 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagic for the Age of Quantized DNNs
Mar 22, 2024Recently, the number of parameters in DNNs has explosively increased, as exemplified by LLMs (Large Language Models), making inference on small-scale computers more difficult. Model compression technology is, therefore, essential for integration into products. In this paper, we propose a method of quantization-aware training. We introduce a novel normalization (Layer-Batch Normalization) that is independent of the mini-batch size and does not require any additional computation cost during inference. Then, we quantize the weights by the scaled round-clip function with the weight standardization. We also quantize activation functions using the same function and apply surrogate gradients to train the model with both quantized weights and the quantized activation functions. We call this method Magic for the age of Quantised DNNs (MaQD). Experimental results show that our quantization method can be achieved with minimal accuracy degradation.
Upper Bound of Bayesian Generalization Error in Partial Concept Bottleneck Model (CBM): Partial CBM outperforms naive CBM
Mar 14, 2024Concept Bottleneck Model (CBM) is a methods for explaining neural networks. In CBM, concepts which correspond to reasons of outputs are inserted in the last intermediate layer as observed values. It is expected that we can interpret the relationship between the output and concept similar to linear regression. However, this interpretation requires observing all concepts and decreases the generalization performance of neural networks. Partial CBM (PCBM), which uses partially observed concepts, has been devised to resolve these difficulties. Although some numerical experiments suggest that the generalization performance of PCBMs is almost as high as that of the original neural networks, the theoretical behavior of its generalization error has not been yet clarified since PCBM is singular statistical model. In this paper, we reveal the Bayesian generalization error in PCBM with a three-layered and linear architecture. The result indcates that the structure of partially observed concepts decreases the Bayesian generalization error compared with that of CBM (full-observed concepts).
Can Transformers Predict Vibrations?
Feb 16, 2024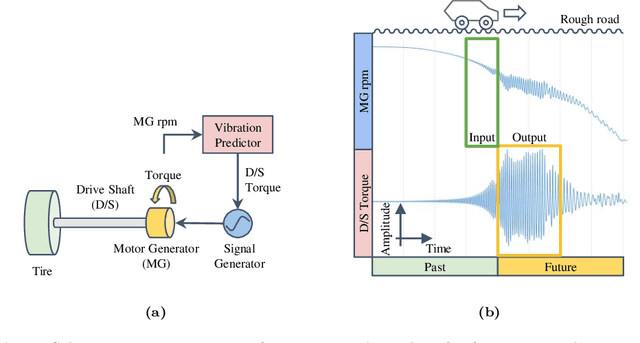

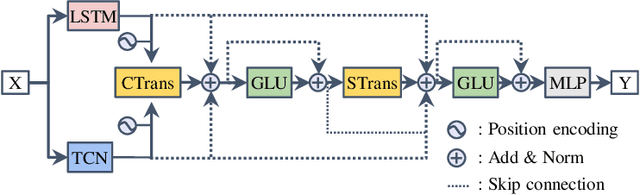
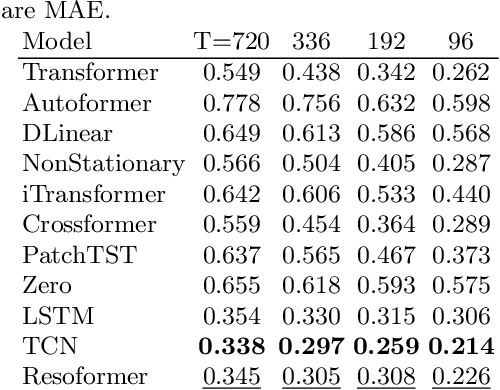
Highly accurate time-series vibration prediction is an important research issue for electric vehicles (EVs). EVs often experience vibrations when driving on rough terrains, known as torsional resonance. This resonance, caused by the interaction between motor and tire vibrations, puts excessive loads on the vehicle's drive shaft. However, current damping technologies only detect resonance after the vibration amplitude of the drive shaft torque reaches a certain threshold, leading to significant loads on the shaft at the time of detection. In this study, we propose a novel approach to address this issue by introducing Resoformer, a transformer-based model for predicting torsional resonance. Resoformer utilizes time-series of the motor rotation speed as input and predicts the amplitude of torsional vibration at a specified quantile occurring in the shaft after the input series. By calculating the attention between recursive and convolutional features extracted from the measured data points, Resoformer improves the accuracy of vibration forecasting. To evaluate the model, we use a vibration dataset called VIBES (Dataset for Forecasting Vibration Transition in EVs), consisting of 2,600 simulator-generated vibration sequences. Our experiments, conducted on strong baselines built on the VIBES dataset, demonstrate that Resoformer achieves state-of-the-art results. In conclusion, our study answers the question "Can Transformers Forecast Vibrations?" While traditional transformer architectures show low performance in forecasting torsional resonance waves, our findings indicate that combining recurrent neural network and temporal convolutional network using the transformer architecture improves the accuracy of long-term vibration forecasting.
