 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignTransformer: Hierarchical Alignment of Visual Regions and Disease Tags for Medical Report Generation
Mar 18, 2022
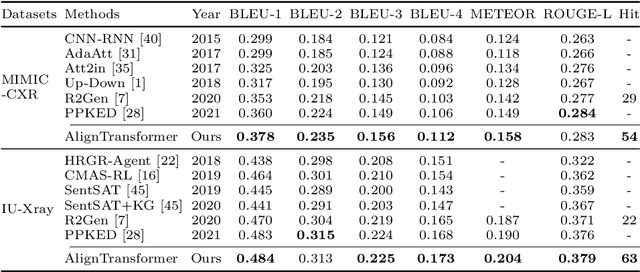
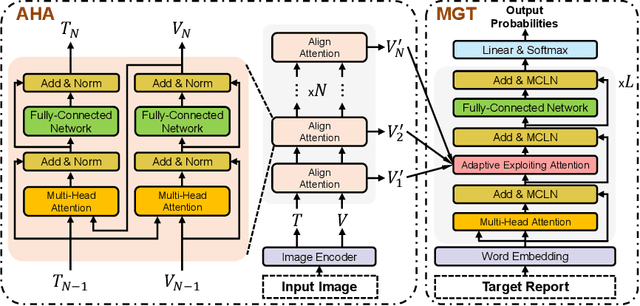
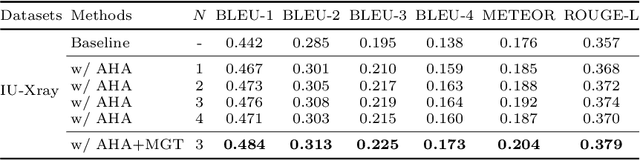
Recently, medical report generation, which aims to automatically generate a long and coherent descriptive paragraph of a given medical image, has received growing research interests. Different from the general image captioning tasks, medical report generation is more challenging for data-driven neural models. This is mainly due to 1) the serious data bias: the normal visual regions dominate the dataset over the abnormal visual regions, and 2) the very long sequence. To alleviate above two problems, we propose an AlignTransformer framework, which includes the Align Hierarchical Attention (AHA) and the Multi-Grained Transformer (MGT) modules: 1) AHA module first predicts the disease tags from the input image and then learns the multi-grained visual features by hierarchically aligning the visual regions and disease tags. The acquired disease-grounded visual features can better represent the abnormal regions of the input image, which could alleviate data bias problem; 2) MGT module effectively uses the multi-grained features and Transformer framework to generate the long medical report. The experiments on the public IU-Xray and MIMIC-CXR datasets show that the AlignTransformer can achieve results competitive with state-of-the-art methods on the two datasets. Moreover, the human evaluation conducted by professional radiologists further proves the effectiveness of our approach.