 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentINDIGO: An INN-Guided Latent Diffusion Algorithm for Image Restoration
May 19, 2025There is a growing interest in the use of latent diffusion models (LDMs) for image restoration (IR) tasks due to their ability to model effectively the distribution of natural images. While significant progress has been made, there are still key challenges that need to be addressed. First, many approaches depend on a predefined degradation operator, making them ill-suited for complex or unknown degradations that deviate from standard analytical models. Second, many methods struggle to provide a stable guidance in the latent space and finally most methods convert latent representations back to the pixel domain for guidance at every sampling iteration, which significantly increases computational and memory overhead. To overcome these limitations, we introduce a wavelet-inspired invertible neural network (INN) that simulates degradations through a forward transform and reconstructs lost details via the inverse transform. We further integrate this design into a latent diffusion pipeline through two proposed approaches: LatentINDIGO-PixelINN, which operates in the pixel domain, and LatentINDIGO-LatentINN, which stays fully in the latent space to reduce complexity. Both approaches alternate between updating intermediate latent variables under the guidance of our INN and refining the INN forward model to handle unknown degradations. In addition, a regularization step preserves the proximity of latent variables to the natural image manifold. Experiments demonstrate that our algorithm achieves state-of-the-art performance on synthetic and real-world low-quality images, and can be readily adapted to arbitrary output sizes.
SING: Semantic Image Communications using Null-Space and INN-Guided Diffusion Models
Mar 16, 2025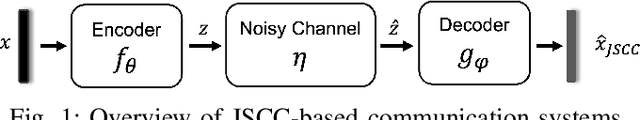
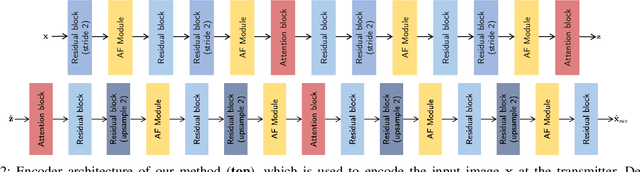

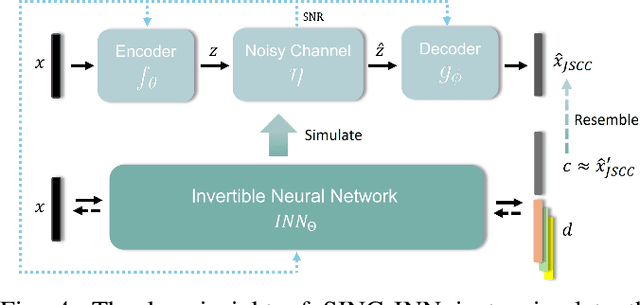
Joint source-channel coding systems based on deep neural networks (DeepJSCC) have recently demonstrated remarkable performance in wireless image transmission. Existing methods primarily focus on minimizing distortion between the transmitted image and the reconstructed version at the receiver, often overlooking perceptual quality. This can lead to severe perceptual degradation when transmitting images under extreme conditions, such as low bandwidth compression ratios (BCRs) and low signal-to-noise ratios (SNRs). In this work, we propose SING, a novel two-stage JSCC framework that formulates the recovery of high-quality source images from corrupted reconstructions as an inverse problem. Depending on the availability of information about the DeepJSCC encoder/decoder and the channel at the receiver, SING can either approximate the stochastic degradation as a linear transformation, or leverage invertible neural networks (INNs) for precise modeling. Both approaches enable the seamless integration of diffusion models into the reconstruction process, enhancing perceptual quality. Experimental results demonstrate that SING outperforms DeepJSCC and other approaches, delivering superior perceptual quality even under extremely challenging conditions, including scenarios with significant distribution mismatches between the training and test data.