Convergences for Minimax Optimization Problems over Infinite-Dimensional Spaces Towards Stability in Adversarial Training
Dec 02, 2023Training neural networks that require adversarial optimization, such as generative adversarial networks (GANs) and unsupervised domain adaptations (UDAs), suffers from instability. This instability problem comes from the difficulty of the minimax optimization, and there have been various approaches in GANs and UDAs to overcome this problem. In this study, we tackle this problem theoretically through a functional analysis. Specifically, we show the convergence property of the minimax problem by the gradient descent over the infinite-dimensional spaces of continuous functions and probability measures under certain conditions. Using this setting, we can discuss GANs and UDAs comprehensively, which have been studied independently. In addition, we show that the conditions necessary for the convergence property are interpreted as stabilization techniques of adversarial training such as the spectral normalization and the gradient penalty.
Spike Accumulation Forwarding for Effective Training of Spiking Neural Networks
Oct 16, 2023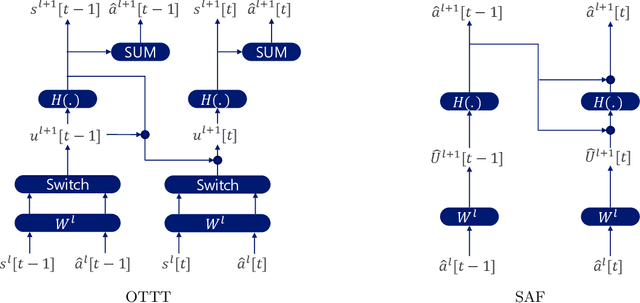
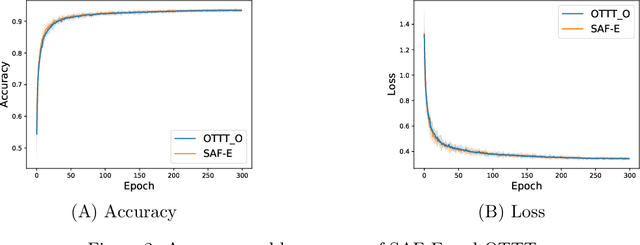
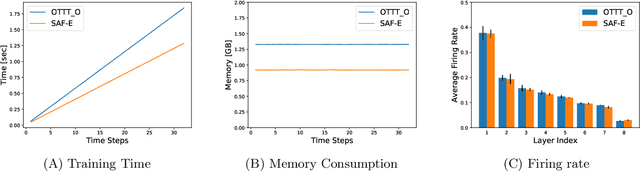
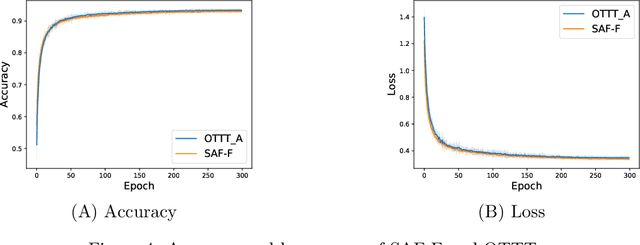
In this article, we propose a new paradigm for training spiking neural networks (SNNs), spike accumulation forwarding (SAF). It is known that SNNs are energy-efficient but difficult to train. Consequently, many researchers have proposed various methods to solve this problem, among which online training through time (OTTT) is a method that allows inferring at each time step while suppressing the memory cost. However, to compute efficiently on GPUs, OTTT requires operations with spike trains and weighted summation of spike trains during forwarding. In addition, OTTT has shown a relationship with the Spike Representation, an alternative training method, though theoretical agreement with Spike Representation has yet to be proven. Our proposed method can solve these problems; namely, SAF can halve the number of operations during the forward process, and it can be theoretically proven that SAF is consistent with the Spike Representation and OTTT, respectively. Furthermore, we confirmed the above contents through experiments and showed that it is possible to reduce memory and training time while maintaining accuracy.
