 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Sampling Machine with Stochastic Synapse allows Brain-like Learning and Inference
Feb 20, 2021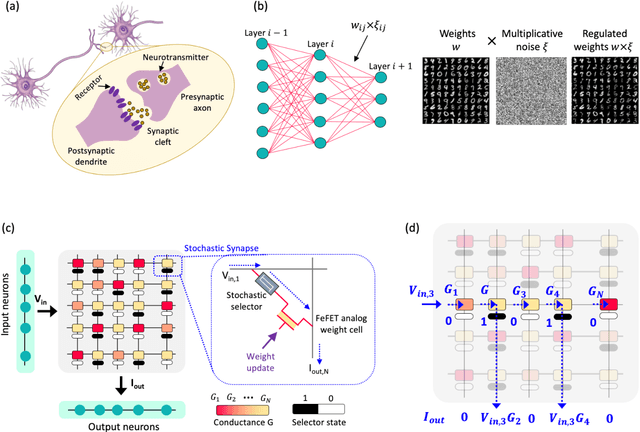
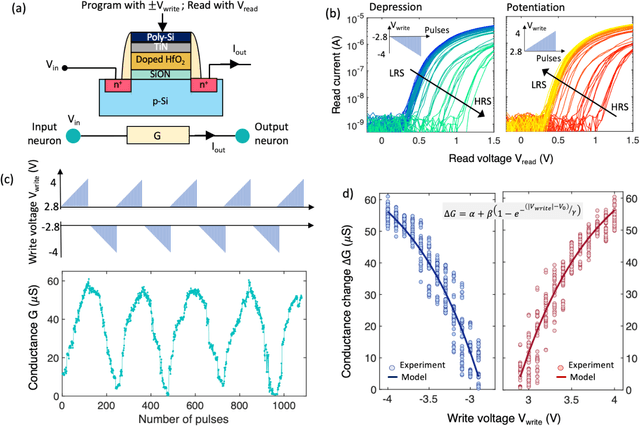
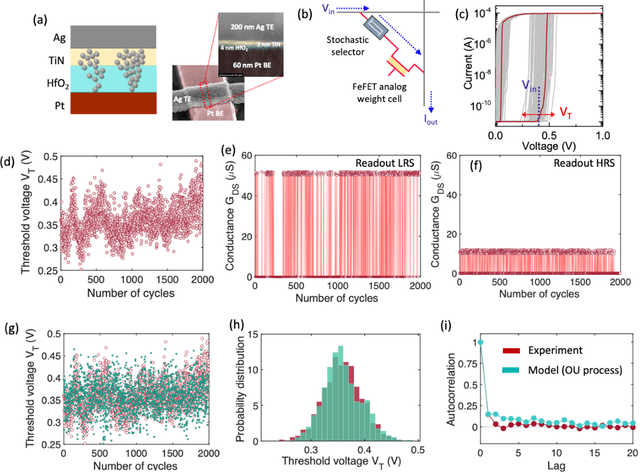
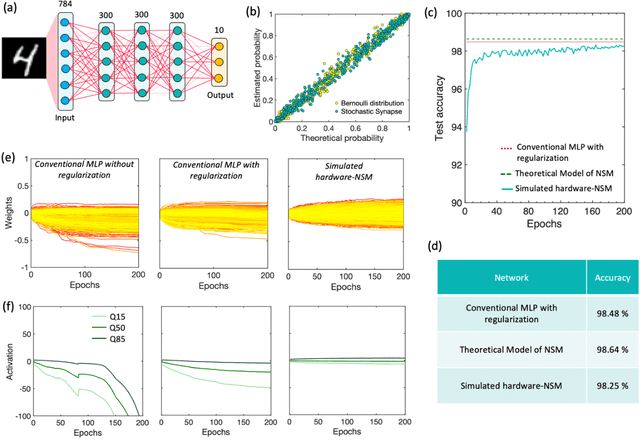
Many real-world mission-critical applications require continual online learning from noisy data and real-time decision making with a defined confidence level. Probabilistic models and stochastic neural networks can explicitly handle uncertainty in data and allow adaptive learning-on-the-fly, but their implementation in a low-power substrate remains a challenge. Here, we introduce a novel hardware fabric that implements a new class of stochastic NN called Neural-Sampling-Machine that exploits stochasticity in synaptic connections for approximate Bayesian inference. Harnessing the inherent non-linearities and stochasticity occurring at the atomic level in emerging materials and devices allows us to capture the synaptic stochasticity occurring at the molecular level in biological synapses. We experimentally demonstrate in-silico hybrid stochastic synapse by pairing a ferroelectric field-effect transistor -based analog weight cell with a two-terminal stochastic selector element. Such a stochastic synapse can be integrated within the well-established crossbar array architecture for compute-in-memory. We experimentally show that the inherent stochastic switching of the selector element between the insulator and metallic state introduces a multiplicative stochastic noise within the synapses of NSM that samples the conductance states of the FeFET, both during learning and inference. We perform network-level simulations to highlight the salient automatic weight normalization feature introduced by the stochastic synapses of the NSM that paves the way for continual online learning without any offline Batch Normalization. We also showcase the Bayesian inferencing capability introduced by the stochastic synapse during inference mode, thus accounting for uncertainty in data. We report 98.25%accuracy on standard image classification task as well as estimation of data uncertainty in rotated samples.
