 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint prediction of truecasing and punctuation for conversational speech in low-resource scenarios
Paper and Code
Sep 13, 2021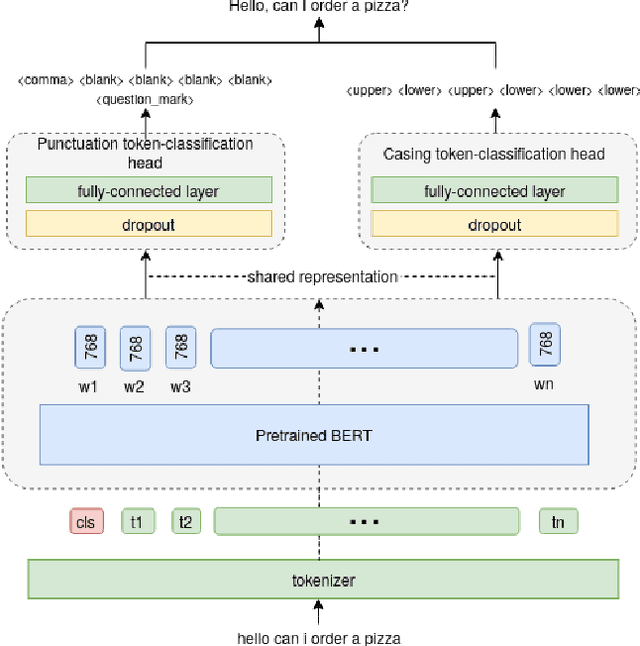
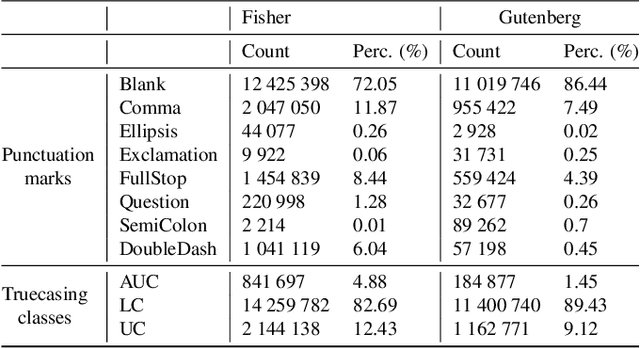
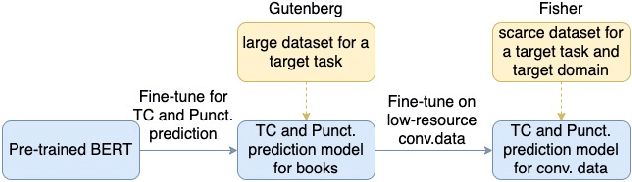
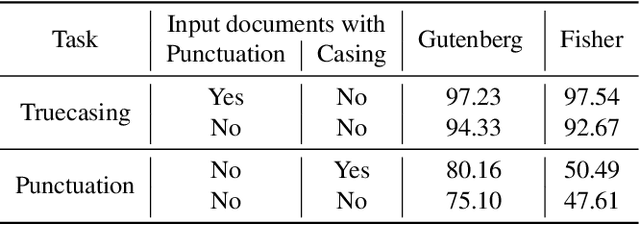
Capitalization and punctuation are important cues for comprehending written texts and conversational transcripts. Yet, many ASR systems do not produce punctuated and case-formatted speech transcripts. We propose to use a multi-task system that can exploit the relations between casing and punctuation to improve their prediction performance. Whereas text data for predicting punctuation and truecasing is seemingly abundant, we argue that written text resources are inadequate as training data for conversational models. We quantify the mismatch between written and conversational text domains by comparing the joint distributions of punctuation and word cases, and by testing our model cross-domain. Further, we show that by training the model in the written text domain and then transfer learning to conversations, we can achieve reasonable performance with less data.