 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanary-1B-v2 & Parakeet-TDT-0.6B-v3: Efficient and High-Performance Models for Multilingual ASR and AST
Sep 17, 2025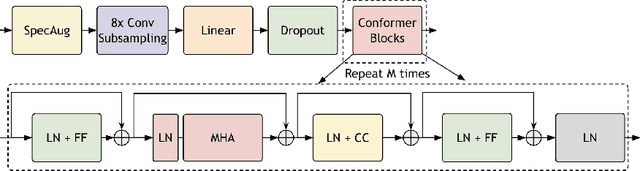
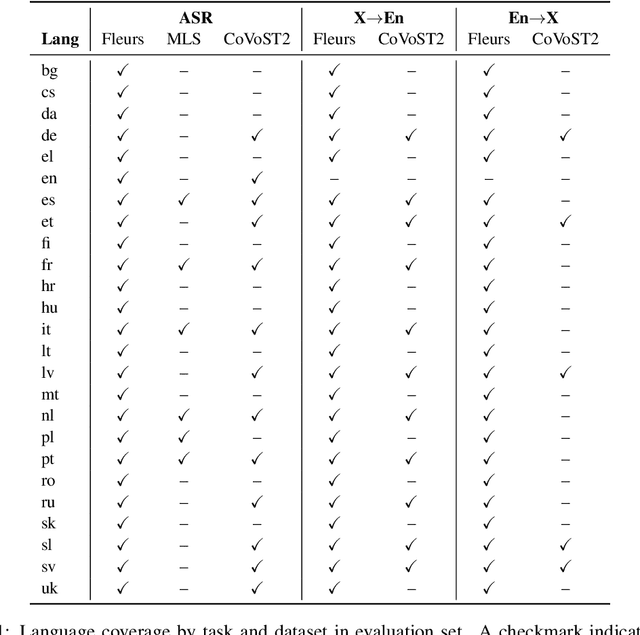
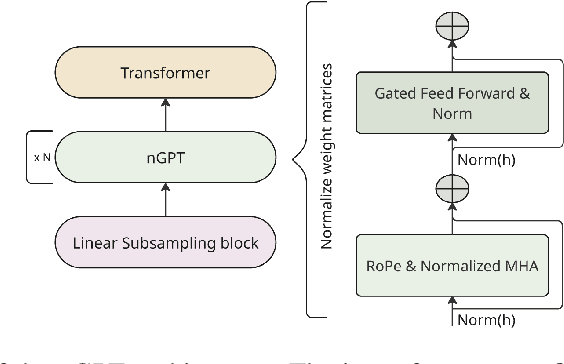

This report introduces Canary-1B-v2, a fast, robust multilingual model for Automatic Speech Recognition (ASR) and Speech-to-Text Translation (AST). Built with a FastConformer encoder and Transformer decoder, it supports 25 languages primarily European. The model was trained on 1.7M hours of total data samples, including Granary and NeMo ASR Set 3.0, with non-speech audio added to reduce hallucinations for ASR and AST. We describe its two-stage pre-training and fine-tuning process with dynamic data balancing, as well as experiments with an nGPT encoder. Results show nGPT scales well with massive data, while FastConformer excels after fine-tuning. For timestamps, Canary-1B-v2 uses the NeMo Forced Aligner (NFA) with an auxiliary CTC model, providing reliable segment-level timestamps for ASR and AST. Evaluations show Canary-1B-v2 outperforms Whisper-large-v3 on English ASR while being 10x faster, and delivers competitive multilingual ASR and AST performance against larger models like Seamless-M4T-v2-large and LLM-based systems. We also release Parakeet-TDT-0.6B-v3, a successor to v2, offering multilingual ASR across the same 25 languages with just 600M parameters.
Longer is (Not Necessarily) Stronger: Punctuated Long-Sequence Training for Enhanced Speech Recognition and Translation
Sep 09, 2024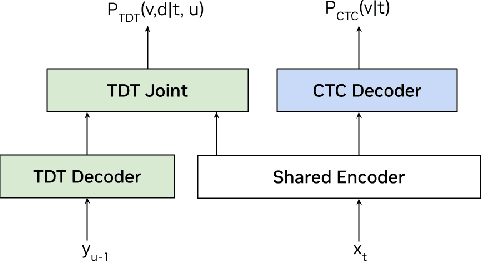
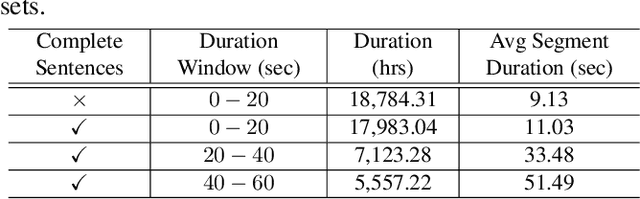