Inherent Weight Normalization in Stochastic Neural Networks
Oct 27, 2019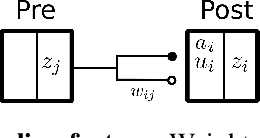

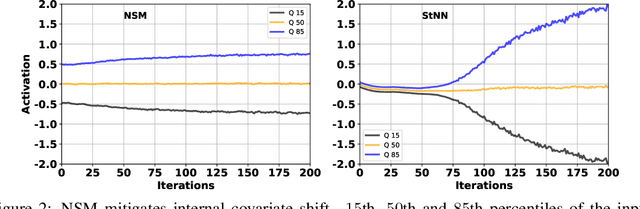

Multiplicative stochasticity such as Dropout improves the robustness and generalizability of deep neural networks. Here, we further demonstrate that always-on multiplicative stochasticity combined with simple threshold neurons are sufficient operations for deep neural networks. We call such models Neural Sampling Machines (NSM). We find that the probability of activation of the NSM exhibits a self-normalizing property that mirrors Weight Normalization, a previously studied mechanism that fulfills many of the features of Batch Normalization in an online fashion. The normalization of activities during training speeds up convergence by preventing internal covariate shift caused by changes in the input distribution. The always-on stochasticity of the NSM confers the following advantages: the network is identical in the inference and learning phases, making the NSM suitable for online learning, it can exploit stochasticity inherent to a physical substrate such as analog non-volatile memories for in-memory computing, and it is suitable for Monte Carlo sampling, while requiring almost exclusively addition and comparison operations. We demonstrate NSMs on standard classification benchmarks (MNIST and CIFAR) and event-based classification benchmarks (N-MNIST and DVS Gestures). Our results show that NSMs perform comparably or better than conventional artificial neural networks with the same architecture.
Neural and Synaptic Array Transceiver: A Brain-Inspired Computing Framework for Embedded Learning
Aug 08, 2018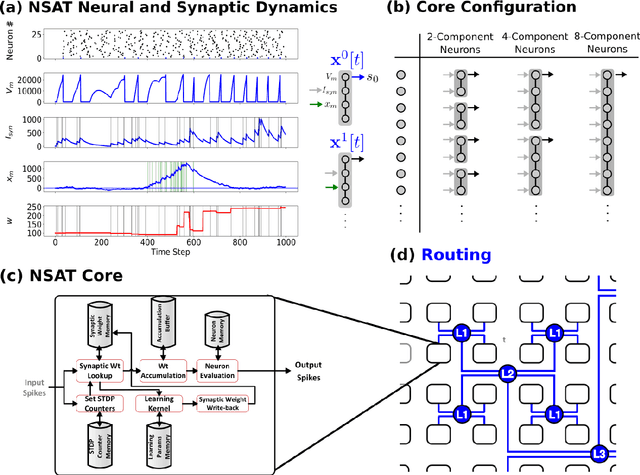

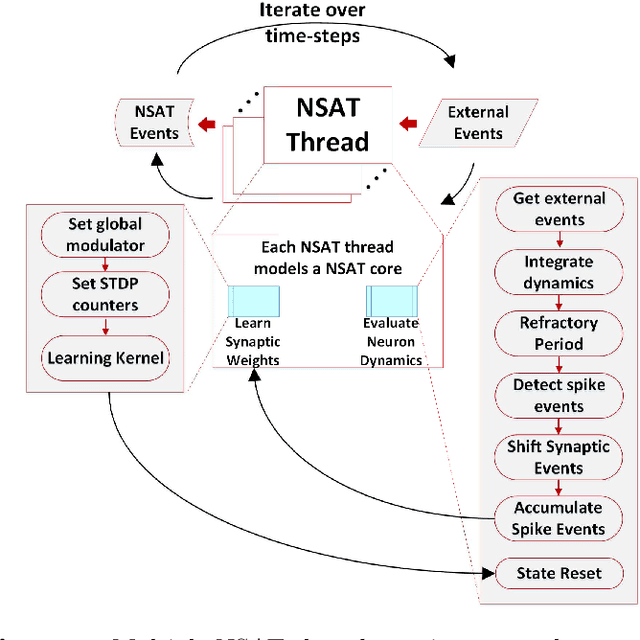
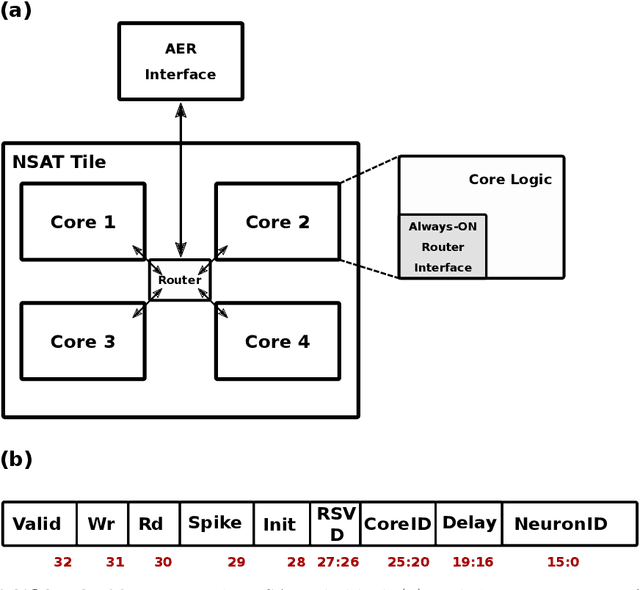
