 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Alignment of Medical Vision-Language Models for Grounded Radiology Report Generation
Dec 18, 2025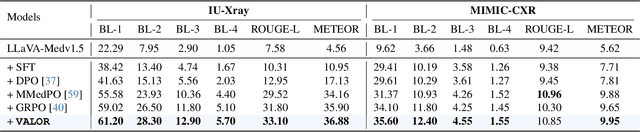
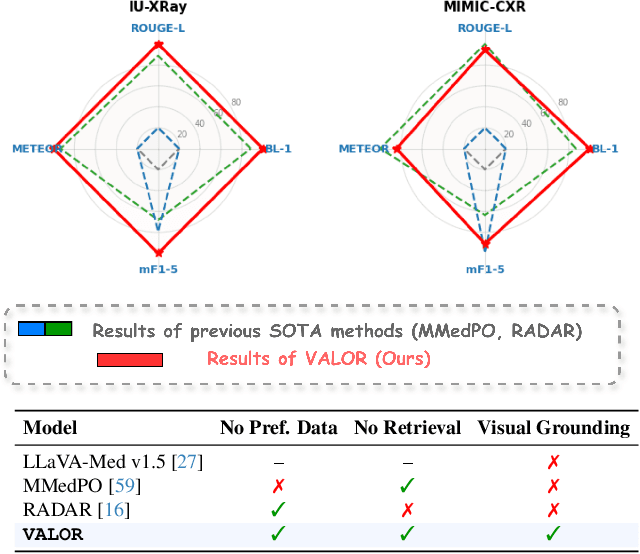
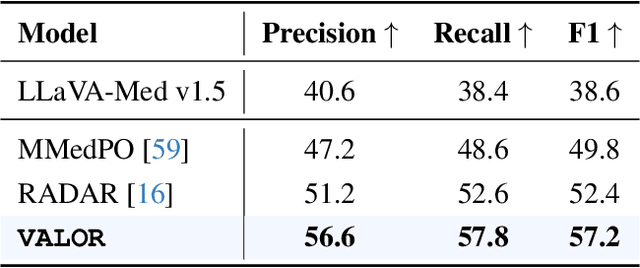
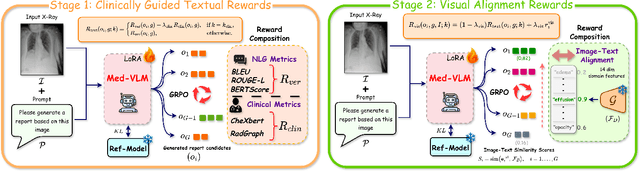
Radiology Report Generation (RRG) is a critical step toward automating healthcare workflows, facilitating accurate patient assessments, and reducing the workload of medical professionals. Despite recent progress in Large Medical Vision-Language Models (Med-VLMs), generating radiology reports that are both visually grounded and clinically accurate remains a significant challenge. Existing approaches often rely on large labeled corpora for pre-training, costly task-specific preference data, or retrieval-based methods. However, these strategies do not adequately mitigate hallucinations arising from poor cross-modal alignment between visual and linguistic representations. To address these limitations, we propose VALOR:Visual Alignment of Medical Vision-Language Models for GrOunded Radiology Report Generation. Our method introduces a reinforcement learning-based post-alignment framework utilizing Group-Relative Proximal Optimization (GRPO). The training proceeds in two stages: (1) improving the Med-VLM with textual rewards to encourage clinically precise terminology, and (2) aligning the vision projection module of the textually grounded model with disease findings, thereby guiding attention toward image re gions most relevant to the diagnostic task. Extensive experiments on multiple benchmarks demonstrate that VALOR substantially improves factual accuracy and visual grounding, achieving significant performance gains over state-of-the-art report generation methods.
