 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Data Balancing for Unlabeled Satellite Imagery
Paper and Code
Jul 07, 2021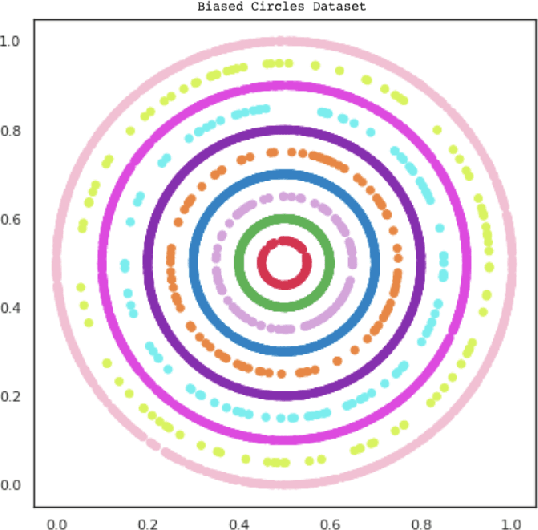
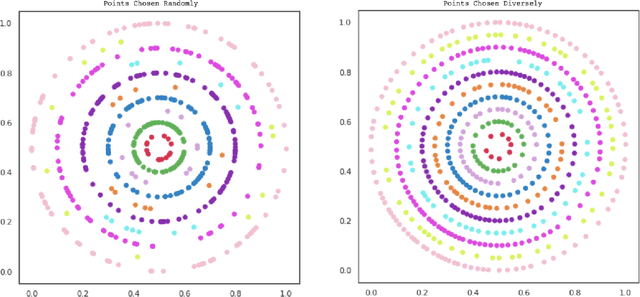
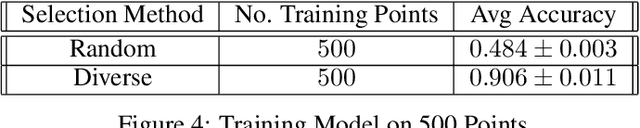
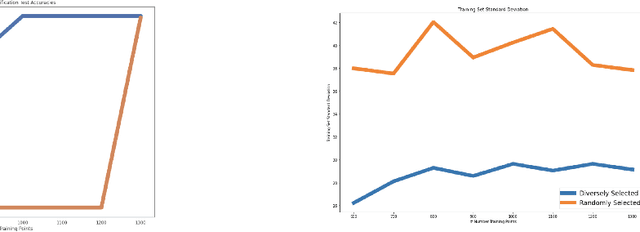
Data imbalance is a ubiquitous problem in machine learning. In large scale collected and annotated datasets, data imbalance is either mitigated manually by undersampling frequent classes and oversampling rare classes, or planned for with imputation and augmentation techniques. In both cases balancing data requires labels. In other words, only annotated data can be balanced. Collecting fully annotated datasets is challenging, especially for large scale satellite systems such as the unlabeled NASA's 35 PB Earth Imagery dataset. Although the NASA Earth Imagery dataset is unlabeled, there are implicit properties of the data source that we can rely on to hypothesize about its imbalance, such as distribution of land and water in the case of the Earth's imagery. We present a new iterative method to balance unlabeled data. Our method utilizes image embeddings as a proxy for image labels that can be used to balance data, and ultimately when trained increases overall accuracy.