 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Adaptation of Earth Observation Foundation Models for Segmentation
Sep 16, 2024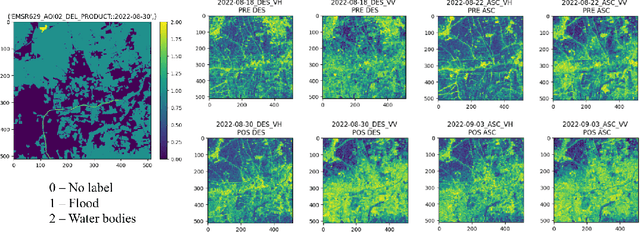
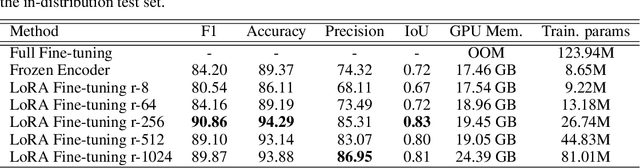

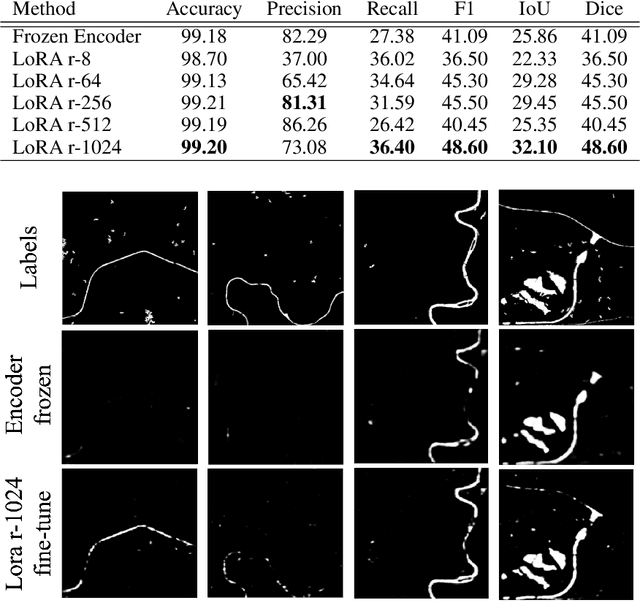
This study investigates the efficacy of Low-Rank Adaptation (LoRA) in fine-tuning Earth Observation (EO) foundation models for flood segmentation. We hypothesize that LoRA, a parameter-efficient technique, can significantly accelerate the adaptation of large-scale EO models to this critical task while maintaining high performance. We apply LoRA to fine-tune a state-of-the-art EO foundation model pre-trained on diverse satellite imagery, using a curated dataset of flood events. Our results demonstrate that LoRA-based fine-tuning (r-256) improves F1 score by 6.66 points and IoU by 0.11 compared to a frozen encoder baseline, while significantly reducing computational costs. Notably, LoRA outperforms full fine-tuning, which proves computationally infeasible on our hardware. We further assess generalization through out-of-distribution (OOD) testing on a geographically distinct flood event. While LoRA configurations show improved OOD performance over the baseline. This work contributes to research on efficient adaptation of foundation models for specialized EO tasks, with implications for rapid response systems in disaster management. Our findings demonstrate LoRA's potential for enabling faster deployment of accurate flood segmentation models in resource-constrained, time-critical scenarios.