Embedded, continual learning for autonomous and adaptive behavior is a key application of neuromorphic hardware. However, neuromorphic implementations of embedded learning at large scales that are both flexible and efficient have been hindered by a lack of a suitable algorithmic framework. As a result, the most neuromorphic hardware is trained off-line on large clusters of dedicated processors or GPUs and transferred post hoc to the device. We address this by introducing the neural and synaptic array transceiver (NSAT), a neuromorphic computational framework facilitating flexible and efficient embedded learning by matching algorithmic requirements and neural and synaptic dynamics. NSAT supports event-driven supervised, unsupervised and reinforcement learning algorithms including deep learning. We demonstrate the NSAT in a wide range of tasks, including the simulation of Mihalas-Niebur neuron, dynamic neural fields, event-driven random back-propagation for event-based deep learning, event-based contrastive divergence for unsupervised learning, and voltage-based learning rules for sequence learning. We anticipate that this contribution will establish the foundation for a new generation of devices enabling adaptive mobile systems, wearable devices, and robots with data-driven autonomy.
Contrastive Hebbian Learning with Random Feedback Weights
Jun 19, 2018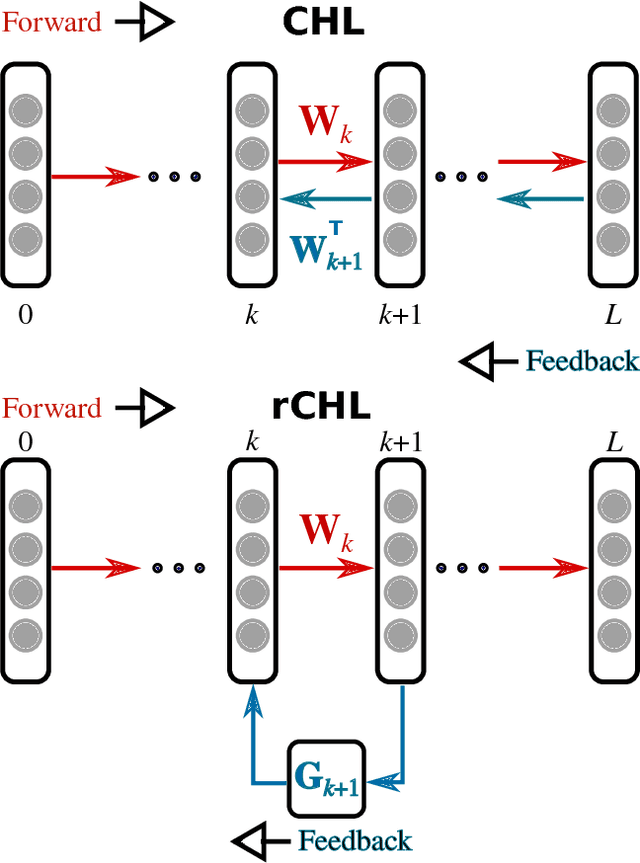
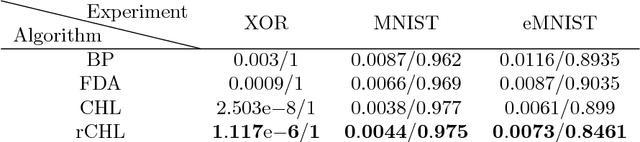

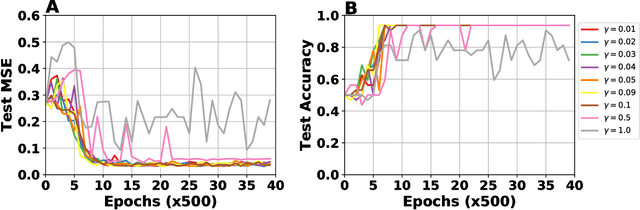
Neural networks are commonly trained to make predictions through learning algorithms. Contrastive Hebbian learning, which is a powerful rule inspired by gradient backpropagation, is based on Hebb's rule and the contrastive divergence algorithm. It operates in two phases, the forward (or free) phase, where the data are fed to the network, and a backward (or clamped) phase, where the target signals are clamped to the output layer of the network and the feedback signals are transformed through the transpose synaptic weight matrices. This implies symmetries at the synaptic level, for which there is no evidence in the brain. In this work, we propose a new variant of the algorithm, called random