 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Transformers Predict Vibrations?
Feb 16, 2024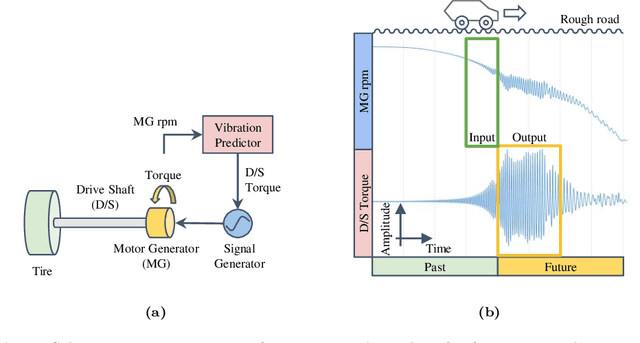

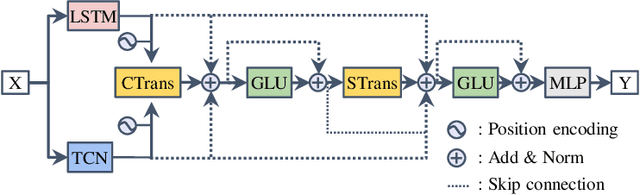
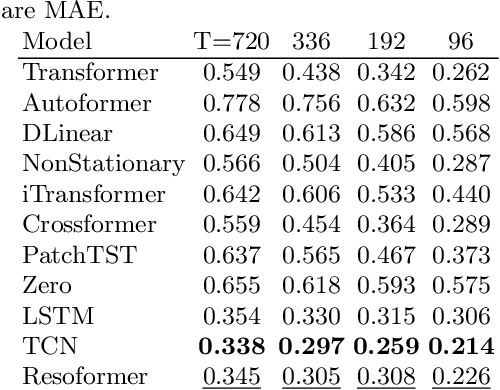
Highly accurate time-series vibration prediction is an important research issue for electric vehicles (EVs). EVs often experience vibrations when driving on rough terrains, known as torsional resonance. This resonance, caused by the interaction between motor and tire vibrations, puts excessive loads on the vehicle's drive shaft. However, current damping technologies only detect resonance after the vibration amplitude of the drive shaft torque reaches a certain threshold, leading to significant loads on the shaft at the time of detection. In this study, we propose a novel approach to address this issue by introducing Resoformer, a transformer-based model for predicting torsional resonance. Resoformer utilizes time-series of the motor rotation speed as input and predicts the amplitude of torsional vibration at a specified quantile occurring in the shaft after the input series. By calculating the attention between recursive and convolutional features extracted from the measured data points, Resoformer improves the accuracy of vibration forecasting. To evaluate the model, we use a vibration dataset called VIBES (Dataset for Forecasting Vibration Transition in EVs), consisting of 2,600 simulator-generated vibration sequences. Our experiments, conducted on strong baselines built on the VIBES dataset, demonstrate that Resoformer achieves state-of-the-art results. In conclusion, our study answers the question "Can Transformers Forecast Vibrations?" While traditional transformer architectures show low performance in forecasting torsional resonance waves, our findings indicate that combining recurrent neural network and temporal convolutional network using the transformer architecture improves the accuracy of long-term vibration forecasting.
Analyzing Research Trends in Inorganic Materials Literature Using NLP
Jun 27, 2021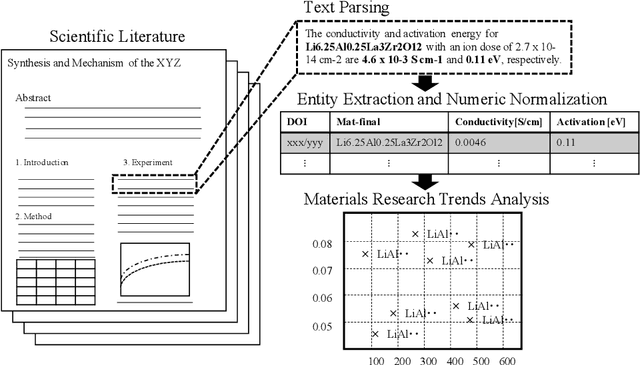
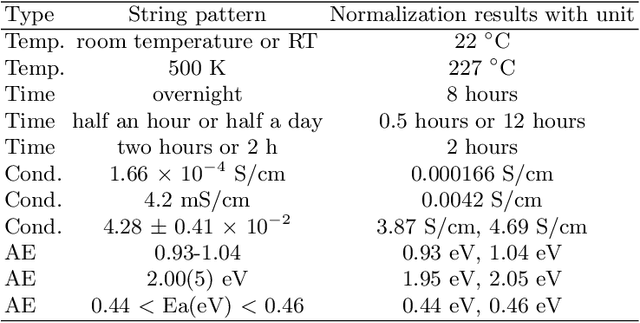
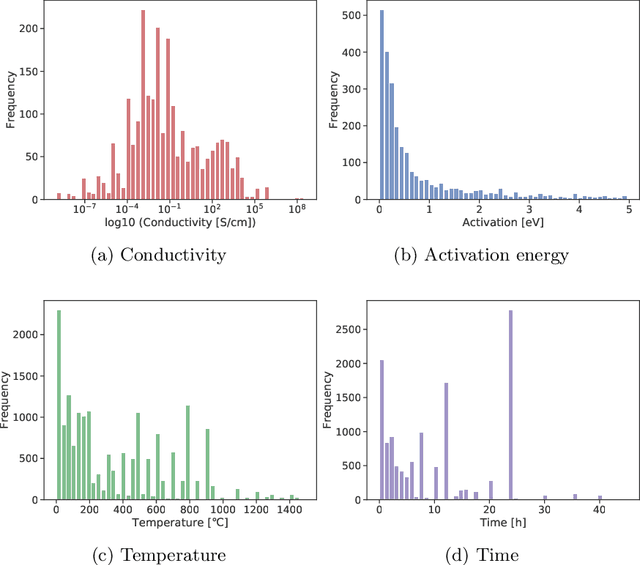

