 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Reverse Image Search Engine for NASAWorldview
Aug 10, 2021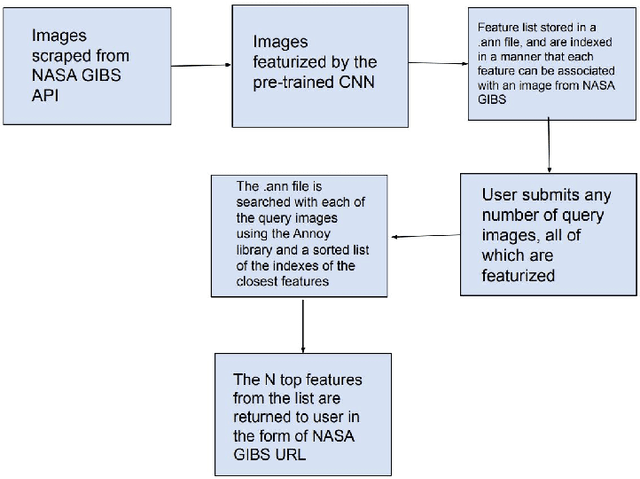
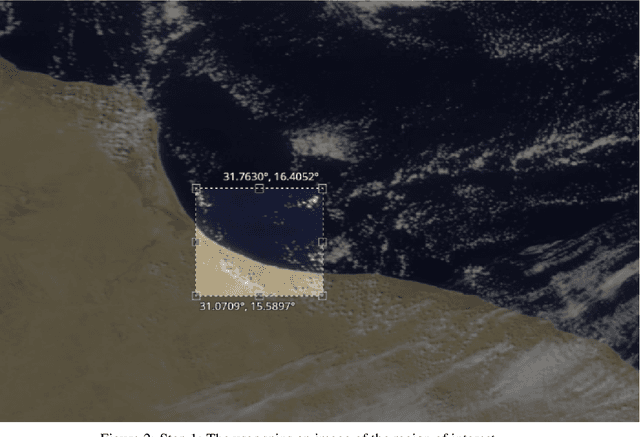


Researchers often spend weeks sifting through decades of unlabeled satellite imagery(on NASA Worldview) in order to develop datasets on which they can start conducting research. We developed an interactive, scalable and fast image similarity search engine (which can take one or more images as the query image) that automatically sifts through the unlabeled dataset reducing dataset generation time from weeks to minutes. In this work, we describe key components of the end to end pipeline. Our similarity search system was created to be able to identify similar images from a potentially petabyte scale database that are similar to an input image, and for this we had to break down each query image into its features, which were generated by a classification layer stripped CNN trained in a supervised manner. To store and search these features efficiently, we had to make several scalability improvements. To improve the speed, reduce the storage, and shrink memory requirements for embedding search, we add a fully connected layer to our CNN make all images into a 128 length vector before entering the classification layers. This helped us compress the size of our image features from 2048 (for ResNet, which was initially tried as our featurizer) to 128 for our new custom model. Additionally, we utilize existing approximate nearest neighbor search libraries to significantly speed up embedding search. Our system currently searches over our entire database of images at 5 seconds per query on a single virtual machine in the cloud. In the future, we would like to incorporate a SimCLR based featurizing model which could be trained without any labelling by a human (since the classification aspect of the model is irrelevant to this use case).
