 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagic for the Age of Quantized DNNs
Mar 22, 2024Recently, the number of parameters in DNNs has explosively increased, as exemplified by LLMs (Large Language Models), making inference on small-scale computers more difficult. Model compression technology is, therefore, essential for integration into products. In this paper, we propose a method of quantization-aware training. We introduce a novel normalization (Layer-Batch Normalization) that is independent of the mini-batch size and does not require any additional computation cost during inference. Then, we quantize the weights by the scaled round-clip function with the weight standardization. We also quantize activation functions using the same function and apply surrogate gradients to train the model with both quantized weights and the quantized activation functions. We call this method Magic for the age of Quantised DNNs (MaQD). Experimental results show that our quantization method can be achieved with minimal accuracy degradation.
Spike Accumulation Forwarding for Effective Training of Spiking Neural Networks
Oct 16, 2023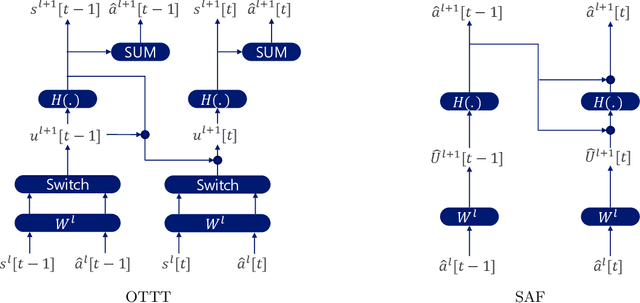
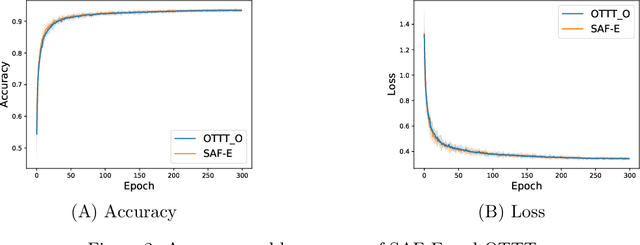
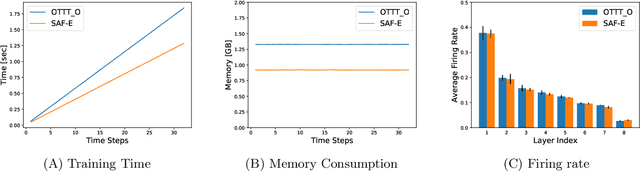
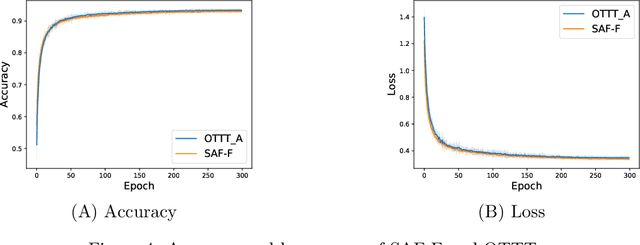
In this article, we propose a new paradigm for training spiking neural networks (SNNs), spike accumulation forwarding (SAF). It is known that SNNs are energy-efficient but difficult to train. Consequently, many researchers have proposed various methods to solve this problem, among which online training through time (OTTT) is a method that allows inferring at each time step while suppressing the memory cost. However, to compute efficiently on GPUs, OTTT requires operations with spike trains and weighted summation of spike trains during forwarding. In addition, OTTT has shown a relationship with the Spike Representation, an alternative training method, though theoretical agreement with Spike Representation has yet to be proven. Our proposed method can solve these problems; namely, SAF can halve the number of operations during the forward process, and it can be theoretically proven that SAF is consistent with the Spike Representation and OTTT, respectively. Furthermore, we confirmed the above contents through experiments and showed that it is possible to reduce memory and training time while maintaining accuracy.
Spiking Synaptic Penalty: Appropriate Penalty Term for Energy-Efficient Spiking Neural Networks
Feb 03, 2023Spiking neural networks (SNNs) are energy-efficient neural networks because of their spiking nature. However, as the spike firing rate of SNNs increases, the energy consumption does as well, and thus, the advantage of SNNs diminishes. Here, we tackle this problem by introducing a novel penalty term for the spiking activity into the objective function in the training phase. Our method is designed so as to optimize the energy consumption metric directly without modifying the network architecture. Therefore, the proposed method can reduce the energy consumption more than other methods while maintaining the accuracy. We conducted experiments for image classification tasks, and the results indicate the effectiveness of the proposed method, which mitigates the dilemma of the energy--accuracy trade-off.
Rethinking the role of normalization and residual blocks for spiking neural networks
Mar 03, 2022



Biologically inspired spiking neural networks (SNNs) are widely used to realize ultralow-power energy consumption. However, deep SNNs are not easy to train due to the excessive firing of spiking neurons in the hidden layers. To tackle this problem, we propose a novel but simple normalization technique called postsynaptic potential normalization. This normalization removes the subtraction term from the standard normalization and uses the second raw moment instead of the variance as the division term. The spike firing can be controlled, enabling the training to proceed appropriating, by conducting this simple normalization to the postsynaptic potential. The experimental results show that SNNs with our normalization outperformed other models using other normalizations. Furthermore, through the pre-activation residual blocks, the proposed model can train with more than 100 layers without other special techniques dedicated to SNNs.