A Perspective on Deep Vision Performance with Standard Image and Video Codecs
Apr 18, 2024

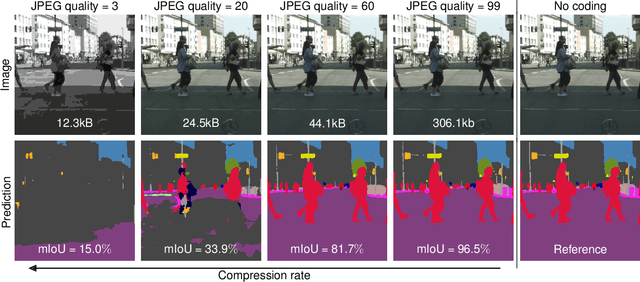
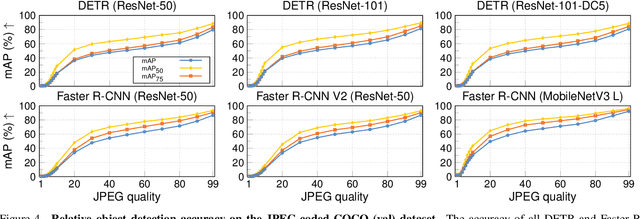
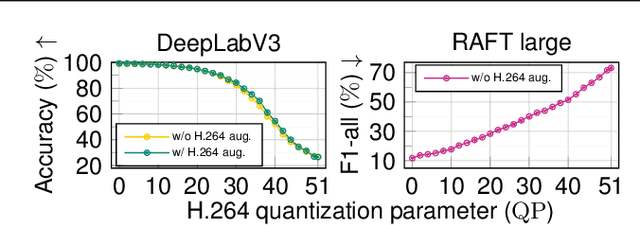
Resource-constrained hardware, such as edge devices or cell phones, often rely on cloud servers to provide the required computational resources for inference in deep vision models. However, transferring image and video data from an edge or mobile device to a cloud server requires coding to deal with network constraints. The use of standardized codecs, such as JPEG or H.264, is prevalent and required to ensure interoperability. This paper aims to examine the implications of employing standardized codecs within deep vision pipelines. We find that using JPEG and H.264 coding significantly deteriorates the accuracy across a broad range of vision tasks and models. For instance, strong compression rates reduce semantic segmentation accuracy by more than 80% in mIoU. In contrast to previous findings, our analysis extends beyond image and action classification to localization and dense prediction tasks, thus providing a more comprehensive perspective.
iRAG: An Incremental Retrieval Augmented Generation System for Videos
Apr 18, 2024



Retrieval augmented generation (RAG) systems combine the strengths of language generation and information retrieval to power many real-world applications like chatbots. Use of RAG for combined understanding of multimodal data such as text, images and videos is appealing but two critical limitations exist: one-time, upfront capture of all content in large multimodal data as text descriptions entails high processing times, and not all information in the rich multimodal data is typically in the text descriptions. Since the user queries are not known apriori, developing a system for multimodal to text conversion and interactive querying of multimodal data is challenging. To address these limitations, we propose iRAG, which augments RAG with a novel incremental workflow to enable interactive querying of large corpus of multimodal data. Unlike traditional RAG, iRAG quickly indexes large repositories of multimodal data, and in the incremental workflow, it uses the index to opportunistically extract more details from select portions of the multimodal data to retrieve context relevant to an interactive user query. Such an incremental workflow avoids long multimodal to text conversion times, overcomes information loss issues by doing on-demand query-specific extraction of details in multimodal data, and ensures high quality of responses to interactive user queries that are often not known apriori. To the best of our knowledge, iRAG is the first system to augment RAG with an incremental workflow to support efficient interactive querying of large, real-world multimodal data. Experimental results on real-world long videos demonstrate 23x to 25x faster video to text ingestion, while ensuring that quality of responses to interactive user queries is comparable to responses from a traditional RAG where all video data is converted to text upfront before any querying.