In the field of inorganic materials science, there is a growing demand to extract knowledge such as physical properties and synthesis processes of materials by machine-reading a large number of papers. This is because materials researchers refer to many papers in order to come up with promising terms of experiments for material synthesis. However, there are only a few systems that can extract material names and their properties. This study proposes a large-scale natural language processing (NLP) pipeline for extracting material names and properties from materials science literature to enable the search and retrieval of results in materials science. Therefore, we propose a label definition for extracting material names and properties and accordingly build a corpus containing 836 annotated paragraphs extracted from 301 papers for training a named entity recognition (NER) model. Experimental results demonstrate the utility of this NER model; it achieves successful extraction with a micro-F1 score of 78.1%. To demonstrate the efficacy of our approach, we present a thorough evaluation on a real-world automatically annotated corpus by applying our trained NER model to 12,895 materials science papers. We analyze the trend in materials science by visualizing the outputs of the NLP pipeline. For example, the country-by-year analysis indicates that in recent years, the number of papers on "MoS2," a material used in perovskite solar cells, has been increasing rapidly in China but decreasing in the United States. Further, according to the conditions-by-year analysis, the processing temperature of the catalyst material "PEDOT:PSS" is shifting below 200 degree, and the number of reports with a processing time exceeding 5 h is increasing slightly.
Annotating and Extracting Synthesis Process of All-Solid-State Batteries from Scientific Literature
Feb 18, 2020
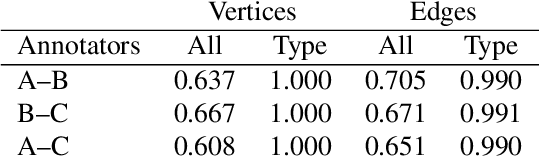
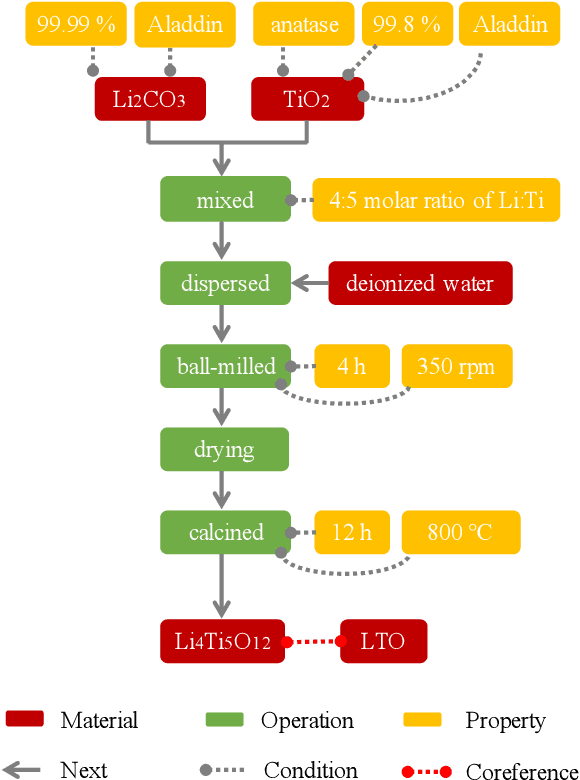

The synthesis process is essential for achieving computational experiment design in the field of inorganic materials chemistry. In this work, we present a novel corpus of the synthesis process for all-solid-state batteries and an automated machine reading system for extracting the synthesis processes buried in the scientific literature. We define the representation of the synthesis processes using flow graphs, and create a corpus from the experimental sections of 243 papers. The automated machine-reading system is developed by a deep learning-based sequence tagger and simple heuristic rule-based relation extractor. Our experimental results demonstrate that the sequence tagger with the optimal setting can detect the entities with a macro-averaged F1 score of 0.826, while the rule-based relation extractor can achieve high performance with a macro-averaged F1 score of 0.887.