contrastive Hebbian learning, which does not rely on any synaptic weights symmetries. Instead, it uses random matrices to transform the feedback signals during the clamped phase, and the neural dynamics are described by first order non-linear differential equations. The algorithm is experimentally verified by solving a Boolean logic task, classification tasks (handwritten digits and letters), and an autoencoding task. This article also shows how the parameters affect learning, especially the random matrices. We use the pseudospectra analysis to investigate further how random matrices impact the learning process. Finally, we discuss the biological plausibility of the proposed algorithm, and how it can give rise to better computational models for learning.
Neuromorphic Deep Learning Machines
Jan 21, 2017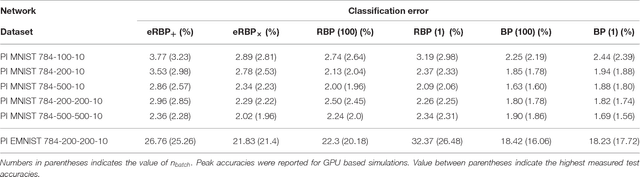
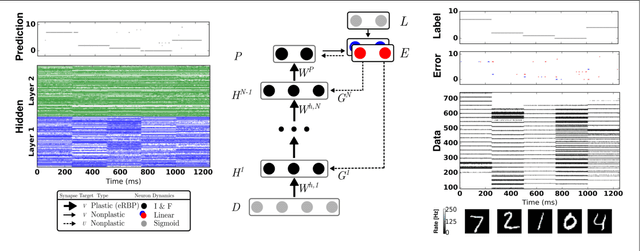
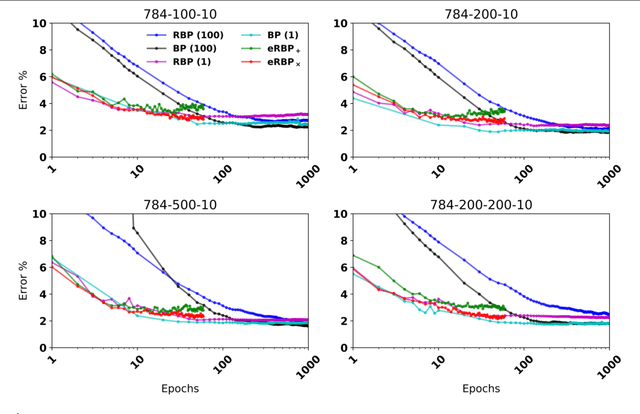
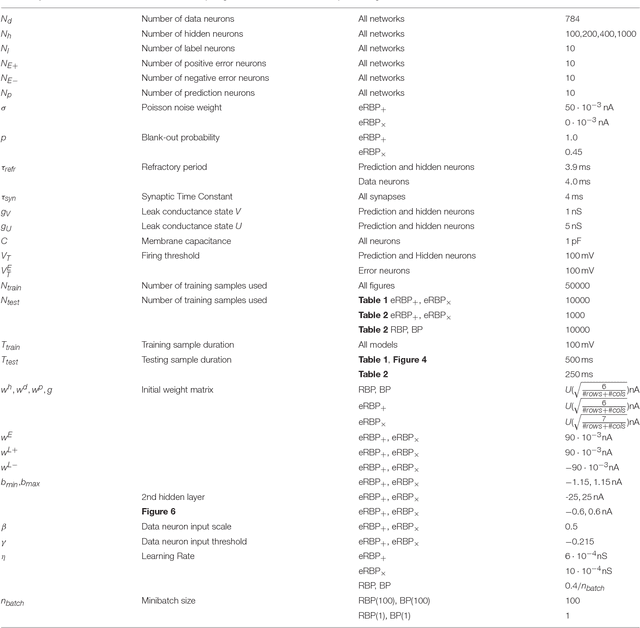
An ongoing challenge in neuromorphic computing is to devise general and computationally efficient models of inference and learning which are compatible with the spatial and temporal constraints of the brain. One increasingly popular and successful approach is to take inspiration from inference and learning algorithms used in deep neural networks. However, the workhorse of deep learning, the gradient descent Back Propagation (BP) rule, often relies on the immediate availability of network-wide information stored with high-precision memory, and precise operations that are difficult to realize in neuromorphic hardware. Remarkably, recent work showed that exact backpropagated weights are not essential for learning deep representations. Random BP replaces feedback weights with random ones and encourages the network to adjust its feed-forward weights to learn pseudo-inverses of the (random) feedback weights. Building on these results, we demonstrate an event-driven random BP (eRBP) rule that uses an error-modulated