INDIGO+: A Unified INN-Guided Probabilistic Diffusion Algorithm for Blind and Non-Blind Image Restoration
Jan 23, 2025



Generative diffusion models are becoming one of the most popular prior in image restoration (IR) tasks due to their remarkable ability to generate realistic natural images. Despite achieving satisfactory results, IR methods based on diffusion models present several limitations. First of all, most non-blind approaches require an analytical expression of the degradation model to guide the sampling process. Secondly, most existing blind approaches rely on families of pre-defined degradation models for training their deep networks. The above issues limit the flexibility of these approaches and so their ability to handle real-world degradation tasks. In this paper, we propose a novel INN-guided probabilistic diffusion algorithm for non-blind and blind image restoration, namely INDIGO and BlindINDIGO, which combines the merits of the perfect reconstruction property of invertible neural networks (INN) with the strong generative capabilities of pre-trained diffusion models. Specifically, we train the forward process of the INN to simulate an arbitrary degradation process and use the inverse to obtain an intermediate image that we use to guide the reverse diffusion sampling process through a gradient step. We also introduce an initialization strategy, to further improve the performance and inference speed of our algorithm. Experiments demonstrate that our algorithm obtains competitive results compared with recently leading methods both quantitatively and visually on synthetic and real-world low-quality images.
CommIN: Semantic Image Communications as an Inverse Problem with INN-Guided Diffusion Models
Oct 02, 2023Joint source-channel coding schemes based on deep neural networks (DeepJSCC) have recently achieved remarkable performance for wireless image transmission. However, these methods usually focus only on the distortion of the reconstructed signal at the receiver side with respect to the source at the transmitter side, rather than the perceptual quality of the reconstruction which carries more semantic information. As a result, severe perceptual distortion can be introduced under extreme conditions such as low bandwidth and low signal-to-noise ratio. In this work, we propose CommIN, which views the recovery of high-quality source images from degraded reconstructions as an inverse problem. To address this, CommIN combines Invertible Neural Networks (INN) with diffusion models, aiming for superior perceptual quality. Through experiments, we show that our CommIN significantly improves the perceptual quality compared to DeepJSCC under extreme conditions and outperforms other inverse problem approaches used in DeepJSCC.
INDigo: An INN-Guided Probabilistic Diffusion Algorithm for Inverse Problems
Jun 05, 2023Recently it has been shown that using diffusion models for inverse problems can lead to remarkable results. However, these approaches require a closed-form expression of the degradation model and can not support complex degradations. To overcome this limitation, we propose a method (INDigo) that combines invertible neural networks (INN) and diffusion models for general inverse problems. Specifically, we train the forward process of INN to simulate an arbitrary degradation process and use the inverse as a reconstruction process. During the diffusion sampling process, we impose an additional data-consistency step that minimizes the distance between the intermediate result and the INN-optimized result at every iteration, where the INN-optimized image is composed of the coarse