 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Level Timestamp Generation for Automatic Speech Recognition and Translation
May 21, 2025
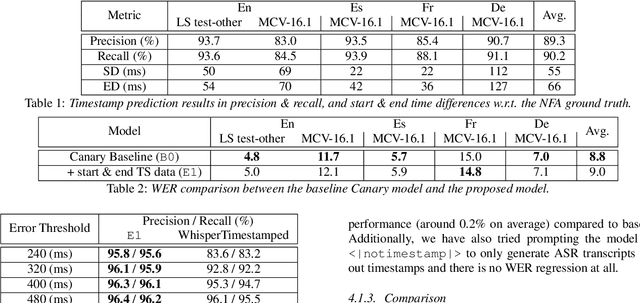
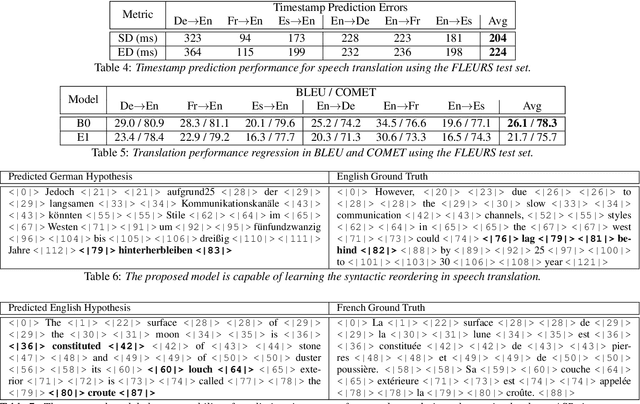
We introduce a data-driven approach for enabling word-level timestamp prediction in the Canary model. Accurate timestamp information is crucial for a variety of downstream tasks such as speech content retrieval and timed subtitles. While traditional hybrid systems and end-to-end (E2E) models may employ external modules for timestamp prediction, our approach eliminates the need for separate alignment mechanisms. By leveraging the NeMo Forced Aligner (NFA) as a teacher model, we generate word-level timestamps and train the Canary model to predict timestamps directly. We introduce a new <|timestamp|> token, enabling the Canary model to predict start and end timestamps for each word. Our method demonstrates precision and recall rates between 80% and 90%, with timestamp prediction errors ranging from 20 to 120 ms across four languages, with minimal WER degradation. Additionally, we extend our system to automatic speech translation (AST) tasks, achieving timestamp prediction errors around 200 milliseconds.
Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
Jun 28, 2024Recent advances in speech recognition and translation rely on hundreds of thousands of hours of Internet speech data. We argue that state-of-the art accuracy can be reached without relying on web-scale data. Canary - multilingual ASR and speech translation model, outperforms current state-of-the-art models - Whisper, OWSM, and Seamless-M4T on English, French, Spanish, and German languages, while being trained on an order of magnitude less data than these models. Three key factors enables such data-efficient model: (1) a FastConformer-based attention encoder-decoder architecture (2) training on synthetic data generated with machine translation and (3) advanced training techniques: data-balancing, dynamic data blending, dynamic bucketing and noise-robust fine-tuning. The model, weights, and training code will be open-sourced.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021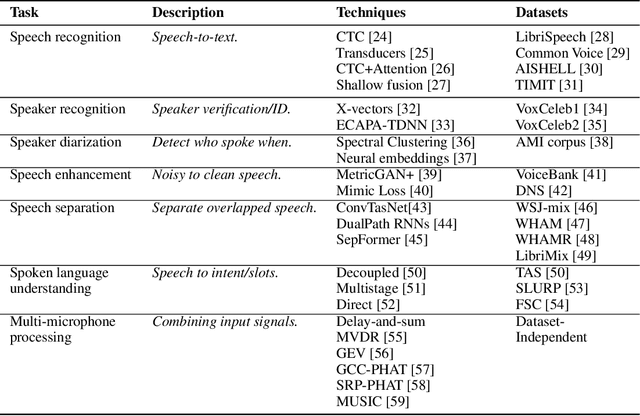
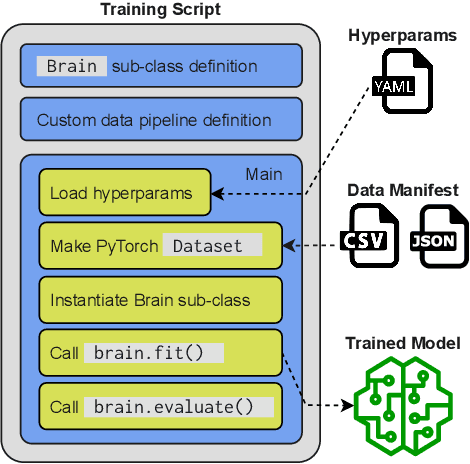

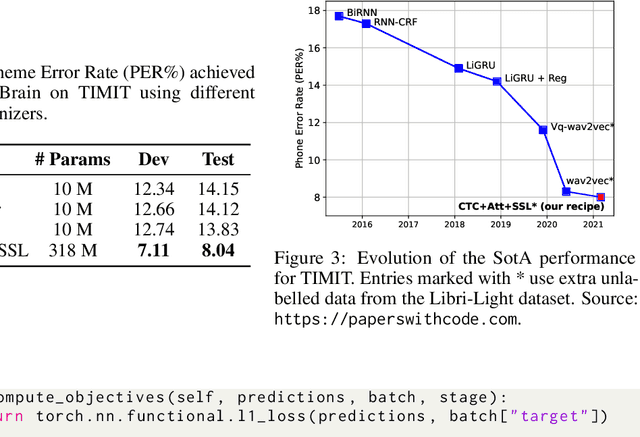
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
Author2Vec: A Framework for Generating User Embedding
Mar 17, 2020



Online forums and social media platforms provide noisy but valuable data every day. In this paper, we propose a novel end-to-end neural network-based user embedding system, Author2Vec. The model incorporates sentence representations generated by BERT (Bidirectional Encoder Representations from Transformers) with a novel unsupervised pre-training objective, authorship classification, to produce better user embedding that encodes useful user-intrinsic properties. This user embedding system was pre-trained on post data of 10k Reddit users and was analyzed and evaluated on two user classification benchmarks: depression detection and personality classification, in which the model proved to outperform traditional count-based and prediction-based methods. We substantiate that Author2Vec successfully encoded useful user attributes and the generated user embedding performs well in downstream classification tasks without further finetuning.