Uncertainty and Generalizability in Foundation Models for Earth Observation
Sep 13, 2024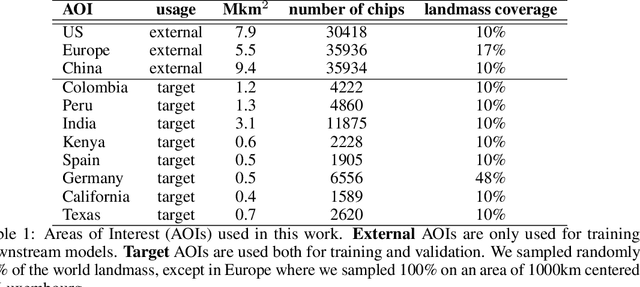
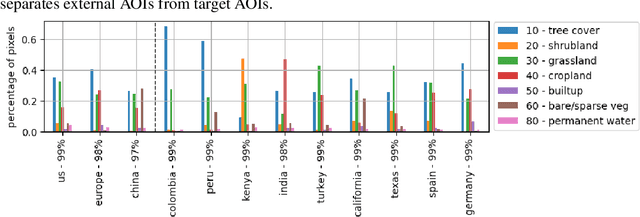
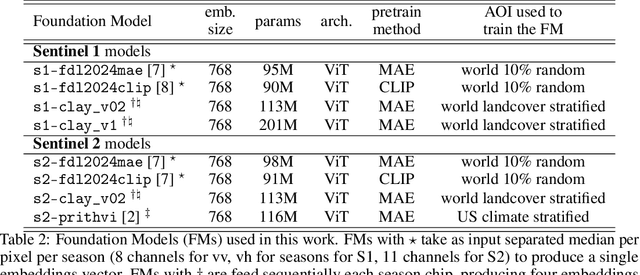
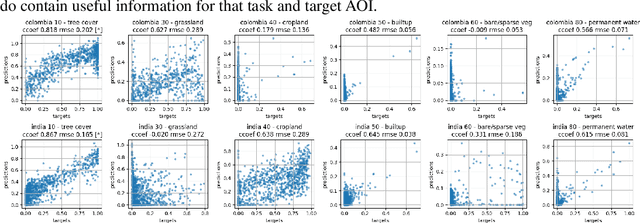
We take the perspective in which we want to design a downstream task (such as estimating vegetation coverage) on a certain area of interest (AOI) with a limited labeling budget. By leveraging an existing Foundation Model (FM) we must decide whether we train a downstream model on a different but label-rich AOI hoping it generalizes to our AOI, or we split labels in our AOI for training and validating. In either case, we face choices concerning what FM to use, how to sample our AOI for labeling, etc. which affect both the performance and uncertainty of the results. In this work, we perform a large ablative study using eight existing FMs on either Sentinel 1 or Sentinel 2 as input data, and the classes from the ESA World Cover product as downstream tasks across eleven AOIs. We do repeated sampling and training, resulting in an ablation of some 500K simple linear regression models. Our results show both the limits of spatial generalizability across AOIs and the power of FMs where we are able to get over 0.9 correlation coefficient between predictions and targets on different chip level predictive tasks. And still, performance and uncertainty vary greatly across AOIs, tasks and FMs. We believe this is a key issue in practice, because there are many design decisions behind each FM and downstream task (input modalities, sampling, architectures, pretraining, etc.) and usually a downstream task designer is aware of and can decide upon a few of them. Through this work, we advocate for the usage of the methodology herein described (large ablations on reference global labels and simple probes), both when publishing new FMs, and to make informed decisions when designing downstream tasks to use them.
Deep learning based landslide density estimation on SAR data for rapid response
Nov 18, 2022



This work aims to produce landslide density estimates using Synthetic Aperture Radar (SAR) satellite imageries to prioritise emergency resources for rapid response. We use the United States Geological Survey (USGS) Landslide Inventory data annotated by experts after Hurricane Mar\'ia in Puerto Rico on Sept 20, 2017, and their subsequent susceptibility study which uses extensive additional information such as precipitation, soil moisture, geological terrain features, closeness to waterways and roads, etc. Since such data might not be available during other events or regions, we aimed to produce a landslide density map using only elevation and SAR data to be useful to decision-makers in rapid response scenarios. The USGS Landslide Inventory contains the coordinates of 71,431 landslide heads (not their full extent) and was obtained by manual inspection of aerial and satellite imagery. It is estimated that around 45\% of the landslides are smaller than a Sentinel-1 typical pixel which is 10m $\times$ 10m, although many are long and thin, probably leaving traces across several pixels. Our method obtains 0.814 AUC in predicting the correct density estimation class at the chip level (128$\times$128 pixels, at Sentinel-1 resolution) using only elevation data and up to three SAR acquisitions pre- and post-hurricane, thus enabling rapid assessment after a disaster. The USGS Susceptibility Study reports a 0.87 AUC, but it is measured at the landslide level and uses additional information sources (such as proximity to fluvial channels, roads, precipitation, etc.) which might not regularly be available in an rapid response emergency scenario.