information given by the observed degraded image and the details generated by the diffusion process. With the help of INN, our algorithm effectively estimates the details lost in the degradation process and is no longer limited by the requirement of knowing the closed-form expression of the degradation model. Experiments demonstrate that our algorithm obtains competitive results compared with recently leading methods both quantitatively and visually. Moreover, our algorithm performs well on more complex degradation models and real-world low-quality images.
AlignTransformer: Hierarchical Alignment of Visual Regions and Disease Tags for Medical Report Generation
Mar 18, 2022
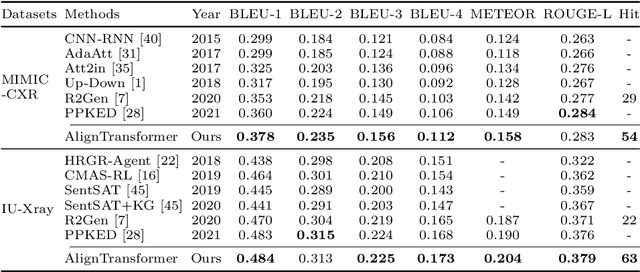
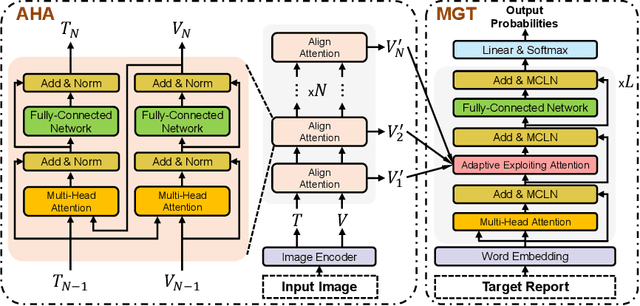
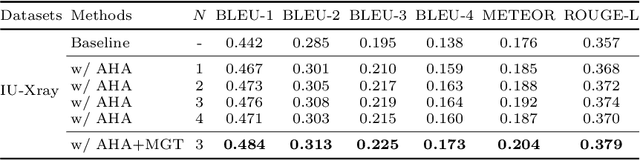
Recently, medical report generation, which aims to automatically generate a long and coherent descriptive paragraph of a given medical image, has received growing research interests. Different from the general image captioning tasks, medical report generation is more challenging for data-driven neural models. This is mainly due to 1) the serious data bias: the normal visual regions dominate the dataset over the abnormal visual regions, and 2) the very long sequence. To alleviate above two problems, we propose an AlignTransformer framework, which includes the Align Hierarchical Attention (AHA) and the Multi-Grained Transformer (MGT) modules: 1) AHA module first predicts the disease tags from the input image and then learns the multi-grained visual features by hierarchically aligning the visual regions and disease tags. The acquired disease-grounded visual features can better represent the abnormal regions of the input image, which could alleviate data bias problem; 2) MGT module effectively uses the multi-grained features and Transformer framework to generate the long medical report. The experiments on the public IU-Xray and MIMIC-CXR datasets show that the AlignTransformer can achieve results competitive with state-of-the-art methods on the two datasets. Moreover, the human evaluation conducted by professional radiologists further proves the effectiveness of our approach.
COAST: COntrollable Arbitrary-Sampling NeTwork for Compressive Sensing
Jul 15, 2021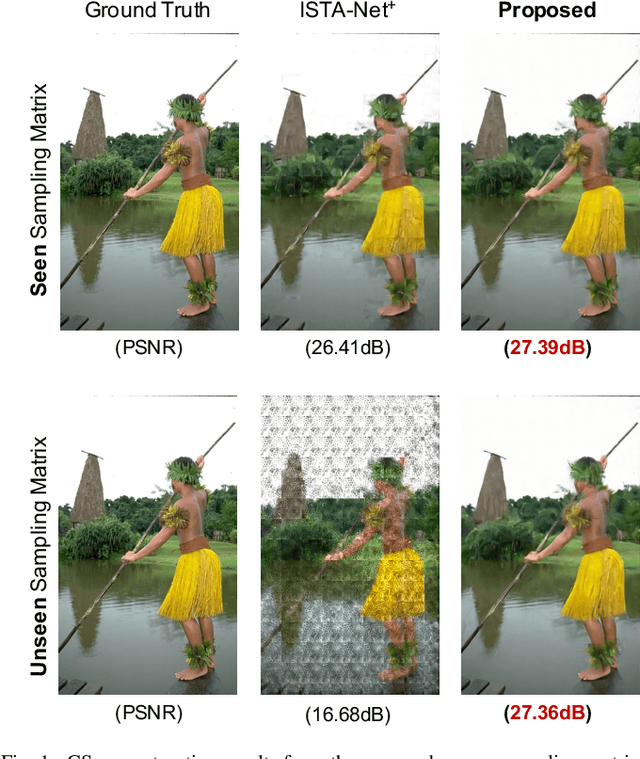



Recent deep network-based compressive sensing (CS) methods have achieved great success. However, most of them regard different sampling matrices as different independent tasks and need to train a specific model for each target sampling matrix. Such practices give rise to inefficiency in computing and suffer from poor generalization ability. In this paper, we propose a novel COntrollable Arbitrary-Sampling neTwork, dubbed COAST, to solve CS problems of arbitrary-sampling matrices (including unseen sampling matrices) with one single model. Under the optimization-inspired deep unfolding framework, our COAST exhibits good interpretability. In COAST, a random projection augmentation (RPA) strategy is proposed to promote the training diversity in the sampling space to enable arbitrary sampling, and a controllable proximal mapping module (CPMM) and a plug-and-play deblocking (PnP-D) strategy are further developed to dynamically modulate the network features and effectively eliminate the blocking artifacts, respectively. Extensive experiments on widely used benchmark datasets demonstrate that our proposed COAST is not only able to handle arbitrary sampling matrices with one single model but also to achieve state-of-the-art performance with fast speed. The source code is available on https://github.com/jianzhangcs/COAST.
