 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCORE: Syntactic Code Representations for Static Script Malware Detection
Nov 12, 2024As businesses increasingly adopt cloud technologies, they also need to be aware of new security challenges, such as server-side script attacks, to ensure the integrity of their systems and data. These scripts can steal data, compromise credentials, and disrupt operations. Unlike executables with standardized formats (e.g., ELF, PE), scripts are plaintext files with diverse syntax, making them harder to detect using traditional methods. As a result, more sophisticated approaches are needed to protect cloud infrastructures from these evolving threats. In this paper, we propose novel feature extraction and deep learning (DL)-based approaches for static script malware detection, targeting server-side threats. We extract features from plain-text code using two techniques: syntactic code highlighting (SCH) and abstract syntax tree (AST) construction. SCH leverages complex regexes to parse syntactic elements of code, such as keywords, variable names, etc. ASTs generate a hierarchical representation of a program's syntactic structure. We then propose a sequential and a graph-based model that exploits these feature representations to detect script malware. We evaluate our approach on more than 400K server-side scripts in Bash, Python and Perl. We use a balanced dataset of 90K scripts for training, validation, and testing, with the remaining from 400K reserved for further analysis. Experiments show that our method achieves a true positive rate (TPR) up to 81% higher than leading signature-based antivirus solutions, while maintaining a low false positive rate (FPR) of 0.17%. Moreover, our approach outperforms various neural network-based detectors, demonstrating its effectiveness in learning code maliciousness for accurate detection of script malware.
Ex uno plures: Splitting One Model into an Ensemble of Subnetworks
Jun 09, 2021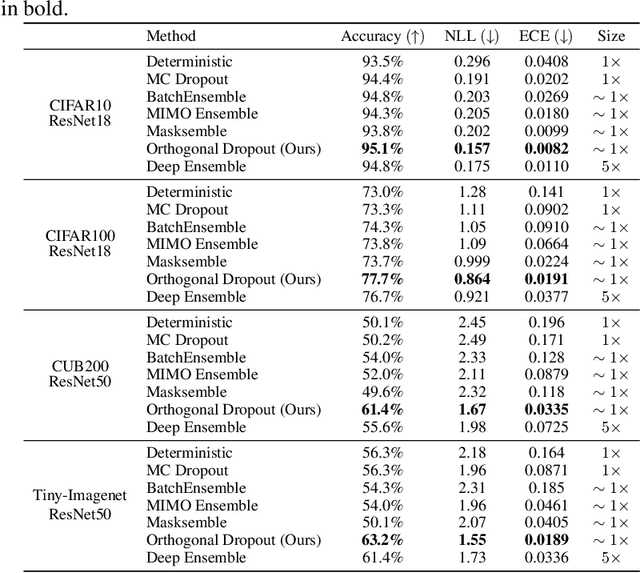
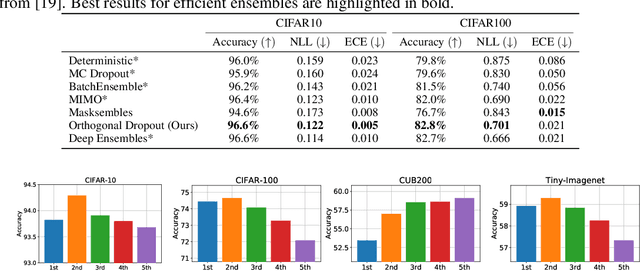
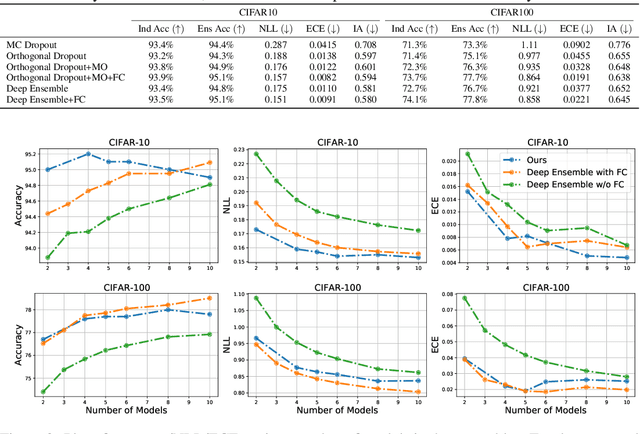

Monte Carlo (MC) dropout is a simple and efficient ensembling method that can improve the accuracy and confidence calibration of high-capacity deep neural network models. However, MC dropout is not as effective as more compute-intensive methods such as deep ensembles. This performance gap can be attributed to the relatively poor quality of individual models in the MC dropout ensemble and their lack of diversity. These issues can in turn be traced back to the coupled training and substantial parameter sharing of the dropout models. Motivated by this perspective, we propose a strategy to compute an ensemble of subnetworks, each corresponding to a non-overlapping dropout mask computed via a pruning strategy and trained independently. We show that the proposed subnetwork ensembling method can perform as well as standard deep ensembles in both accuracy and uncertainty estimates, yet with a computational efficiency similar to MC dropout. Lastly, using several computer vision datasets like CIFAR10/100, CUB200, and Tiny-Imagenet, we experimentally demonstrate that subnetwork ensembling also consistently outperforms recently proposed approaches that efficiently ensemble neural networks.