 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopyPaste: An Augmentation Method for Speech Emotion Recognition
Paper and Code
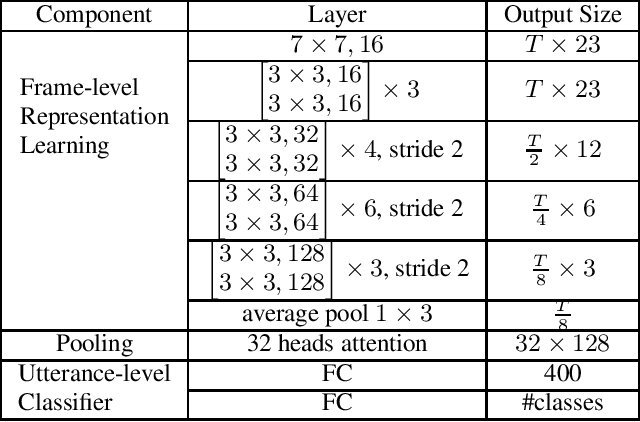
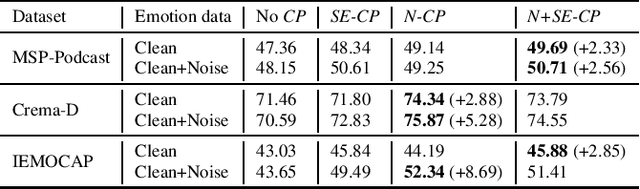

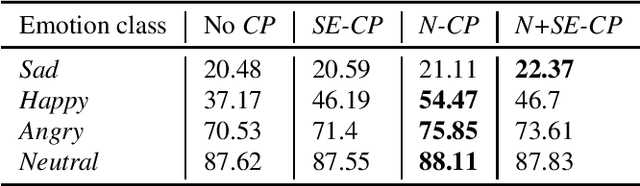
Data augmentation is a widely used strategy for training robust machine learning models. It partially alleviates the problem of limited data for tasks like speech emotion recognition (SER), where collecting data is expensive and challenging. This study proposes CopyPaste, a perceptually motivated novel augmentation procedure for SER. Assuming that the presence of emotions other than neutral dictates a speaker's overall perceived emotion in a recording, concatenation of an emotional (emotion E) and a neutral utterance can still be labeled with emotion E. We hypothesize that SER performance can be improved using these concatenated utterances in model training. To verify this, three CopyPaste schemes are tested on two deep learning models: one trained independently and another using transfer learning from an x-vector model, a speaker recognition model. We observed that all three CopyPaste schemes improve SER performance on all the three datasets considered: MSP-Podcast, Crema-D, and IEMOCAP. Additionally, CopyPaste performs better than noise augmentation and, using them together improves the SER performance further. Our experiments on noisy test sets suggested that CopyPaste is effective even in noisy test conditions.