* Published in IEEE Transactions on Image Processing, 2021
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021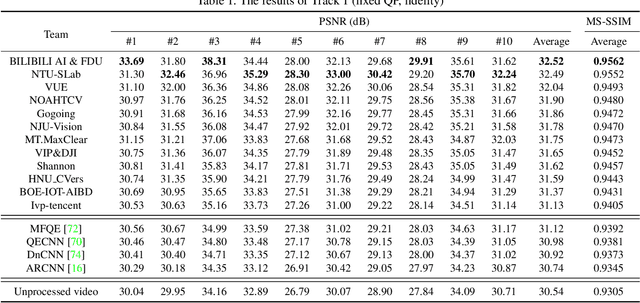
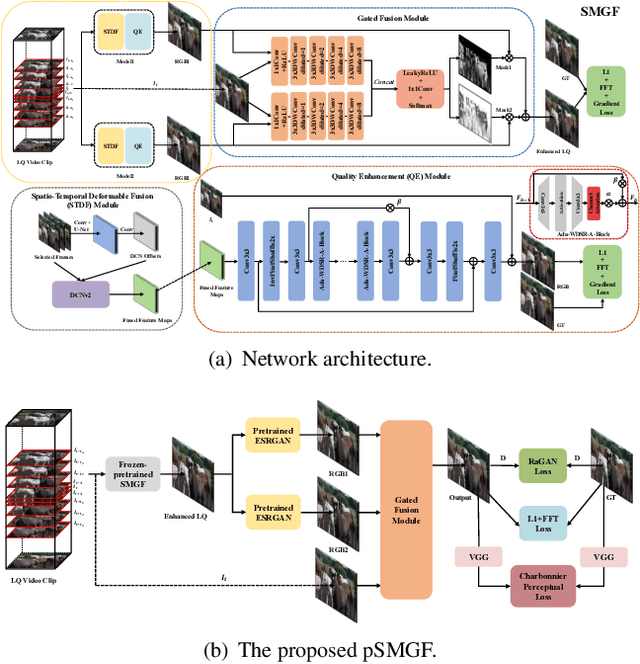
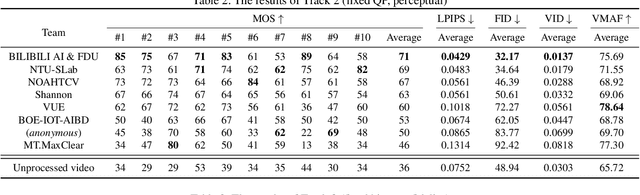
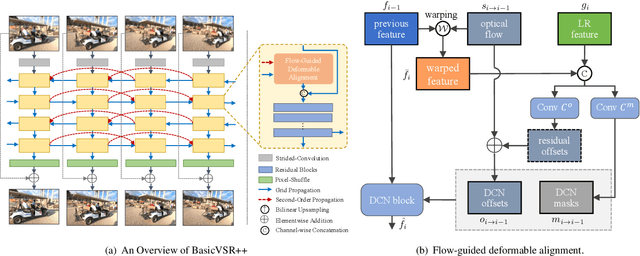
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
ISTA-Net++: Flexible Deep Unfolding Network for Compressive Sensing
Mar 22, 2021
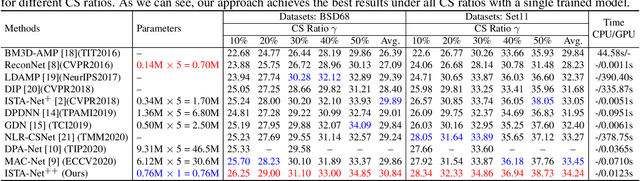

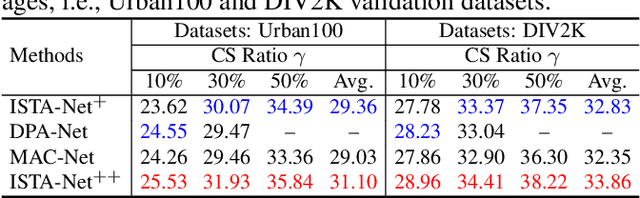
While deep neural networks have achieved impressive success in image compressive sensing (CS), most of them lack flexibility when dealing with multi-ratio tasks and multi-scene images in practical applications. To tackle these challenges, we propose a novel end-to-end flexible ISTA-unfolding deep network, dubbed ISTA-Net++, with superior performance and strong flexibility. Specifically, by developing a dynamic unfolding strategy, our model enjoys the adaptability of handling CS problems with different ratios, i.e., multi-ratio tasks, through a single model. A cross-block strategy is further utilized to reduce blocking artifacts and enhance the CS recovery quality. Furthermore, we adopt a balanced dataset for training, which brings more robustness when reconstructing images of multiple scenes. Extensive experiments on four datasets show that ISTA-Net++ achieves state-of-the-art results in terms of both quantitative metrics and visual quality. Considering its flexibility, effectiveness and practicability, our model is expected to serve as a suitable baseline in future CS research. The source code is available on https://github.com/jianzhangcs/ISTA-Netpp.