S$^2$NN: Time Step Reduction of Spiking Surrogate Gradients for Training Energy Efficient Single-Step Neural Networks
Jan 26, 2022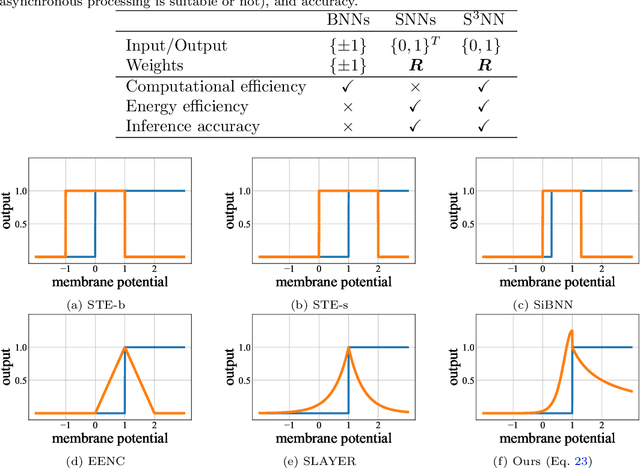
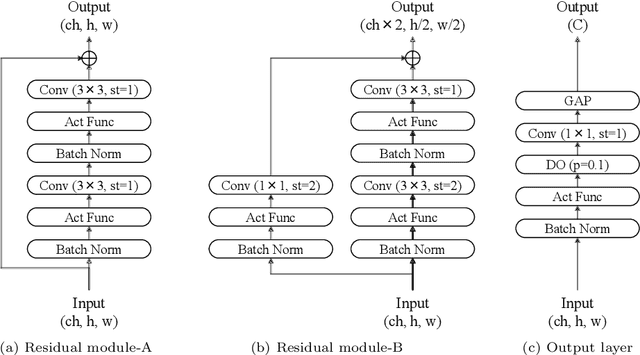

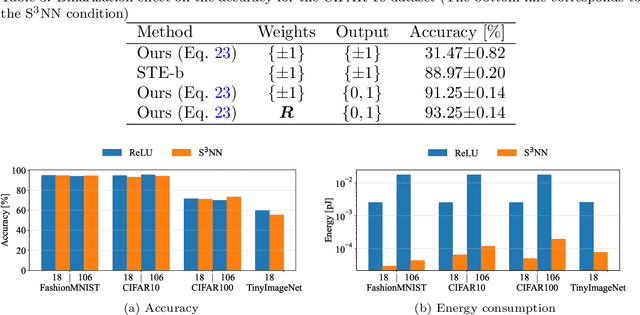
As the scales of neural networks increase, techniques that enable them to run with low computational cost and energy efficiency are required. From such demands, various efficient neural network paradigms, such as spiking neural networks (SNNs) or binary neural networks (BNNs), have been proposed. However, they have sticky drawbacks, such as degraded inference accuracy and latency. To solve these problems, we propose a single-step neural network (S$^2$NN), an energy-efficient neural network with low computational cost and high precision. The proposed S$^2$NN processes the information between hidden layers by spikes as SNNs. Nevertheless, it has no temporal dimension so that there is no latency within training and inference phases as BNNs. Thus, the proposed S$^2$NN has a lower computational cost than SNNs that require time-series processing. However, S$^2$NN cannot adopt na\"{i}ve backpropagation algorithms due to the non-differentiability nature of spikes. We deduce a suitable neuron model by reducing the surrogate gradient for multi-time step SNNs to a single-time step. We experimentally demonstrated that the obtained neuron model enables S$^2$NN to train more accurately and energy-efficiently than existing neuron models for SNNs and BNNs. We also showed that the proposed S$^2$NN could achieve comparable accuracy to full-precision networks while being highly energy-efficient.
Spectral Pruning for Recurrent Neural Networks
May 23, 2021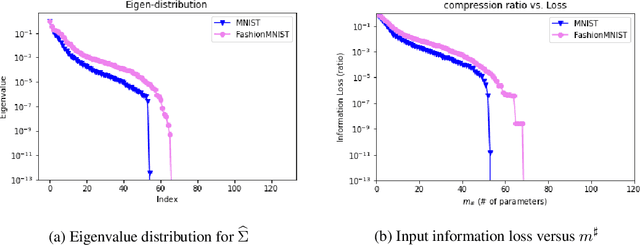
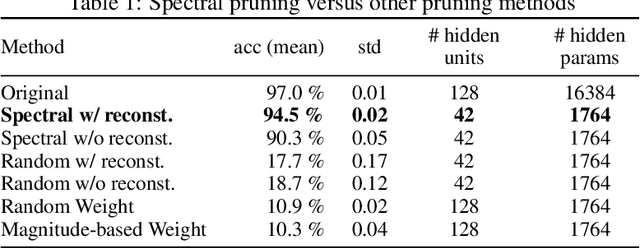
Pruning techniques for neural networks with a recurrent architecture, such as the recurrent neural network (RNN), are strongly desired for their application to edge-computing devices. However, the recurrent architecture is generally not robust to pruning because even small pruning causes accumulation error and the total error increases significantly over time. In this paper, we propose an appropriate pruning algorithm for RNNs inspired by "spectral pruning", and provide the generalization error bounds for compressed RNNs. We also provide numerical experiments to demonstrate our theoretical results and show the effectiveness of our pruning method compared with existing methods.