 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Automatic Training of Rule Bases that Use Numerical Uncertainty Representations
Mar 27, 2013
The use of numerical uncertainty representations allows better modeling of some aspects of human evidential reasoning. It also makes knowledge acquisition and system development, test, and modification more difficult. We propose that where possible, the assignment and/or refinement of rule weights should be performed automatically. We present one approach to performing this training - numerical optimization - and report on the results of some preliminary tests in training rule bases. We also show that truth maintenance can be used to make training more efficient and ask some epistemological questions raised by training rule weights.
Obtaining Calibrated Probabilities from Boosting
Jul 04, 2012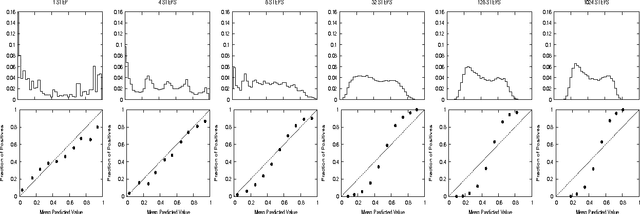

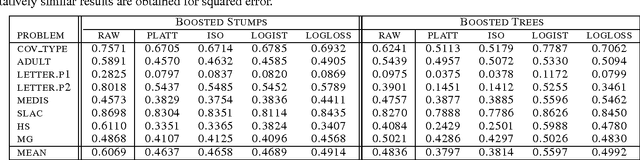

Boosted decision trees typically yield good accuracy, precision, and ROC area. However, because the outputs from boosting are not well calibrated posterior probabilities, boosting yields poor squared error and cross-entropy. We empirically demonstrate why AdaBoost predicts distorted probabilities and examine three calibration methods for correcting this distortion: Platt Scaling, Isotonic Regression, and Logistic Correction. We also experiment with boosting using log-loss instead of the usual exponential loss. Experiments show that Logistic Correction and boosting with log-loss work well when boosting weak models such as decision stumps, but yield poor performance when boosting more complex models such as full decision trees. Platt Scaling and Isotonic Regression, however, significantly improve the probabilities predicted by