 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Helps Transformers Recognize Conversational Structure? Importance of Context, Punctuation, and Labels in Dialog Act Recognition
Paper and Code

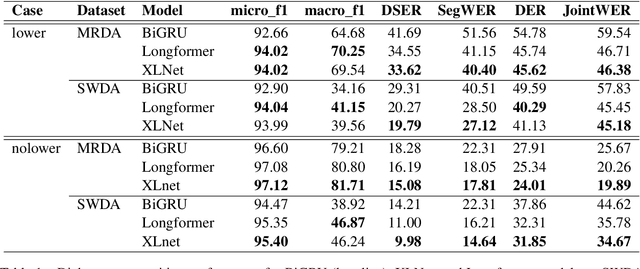
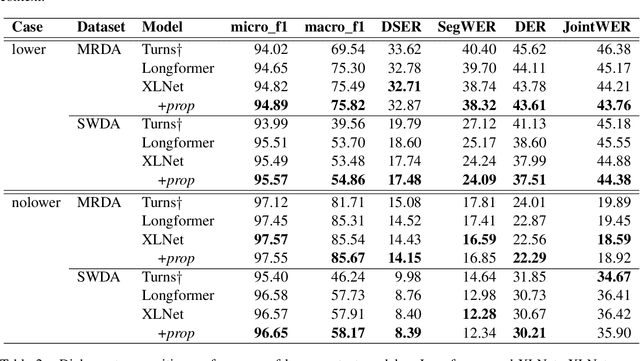
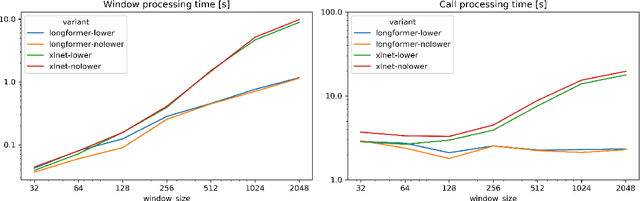
Dialog acts can be interpreted as the atomic units of a conversation, more fine-grained than utterances, characterized by a specific communicative function. The ability to structure a conversational transcript as a sequence of dialog acts -- dialog act recognition, including the segmentation -- is critical for understanding dialog. We apply two pre-trained transformer models, XLNet and Longformer, to this task in English and achieve strong results on Switchboard Dialog Act and Meeting Recorder Dialog Act corpora with dialog act segmentation error rates (DSER) of 8.4% and 14.2%. To understand the key factors affecting dialog act recognition, we perform a comparative analysis of models trained under different conditions. We find that the inclusion of a broader conversational context helps disambiguate many dialog act classes, especially those infrequent in the training data. The presence of punctuation in the transcripts has a massive effect on the models' performance, and a detailed analysis reveals specific segmentation patterns observed in its absence. Finally, we find that the label set specificity does not affect dialog act segmentation performance. These findings have significant practical implications for spoken language understanding applications that depend heavily on a good-quality segmentation being available.