 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation theory for 1-Lipschitz ResNets
May 17, 20251-Lipschitz neural networks are fundamental for generative modelling, inverse problems, and robust classifiers. In this paper, we focus on 1-Lipschitz residual networks (ResNets) based on explicit Euler steps of negative gradient flows and study their approximation capabilities. Leveraging the Restricted Stone-Weierstrass Theorem, we first show that these 1-Lipschitz ResNets are dense in the set of scalar 1-Lipschitz functions on any compact domain when width and depth are allowed to grow. We also show that these networks can exactly represent scalar piecewise affine 1-Lipschitz functions. We then prove a stronger statement: by inserting norm-constrained linear maps between the residual blocks, the same density holds when the hidden width is fixed. Because every layer obeys simple norm constraints, the resulting models can be trained with off-the-shelf optimisers. This paper provides the first universal approximation guarantees for 1-Lipschitz ResNets, laying a rigorous foundation for their practical use.
Kolmogorov-Arnold Networks: Approximation and Learning Guarantees for Functions and their Derivatives
Apr 21, 2025



Inspired by the Kolmogorov-Arnold superposition theorem, Kolmogorov-Arnold Networks (KANs) have recently emerged as an improved backbone for most deep learning frameworks, promising more adaptivity than their multilayer perception (MLP) predecessor by allowing for trainable spline-based activation functions. In this paper, we probe the theoretical foundations of the KAN architecture by showing that it can optimally approximate any Besov function in $B^{s}_{p,q}(\mathcal{X})$ on a bounded open, or even fractal, domain $\mathcal{X}$ in $\mathbb{R}^d$ at the optimal approximation rate with respect to any weaker Besov norm $B^{\alpha}_{p,q}(\mathcal{X})$; where $\alpha < s$. We complement our approximation guarantee with a dimension-free estimate on the sample complexity of a residual KAN model when learning a function of Besov regularity from $N$ i.i.d. noiseless samples. Our KAN architecture incorporates contemporary deep learning wisdom by leveraging residual/skip connections between layers.
Is In-Context Universality Enough? MLPs are Also Universal In-Context
Feb 05, 2025

The success of transformers is often linked to their ability to perform in-context learning. Recent work shows that transformers are universal in context, capable of approximating any real-valued continuous function of a context (a probability measure over $\mathcal{X}\subseteq \mathbb{R}^d$) and a query $x\in \mathcal{X}$. This raises the question: Does in-context universality explain their advantage over classical models? We answer this in the negative by proving that MLPs with trainable activation functions are also universal in-context. This suggests the transformer's success is likely due to other factors like inductive bias or training stability.
Can neural operators always be continuously discretized?
Dec 04, 2024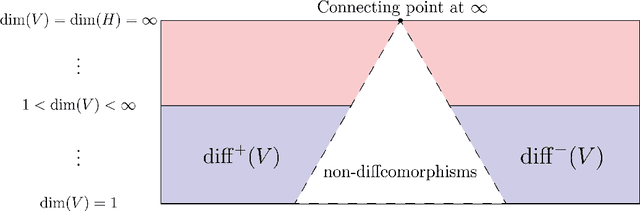
We consider the problem of discretization of neural operators between Hilbert spaces in a general framework including skip connections. We focus on bijective neural operators through the lens of diffeomorphisms in infinite dimensions. Framed using category theory, we give a no-go theorem that shows that diffeomorphisms between Hilbert spaces or Hilbert manifolds may not admit any continuous approximations by diffeomorphisms on finite-dimensional spaces, even if the approximations are nonlinear. The natural way out is the introduction of strongly monotone diffeomorphisms and layerwise strongly monotone neural operators which have continuous approximations by strongly monotone diffeomorphisms on finite-dimensional spaces. For these, one can guarantee discretization invariance, while ensuring that finite-dimensional approximations converge not only as sequences of functions, but that their representations converge in a suitable sense as well. Finally, we show that bilipschitz neural operators may always be written in the form of an alternating composition of strongly monotone neural operators, plus a simple isometry. Thus we realize a rigorous platform for discretization of a generalization of a neural operator. We also show that neural operators of this type may be approximated through the composition of finite-rank residual neural operators, where each block is strongly monotone, and may be inverted locally via iteration. We conclude by providing a quantitative approximation result for the discretization of general bilipschitz neural operators.
Simultaneously Solving FBSDEs with Neural Operators of Logarithmic Depth, Constant Width, and Sub-Linear Rank
Oct 18, 2024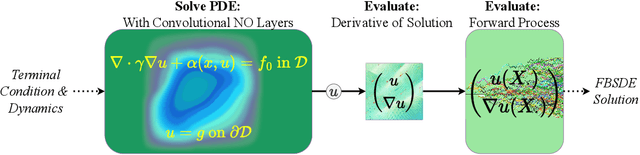