Bayesian Generalization Error in Linear Neural Networks with Concept Bottleneck Structure and Multitask Formulation
Mar 16, 2023Concept bottleneck model (CBM) is a ubiquitous method that can interpret neural networks using concepts. In CBM, concepts are inserted between the output layer and the last intermediate layer as observable values. This helps in understanding the reason behind the outputs generated by the neural networks: the weights corresponding to the concepts from the last hidden layer to the output layer. However, it has not yet been possible to understand the behavior of the generalization error in CBM since a neural network is a singular statistical model in general. When the model is singular, a one to one map from the parameters to probability distributions cannot be created. This non-identifiability makes it difficult to analyze the generalization performance. In this study, we mathematically clarify the Bayesian generalization error and free energy of CBM when its architecture is three-layered linear neural networks. We also consider a multitask problem where the neural network outputs not only the original output but also the concepts. The results show that CBM drastically changes the behavior of the parameter region and the Bayesian generalization error in three-layered linear neural networks as compared with the standard version, whereas the multitask formulation does not.
Spiking Synaptic Penalty: Appropriate Penalty Term for Energy-Efficient Spiking Neural Networks
Feb 03, 2023Spiking neural networks (SNNs) are energy-efficient neural networks because of their spiking nature. However, as the spike firing rate of SNNs increases, the energy consumption does as well, and thus, the advantage of SNNs diminishes. Here, we tackle this problem by introducing a novel penalty term for the spiking activity into the objective function in the training phase. Our method is designed so as to optimize the energy consumption metric directly without modifying the network architecture. Therefore, the proposed method can reduce the energy consumption more than other methods while maintaining the accuracy. We conducted experiments for image classification tasks, and the results indicate the effectiveness of the proposed method, which mitigates the dilemma of the energy--accuracy trade-off.
C-SENN: Contrastive Self-Explaining Neural Network
Jun 27, 2022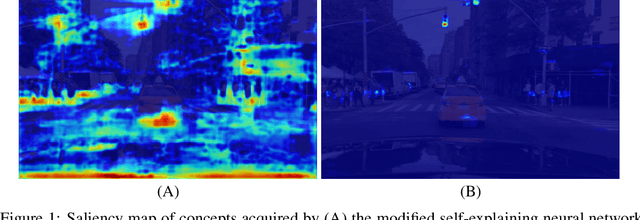



In this study, we use a self-explaining neural network (SENN), which learns unsupervised concepts, to acquire concepts that are easy for people to understand automatically. In concept learning, the hidden layer retains verbalizable features relevant to the output, which is crucial when adapting to real-world environments where explanations are required. However, it is known that the interpretability of concepts output by SENN is reduced in general settings, such as autonomous driving scenarios. Thus, this study combines contrastive learning with concept learning to improve the readability of concepts and the accuracy of tasks. We call this model Contrastive Self-Explaining Neural Network (C-SENN).
