of benign and malignant categories is utilized to design the teacher network combined dual-path joint knowledge distillation, which distills the knowledge from cumbersome benign and malignant teachers to a lightweight student model. Extensive experiments conducted on breast ultrasound images (Dataset BUSI) and Breast Ultrasound Dataset B (Dataset B) datasets demonstrate that LightBTSeg outperforms various counterparts.
LightVessel: Exploring Lightweight Coronary Artery Vessel Segmentation via Similarity Knowledge Distillation
Nov 02, 2022In recent years, deep convolution neural networks (DCNNs) have achieved great prospects in coronary artery vessel segmentation. However, it is difficult to deploy complicated models in clinical scenarios since high-performance approaches have excessive parameters and high computation costs. To tackle this problem, we propose \textbf{LightVessel}, a Similarity Knowledge Distillation Framework, for lightweight coronary artery vessel segmentation. Primarily, we propose a Feature-wise Similarity Distillation (FSD) module for semantic-shift modeling. Specifically, we calculate the feature similarity between the symmetric layers from the encoder and decoder. Then the similarity is transferred as knowledge from a cumbersome teacher network to a non-trained lightweight student network. Meanwhile, for encouraging the student model to learn more pixel-wise semantic information, we introduce the Adversarial Similarity Distillation (ASD) module. Concretely, the ASD module aims to construct the spatial adversarial correlation between the annotation and prediction from the teacher and student models, respectively. Through the ASD module, the student model obtains fined-grained subtle edge segmented results of the coronary artery vessel. Extensive experiments conducted on Clinical Coronary Artery Vessel Dataset demonstrate that LightVessel outperforms various knowledge distillation counterparts.
On the Detection of Digital Face Manipulation
Oct 03, 2019
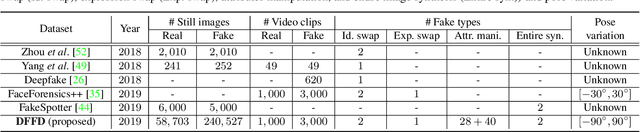
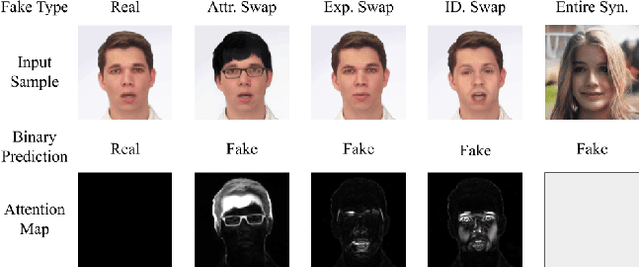
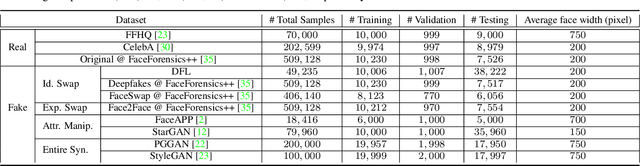
Detecting manipulated facial images and videos is an increasingly important topic in digital media forensics. As advanced synthetic face generation and manipulation methods become available, new types of fake face representations are being created and raise significant concerns for their implications in social media. Hence, it is crucial to detect the manipulated face image and locate manipulated facial regions. Instead of simply using a multi-task learning approach to simultaneously detect manipulated images and predict the manipulated mask (regions), we propose to utilize the attention mechanism to process and improve the feature maps of the classifier model. The learned attention maps highlight the informative regions to further improve the binary classification power, and also visualize the manipulated regions. In addition, to enable our study of manipulated facial images detection and localization, we have collected the first database which contains numerous types of facial forgeries. With this dataset, we perform a thorough analysis of data-driven fake face detection. We demonstrate that the use of an attention mechanism improves manipulated facial region localization and fake detection.