Deep Video Codec Control
Sep 16, 2023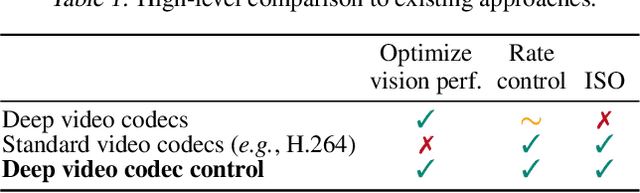
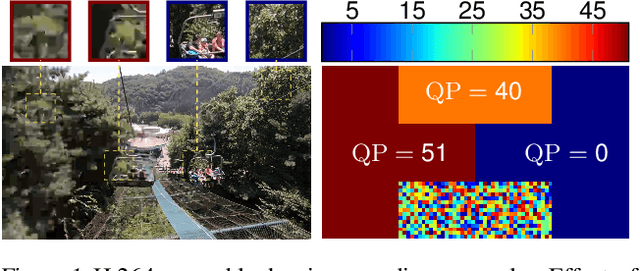
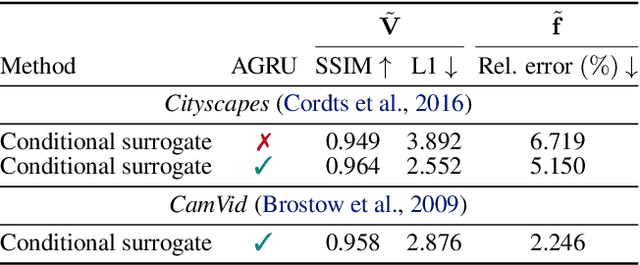
Lossy video compression is commonly used when transmitting and storing video data. Unified video codecs (e.g., H.264 or H.265) remain the de facto standard, despite the availability of advanced (neural) compression approaches. Transmitting videos in the face of dynamic network bandwidth conditions requires video codecs to adapt to vastly different compression strengths. Rate control modules augment the codec's compression such that bandwidth constraints are satisfied and video distortion is minimized. While, both standard video codes and their rate control modules are developed to minimize video distortion w.r.t. human quality assessment, preserving the downstream performance of deep vision models is not considered. In this paper, we present the first end-to-end learnable deep video codec control considering both bandwidth constraints and downstream vision performance, while not breaking existing standardization. We demonstrate for two common vision tasks (semantic segmentation and optical flow estimation) and on two different datasets that our deep codec control better preserves downstream performance than using 2-pass average bit rate control while meeting dynamic bandwidth constraints and adhering to standardizations.
Differentiable JPEG: The Devil is in the Details
Sep 13, 2023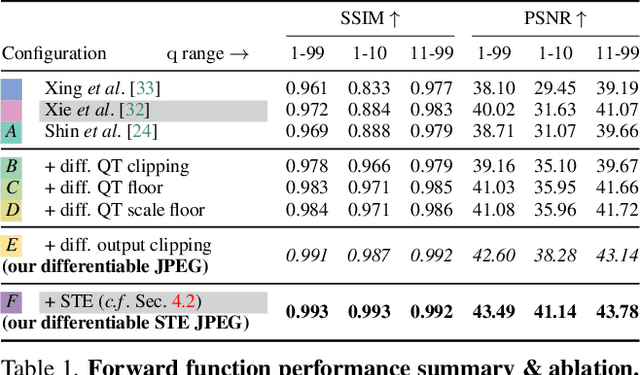
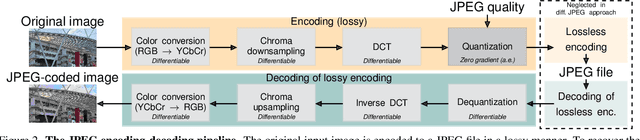
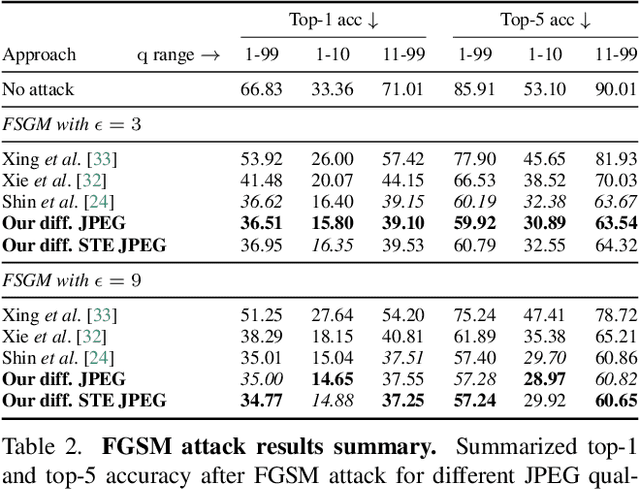

JPEG remains one of the most widespread lossy image coding methods. However, the non-differentiable nature of JPEG restricts the application in deep learning pipelines. Several differentiable approximations of JPEG have recently been proposed to address this issue. This paper conducts a comprehensive review of existing diff. JPEG approaches and identifies critical details that have been missed by previous methods. To this end, we propose a novel diff. JPEG approach, overcoming previous limitations. Our approach is differentiable w.r.t. the input image, the JPEG quality, the quantization tables, and the color conversion parameters. We evaluate the forward and backward performance of our diff. JPEG approach against existing methods. Additionally, extensive ablations are performed to evaluate crucial design choices. Our proposed diff. JPEG resembles the (non-diff.) reference implementation best, significantly surpassing the recent-best diff. approach by $3.47$dB (PSNR) on average. For strong compression rates, we can even improve PSNR by $9.51$dB. Strong adversarial attack results are yielded by our diff. JPEG, demonstrating the effective gradient approximation. Our code is available at https://github.com/necla-ml/Diff-JPEG.
