 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceTextBlender: Augmenting Large Language Models with Speech Capabilities via Single-Stage Joint Speech-Text Supervised Fine-Tuning
Paper and Code
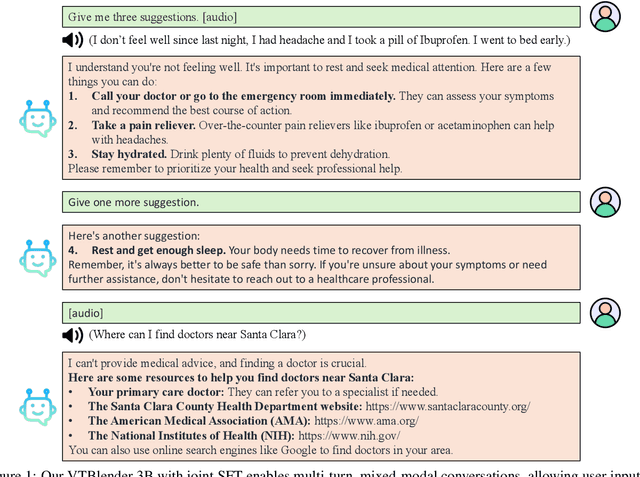
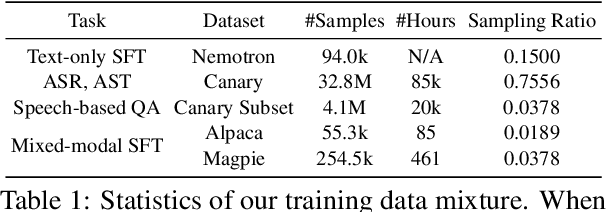
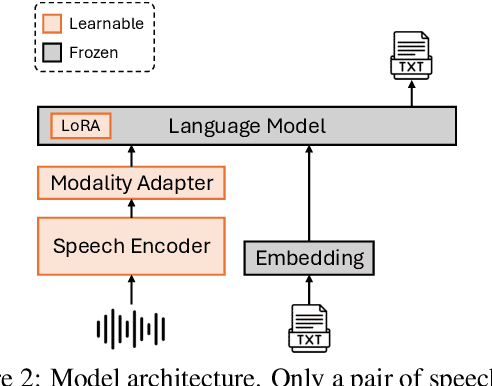
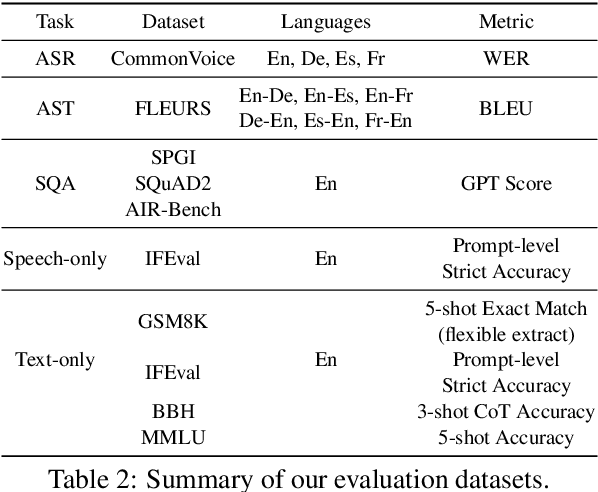
Recent studies have augmented large language models (LLMs) with speech capabilities, leading to the development of speech language models (SpeechLMs). Earlier SpeechLMs focused on single-turn speech-based question answering (QA), where user input comprised a speech context and a text question. More recent studies have extended this to multi-turn conversations, though they often require complex, multi-stage supervised fine-tuning (SFT) with diverse data. Another critical challenge with SpeechLMs is catastrophic forgetting-where models optimized for speech tasks suffer significant degradation in text-only performance. To mitigate these issues, we propose a novel single-stage joint speech-text SFT approach on the low-rank adaptation (LoRA) of the LLM backbone. Our joint SFT combines text-only SFT data with three types of speech-related data: speech recognition and translation, speech-based QA, and mixed-modal SFT. Compared to previous SpeechLMs with 7B or 13B parameters, our 3B model demonstrates superior performance across various speech benchmarks while preserving the original capabilities on text-only tasks. Furthermore, our model shows emergent abilities of effectively handling previously unseen prompts and tasks, including multi-turn, mixed-modal inputs.