Scalable Data Balancing for Unlabeled Satellite Imagery
Jul 07, 2021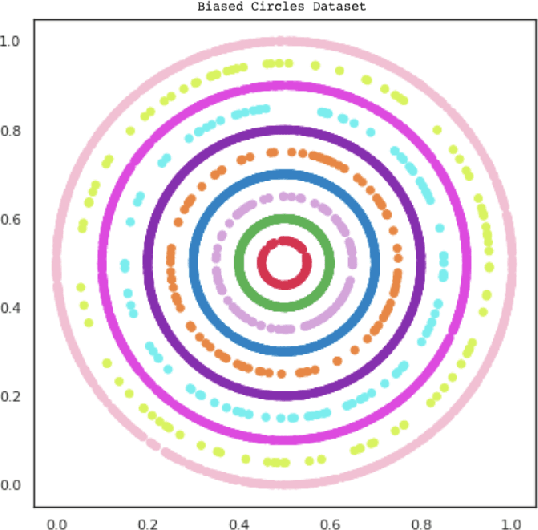
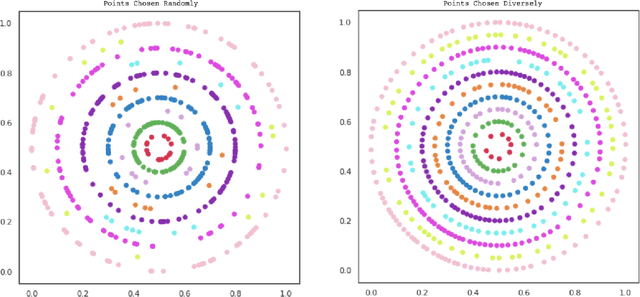
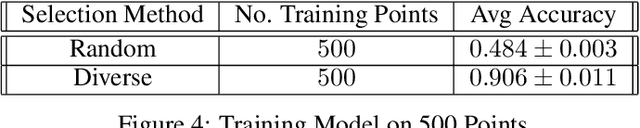
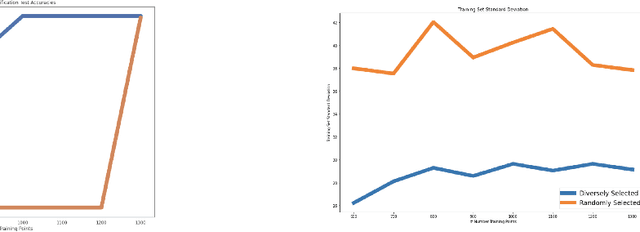
Data imbalance is a ubiquitous problem in machine learning. In large scale collected and annotated datasets, data imbalance is either mitigated manually by undersampling frequent classes and oversampling rare classes, or planned for with imputation and augmentation techniques. In both cases balancing data requires labels. In other words, only annotated data can be balanced. Collecting fully annotated datasets is challenging, especially for large scale satellite systems such as the unlabeled NASA's 35 PB Earth Imagery dataset. Although the NASA Earth Imagery dataset is unlabeled, there are implicit properties of the data source that we can rely on to hypothesize about its imbalance, such as distribution of land and water in the case of the Earth's imagery. We present a new iterative method to balance unlabeled data. Our method utilizes image embeddings as a proxy for image labels that can be used to balance data, and ultimately when trained increases overall accuracy.
Reducing Effects of Swath Gaps on Unsupervised Machine Learning Models for NASA MODIS Instruments
Jun 13, 2021



Due to the nature of their pathways, NASA Terra and NASA Aqua satellites capture imagery containing swath gaps, which are areas of no data. Swath gaps can overlap the region of interest (ROI) completely, often rendering the entire imagery unusable by Machine Learning (ML) models. This problem is further exacerbated when the ROI rarely occurs (e.g. a hurricane) and, on occurrence, is partially overlapped with a swath gap. With annotated data as supervision, a model can learn to differentiate between the area of focus and the swath gap. However, annotation is expensive and currently the vast majority of existing data is unannotated. Hence, we propose an augmentation technique that considerably removes the existence of swath gaps in order to allow CNNs to focus on the ROI, and thus successfully use data with swath gaps for training. We experiment on the UC Merced Land Use Dataset, where we add swath gaps through empty polygons (up to 20 percent areas) and then apply augmentation techniques to fill the swath gaps. We compare the model trained with our augmentation techniques on the swath gap-filled data with the model trained on the original swath gap-less data and note highly augmented performance. Additionally, we perform a qualitative analysis using activation maps that visualizes the effectiveness of our trained network in not paying attention to the swath gaps. We also evaluate our results with a human baseline and show that, in certain cases, the filled swath gaps look so realistic that even a human evaluator did not distinguish between original satellite images and swath gap-filled images. Since this method is aimed at unlabeled data, it is widely generalizable and impactful for large scale unannotated datasets from various space data domains.