LeanContext: Cost-Efficient Domain-Specific Question Answering Using LLMs
Sep 02, 2023Question-answering (QA) is a significant application of Large Language Models (LLMs), shaping chatbot capabilities across healthcare, education, and customer service. However, widespread LLM integration presents a challenge for small businesses due to the high expenses of LLM API usage. Costs rise rapidly when domain-specific data (context) is used alongside queries for accurate domain-specific LLM responses. One option is to summarize the context by using LLMs and reduce the context. However, this can also filter out useful information that is necessary to answer some domain-specific queries. In this paper, we shift from human-oriented summarizers to AI model-friendly summaries. Our approach, LeanContext, efficiently extracts $k$ key sentences from the context that are closely aligned with the query. The choice of $k$ is neither static nor random; we introduce a reinforcement learning technique that dynamically determines $k$ based on the query and context. The rest of the less important sentences are reduced using a free open source text reduction method. We evaluate LeanContext against several recent query-aware and query-unaware context reduction approaches on prominent datasets (arxiv papers and BBC news articles). Despite cost reductions of $37.29\%$ to $67.81\%$, LeanContext's ROUGE-1 score decreases only by $1.41\%$ to $2.65\%$ compared to a baseline that retains the entire context (no summarization). Additionally, if free pretrained LLM-based summarizers are used to reduce context (into human consumable summaries), LeanContext can further modify the reduced context to enhance the accuracy (ROUGE-1 score) by $13.22\%$ to $24.61\%$.
F3S: Free Flow Fever Screening
Sep 03, 2021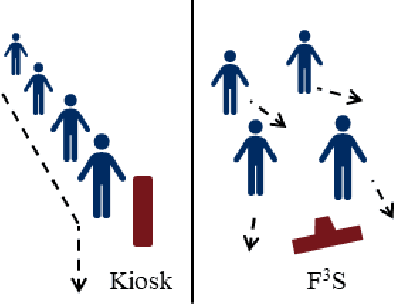
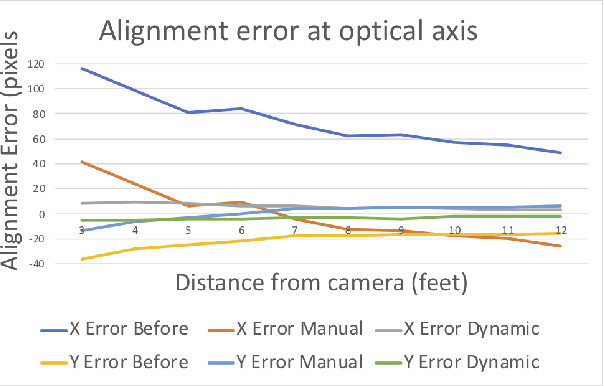
Identification of people with elevated body temperature can reduce or dramatically slow down the spread of infectious diseases like COVID-19. We present a novel fever-screening system, F3S, that uses edge machine learning techniques to accurately measure core body temperatures of multiple individuals in a free-flow setting. F3S performs real-time sensor fusion of visual camera with thermal camera data streams to detect elevated body temperature, and it has several unique features: (a) visual and thermal streams represent very different modalities, and we dynamically associate semantically-equivalent regions across visual and thermal frames by using a new, dynamic alignment technique that analyzes content and context in real-time, (b) we track people through occlusions, identify the eye (inner canthus), forehead, face and head regions where possible, and provide an accurate temperature reading by using a prioritized refinement algorithm, and (c) we robustly detect elevated body temperature even in the presence of personal protective equipment like masks, or sunglasses or hats, all of which can be affected by hot weather and lead to spurious temperature readings. F3S has been deployed at over a dozen large commercial establishments, providing contact-less, free-flow, real-time fever screening for thousands of employees and customers in indoors and outdoor settings.