synaptic plasticity for learning deep representations in neuromorphic computing hardware. The rule requires only one addition and two comparisons for each synaptic weight using a two-compartment leaky Integrate & Fire (I&F) neuron, making it very suitable for implementation in digital or mixed-signal neuromorphic hardware. Our results show that using eRBP, deep representations are rapidly learned, achieving nearly identical classification accuracies compared to artificial neural network simulations on GPUs, while being robust to neural and synaptic state quantizations during learning.
Forward Table-Based Presynaptic Event-Triggered Spike-Timing-Dependent Plasticity
Jul 24, 2016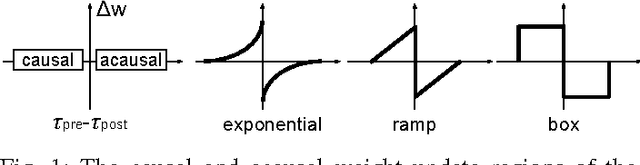
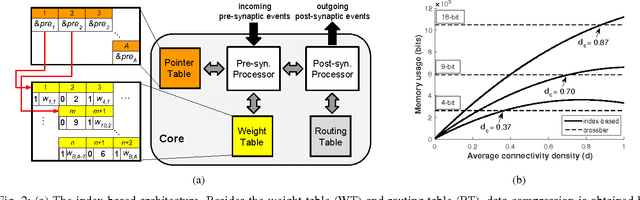
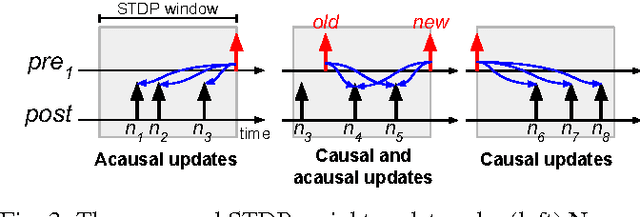
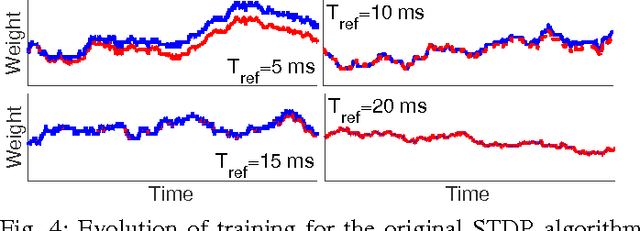
Spike-timing-dependent plasticity (STDP) incurs both causal and acausal synaptic weight updates, for negative and positive time differences between pre-synaptic and post-synaptic spike events. For realizing such updates in neuromorphic hardware, current implementations either require forward and reverse lookup access to the synaptic connectivity table, or rely on memory-intensive architectures such as crossbar arrays. We present a novel method for realizing both causal and acausal weight updates using only forward lookup access of the synaptic connectivity table, permitting memory-efficient implementation. A simplified implementation in FPGA, using a single timer variable for each neuron, closely approximates exact STDP cumulative weight updates for neuron refractory periods greater than 10 ms, and reduces to exact STDP for refractory periods greater than the STDP time window. Compared to conventional crossbar implementation, the forward table-based implementation leads to substantial memory savings for sparsely connected networks supporting scalable neuromorphic systems with fully reconfigurable synaptic connectivity and plasticity.