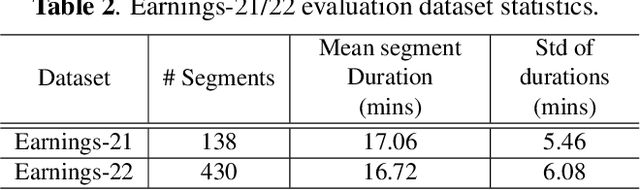
This paper presents a new method for training sequence-to-sequence models for speech recognition and translation tasks. Instead of the traditional approach of training models on short segments containing only lowercase or partial punctuation and capitalization (PnC) sentences, we propose training on longer utterances that include complete sentences with proper punctuation and capitalization. We achieve this by using the FastConformer architecture which allows training 1 Billion parameter models with sequences up to 60 seconds long with full attention. However, while training with PnC enhances the overall performance, we observed that accuracy plateaus when training on sequences longer than 40 seconds across various evaluation settings. Our proposed method significantly improves punctuation and capitalization accuracy, showing a 25% relative word error rate (WER) improvement on the Earnings-21 and Earnings-22 benchmarks. Additionally, training on longer audio segments increases the overall model accuracy across speech recognition and translation benchmarks. The model weights and training code are open-sourced though NVIDIA NeMo.
Contrastive Hebbian Learning with Random Feedback Weights
Jun 19, 2018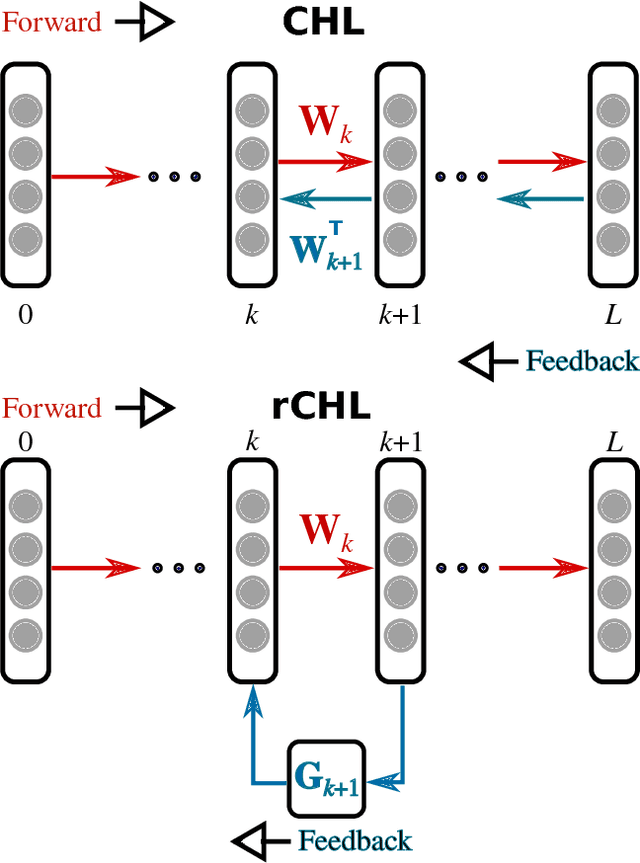
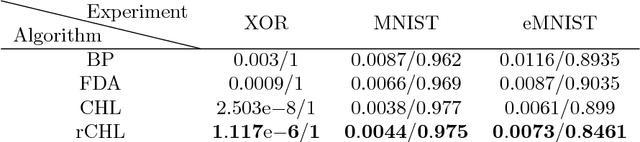

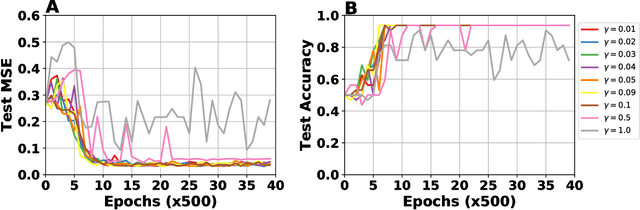
Neural networks are commonly trained to make predictions through learning algorithms. Contrastive Hebbian learning, which is a powerful rule inspired by gradient backpropagation, is based on Hebb's rule and the contrastive divergence algorithm. It operates in two phases, the forward (or free) phase, where the data are fed to the network, and a backward (or clamped) phase, where the target signals are clamped to the output layer of the network and the feedback signals are transformed through the transpose synaptic weight matrices. This implies symmetries at the synaptic level, for which there is no evidence in the brain. In this work, we propose a new variant of the algorithm, called random contrastive Hebbian learning, which does not rely on any synaptic weights symmetries. Instead, it uses random matrices to transform the feedback signals during the clamped phase, and the neural dynamics are described by first order non-linear differential equations. The algorithm is experimentally verified by solving a Boolean logic task, classification tasks (handwritten digits and letters), and an autoencoding task. This article also shows how the parameters affect learning, especially the random matrices. We use the pseudospectra analysis to investigate further how random matrices impact the learning process. Finally, we discuss the biological plausibility of the proposed algorithm, and how it can give rise to better computational models for learning.