 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacking Misinformation Detection Using Adversarial Examples Generated by Language Models
Paper and Code
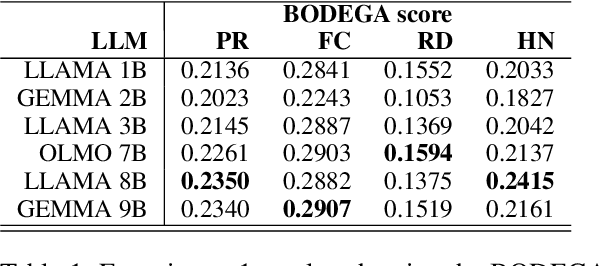

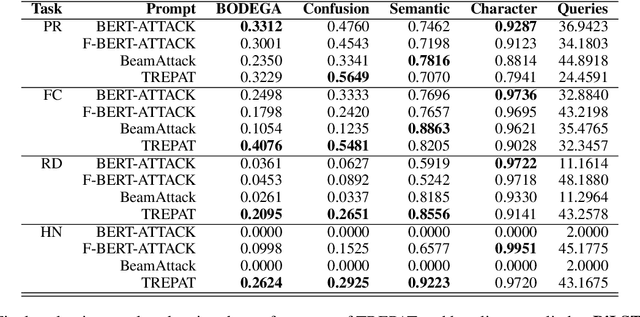
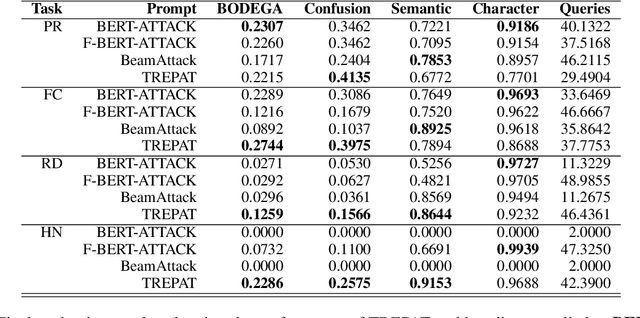
We investigate the challenge of generating adversarial examples to test the robustness of text classification algorithms detecting low-credibility content, including propaganda, false claims, rumours and hyperpartisan news. We focus on simulation of content moderation by setting realistic limits on the number of queries an attacker is allowed to attempt. Within our solution (TREPAT), initial rephrasings are generated by large language models with prompts inspired by meaning-preserving NLP tasks, e.g. text simplification and style transfer. Subsequently, these modifications are decomposed into small changes, applied through beam search procedure until the victim classifier changes its decision. The evaluation confirms the superiority of our approach in the constrained scenario, especially in case of long input text (news articles), where exhaustive search is not feasible.