Rethinking the role of normalization and residual blocks for spiking neural networks
Mar 03, 2022



Biologically inspired spiking neural networks (SNNs) are widely used to realize ultralow-power energy consumption. However, deep SNNs are not easy to train due to the excessive firing of spiking neurons in the hidden layers. To tackle this problem, we propose a novel but simple normalization technique called postsynaptic potential normalization. This normalization removes the subtraction term from the standard normalization and uses the second raw moment instead of the variance as the division term. The spike firing can be controlled, enabling the training to proceed appropriating, by conducting this simple normalization to the postsynaptic potential. The experimental results show that SNNs with our normalization outperformed other models using other normalizations. Furthermore, through the pre-activation residual blocks, the proposed model can train with more than 100 layers without other special techniques dedicated to SNNs.
Concept Bottleneck Model with Additional Unsupervised Concepts
Feb 03, 2022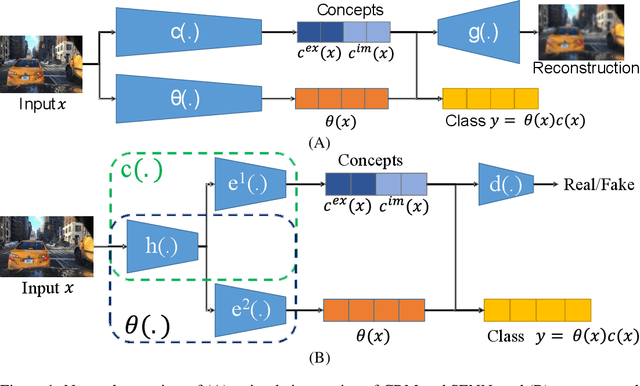
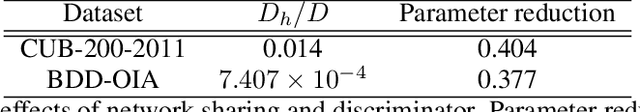
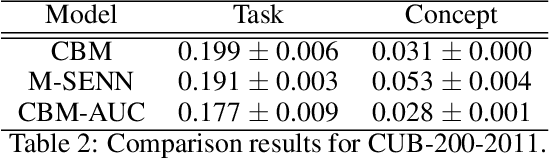
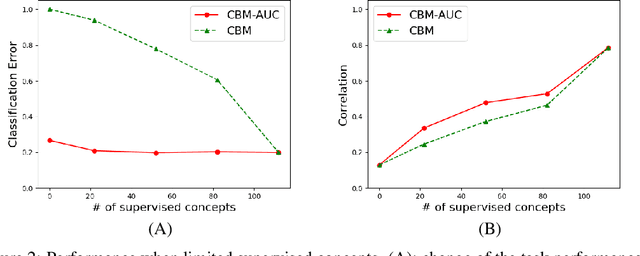
With the increasing demands for accountability, interpretability is becoming an essential capability for real-world AI applications. However, most methods utilize post-hoc approaches rather than training the interpretable model. In this article, we propose a novel interpretable model based on the concept bottleneck model (CBM). CBM uses concept labels to train an intermediate layer as the additional visible layer. However, because the number of concept labels restricts the dimension of this layer, it is difficult to obtain high accuracy with a small number of labels. To address this issue, we integrate supervised concepts with unsupervised ones trained with self-explaining neural networks (SENNs). By seamlessly training these two types of concepts while reducing the amount of computation, we can obtain both supervised and unsupervised concepts simultaneously, even for large-sized images. We refer to the proposed model as the concept bottleneck model with additional unsupervised concepts (CBM-AUC). We experimentally confirmed that the proposed model outperformed CBM and SENN. We also visualized the saliency map of each concept and confirmed that it was consistent with the semantic meanings.