Forward-backwards stochastic differential equations (FBSDEs) are central in optimal control, game theory, economics, and mathematical finance. Unfortunately, the available FBSDE solvers operate on \textit{individual} FBSDEs, meaning that they cannot provide a computationally feasible strategy for solving large families of FBSDEs as these solvers must be re-run several times. \textit{Neural operators} (NOs) offer an alternative approach for \textit{simultaneously solving} large families of FBSDEs by directly approximating the solution operator mapping \textit{inputs:} terminal conditions and dynamics of the backwards process to \textit{outputs:} solutions to the associated FBSDE. Though universal approximation theorems (UATs) guarantee the existence of such NOs, these NOs are unrealistically large. We confirm that ``small'' NOs can uniformly approximate the solution operator to structured families of FBSDEs with random terminal time, uniformly on suitable compact sets determined by Sobolev norms, to any prescribed error $\varepsilon>0$ using a depth of $\mathcal{O}(\log(1/\varepsilon))$, a width of $\mathcal{O}(1)$, and a sub-linear rank; i.e. $\mathcal{O}(1/\varepsilon^r)$ for some $r<1$. This result is rooted in our second main contribution, which shows that convolutional NOs of similar depth, width, and rank can approximate the solution operator to a broad class of Elliptic PDEs. A key insight here is that the convolutional layers of our NO can efficiently encode the Green's function associated to the Elliptic PDEs linked to our FBSDEs. A byproduct of our analysis is the first theoretical justification for the benefit of lifting channels in NOs: they exponentially decelerate the growth rate of the NO's rank.
Quantitative Approximation for Neural Operators in Nonlinear Parabolic Equations
Oct 03, 2024Neural operators serve as universal approximators for general continuous operators. In this paper, we derive the approximation rate of solution operators for the nonlinear parabolic partial differential equations (PDEs), contributing to the quantitative approximation theorem for solution operators of nonlinear PDEs. Our results show that neural operators can efficiently approximate these solution operators without the exponential growth in model complexity, thus strengthening the theoretical foundation of neural operators. A key insight in our proof is to transfer PDEs into the corresponding integral equations via Duahamel's principle, and to leverage the similarity between neural operators and Picard's iteration, a classical algorithm for solving PDEs. This approach is potentially generalizable beyond parabolic PDEs to a range of other equations, including the Navier-Stokes equation, nonlinear Schr\"odinger equations and nonlinear wave equations, which can be solved by Picard's iteration.
Transformers are Universal In-context Learners
Aug 02, 2024Transformers are deep architectures that define "in-context mappings" which enable predicting new tokens based on a given set of tokens (such as a prompt in NLP applications or a set of patches for vision transformers). This work studies in particular the ability of these architectures to handle an arbitrarily large number of context tokens. To mathematically and uniformly address the expressivity of these architectures, we consider the case that the mappings are conditioned on a context represented by a probability distribution of tokens (discrete for a finite number of tokens). The related notion of smoothness corresponds to continuity in terms of the Wasserstein distance between these contexts. We demonstrate that deep transformers are universal and can approximate continuous in-context mappings to arbitrary precision, uniformly over compact token domains. A key aspect of our results, compared to existing findings, is that for a fixed precision, a single transformer can operate on an arbitrary (even infinite) number of tokens. Additionally, it operates with a fixed embedding dimension of tokens (this dimension does not increase with precision) and a fixed number of heads (proportional to the dimension). The use of MLP layers between multi-head attention layers is also explicitly controlled.
Mixture of Experts Soften the Curse of Dimensionality in Operator Learning
Apr 13, 2024
In this paper, we construct a mixture of neural operators (MoNOs) between function spaces whose complexity is distributed over a network of expert neural operators (NOs), with each NO satisfying parameter scaling restrictions. Our main result is a \textit{distributed} universal approximation theorem guaranteeing that any Lipschitz non-linear operator between $L^2([0,1]^d)$ spaces can be approximated uniformly over the Sobolev unit ball therein, to any given $\varepsilon>0$ accuracy, by an MoNO while satisfying the constraint that: each expert NO has a depth, width, and rank of $\mathcal{O}(\varepsilon^{-1})$. Naturally, our result implies that the required number of experts must be large, however, each NO is guaranteed to be small enough to be loadable into the active memory of most computers for reasonable accuracies $\varepsilon$. During our analysis, we also obtain new quantitative expression rates for classical NOs approximating uniformly continuous non-linear operators uniformly on compact subsets of $L^2([0,1]^d)$.
Breaking the Curse of Dimensionality with Distributed Neural Computation
Feb 05, 2024We present a theoretical approach to overcome the curse of dimensionality using a neural computation algorithm which can be distributed across several machines. Our modular distributed deep learning paradigm, termed \textit{neural pathways}, can achieve arbitrary accuracy while only loading a small number of parameters into GPU VRAM. Formally, we prove that for every error level $\varepsilon>0$ and every Lipschitz function $f:[0,1]^n\to \mathbb{R}$, one can construct a neural pathways model which uniformly approximates $f$ to $\varepsilon$ accuracy over $[0,1]^n$ while only requiring networks of $\mathcal{O}(\varepsilon^{-1})$ parameters to be loaded in memory and $\mathcal{O}(\varepsilon^{-1}\log(\varepsilon^{-1}))$ to be loaded during the forward pass. This improves the optimal bounds for traditional non-distributed deep learning models, namely ReLU MLPs, which need $\mathcal{O}(\varepsilon^{-n/2})$ parameters to achieve the same accuracy. The only other available deep learning model that breaks the curse of dimensionality is MLPs with super-expressive activation functions. However, we demonstrate that these models have an infinite VC dimension, even with bounded depth and width restrictions, unlike the neural pathways model. This implies that only the latter generalizes. Our analysis is validated experimentally in both regression and classification tasks, demonstrating that our model exhibits superior performance compared to larger centralized benchmarks.
Convergences for Minimax Optimization Problems over Infinite-Dimensional Spaces Towards Stability in Adversarial Training
Dec 02, 2023Training neural networks that require adversarial optimization, such as generative adversarial networks (GANs) and unsupervised domain adaptations (UDAs), suffers from instability. This instability problem comes from the difficulty of the minimax optimization, and there have been various approaches in GANs and UDAs to overcome this problem. In this study, we tackle this problem theoretically through a functional analysis. Specifically, we show the convergence property of the minimax problem by the gradient descent over the infinite-dimensional spaces of continuous functions and probability measures under certain conditions. Using this setting, we can discuss GANs and UDAs comprehensively, which have been studied independently. In addition, we show that the conditions necessary for the convergence property are interpreted as stabilization techniques of adversarial training such as the spectral normalization and the gradient penalty.