 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Filters for Efficient ConvNets
Mar 10, 2017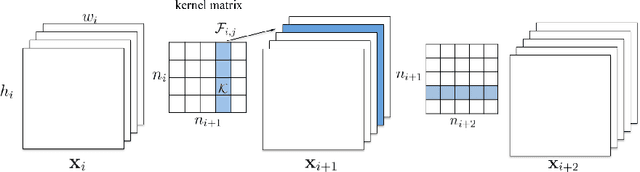
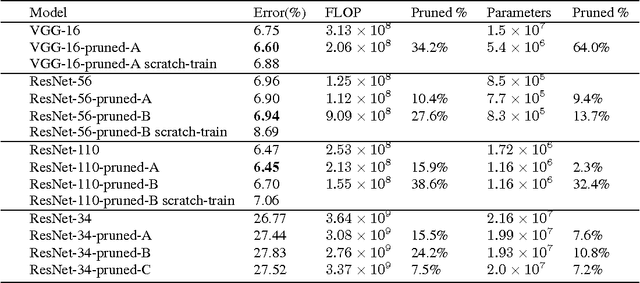
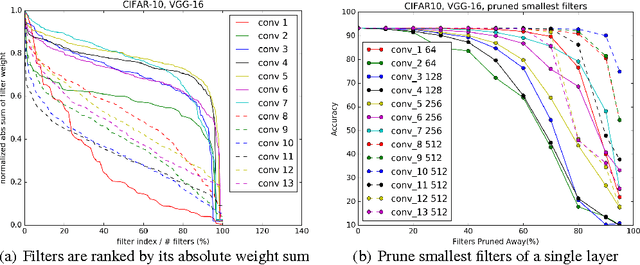
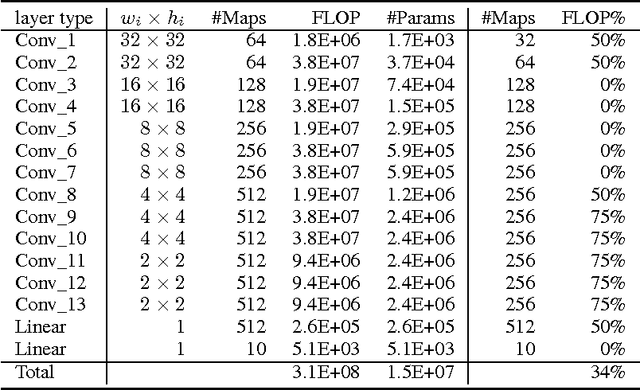
The success of CNNs in various applications is accompanied by a significant increase in the computation and parameter storage costs. Recent efforts toward reducing these overheads involve pruning and compressing the weights of various layers without hurting original accuracy. However, magnitude-based pruning of weights reduces a significant number of parameters from the fully connected layers and may not adequately reduce the computation costs in the convolutional layers due to irregular sparsity in the pruned networks. We present an acceleration method for CNNs, where we prune filters from CNNs that are identified as having a small effect on the output accuracy. By removing whole filters in the network together with their connecting feature maps, the computation costs are reduced significantly. In contrast to pruning weights, this approach does not result in sparse connectivity patterns. Hence, it does not need the support of sparse convolution libraries and can work with existing efficient BLAS libraries for dense matrix multiplications. We show that even simple filter pruning techniques can reduce inference costs for VGG-16 by up to 34% and ResNet-110 by up to 38% on CIFAR10 while regaining close to the original accuracy by retraining the networks.