Quaternion-Based Self-Attentive Long Short-Term User Preference Encoding for Recommendation
Aug 31, 2020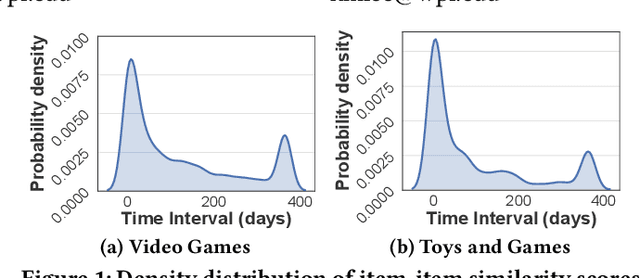
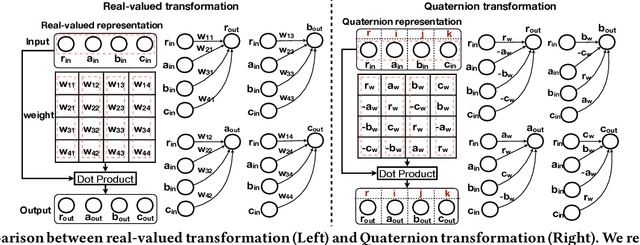
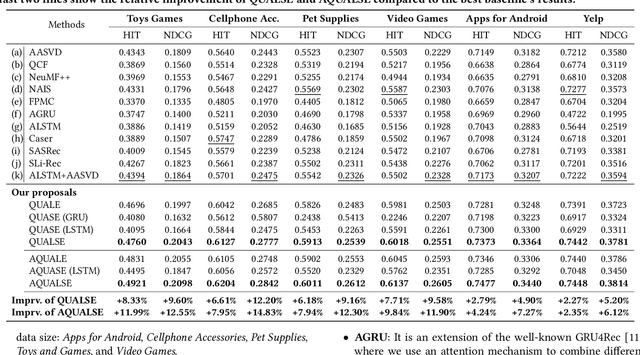
Quaternion space has brought several benefits over the traditional Euclidean space: Quaternions (i) consist of a real and three imaginary components, encouraging richer representations; (ii) utilize Hamilton product which better encodes the inter-latent interactions across multiple Quaternion components; and (iii) result in a model with smaller degrees of freedom and less prone to overfitting. Unfortunately, most of the current recommender systems rely on real-valued representations in Euclidean space to model either user's long-term or short-term interests. In this paper, we fully utilize Quaternion space to model both user's long-term and short-term preferences. We first propose a QUaternion-based self-Attentive Long term user Encoding (QUALE) to study the user's long-term intents. Then, we propose a QUaternion-based self-Attentive Short term user Encoding (QUASE) to learn the user's short-term interests. To enhance our models' capability, we propose to fuse QUALE and QUASE into one model, namely QUALSE, by using a Quaternion-based gating mechanism. We further develop Quaternion-based Adversarial learning along with the Bayesian Personalized Ranking (QABPR) to improve our model's robustness. Extensive experiments on six real-world datasets show that our fused QUALSE model outperformed 11 state-of-the-art baselines, improving 8.43% at HIT@1 and 10.27% at NDCG@1 on average compared with the best baseline.