SAR-based landslide classification pretraining leads to better segmentation
Nov 17, 2022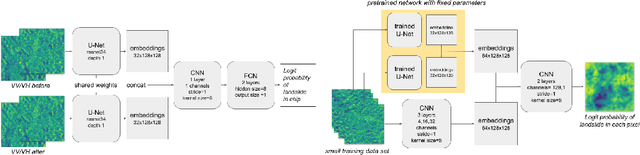
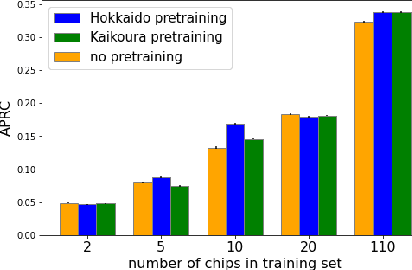
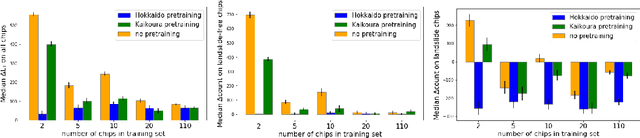
Rapid assessment after a natural disaster is key for prioritizing emergency resources. In the case of landslides, rapid assessment involves determining the extent of the area affected and measuring the size and location of individual landslides. Synthetic Aperture Radar (SAR) is an active remote sensing technique that is unaffected by weather conditions. Deep Learning algorithms can be applied to SAR data, but training them requires large labeled datasets. In the case of landslides, these datasets are laborious to produce for segmentation, and often they are not available for the specific region in which the event occurred. Here, we study how deep learning algorithms for landslide segmentation on SAR products can benefit from pretraining on a simpler task and from data from different regions. The method we explore consists of two training stages. First, we learn the task of identifying whether a SAR image contains any landslides or not. Then, we learn to segment in a sparsely labeled scenario where half of the data do not contain landslides. We test whether the inclusion of feature embeddings derived from stage-1 helps with landslide detection in stage-2. We find that it leads to minor improvements in the Area Under the Precision-Recall Curve, but also to a significantly lower false positive rate in areas without landslides and an improved estimate of the average number of landslide pixels in a chip. A more accurate pixel count allows to identify the most affected areas with higher confidence. This could be valuable in rapid response scenarios where prioritization of resources at a global scale is important. We make our code publicly available at https://github.com/VMBoehm/SAR-landslide-detection-pretraining.
Deep Learning for Rapid Landslide Detection using Synthetic Aperture Radar (SAR) Datacubes
Nov 05, 2022

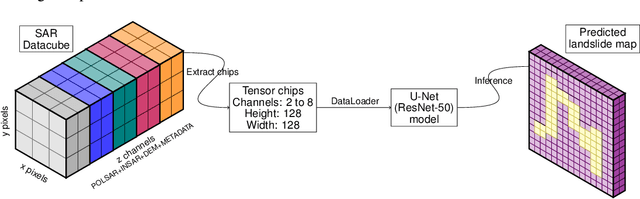
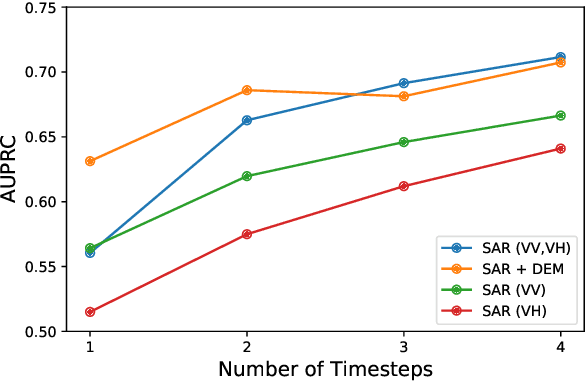
With climate change predicted to increase the likelihood of landslide events, there is a growing need for rapid landslide detection technologies that help inform emergency responses. Synthetic Aperture Radar (SAR) is a remote sensing technique that can provide measurements of affected areas independent of weather or lighting conditions. Usage of SAR, however, is hindered by domain knowledge that is necessary for the pre-processing steps and its interpretation requires expert knowledge. We provide simplified, pre-processed, machine-learning ready SAR datacubes for four globally located landslide events obtained from several Sentinel-1 satellite passes before and after a landslide triggering event together with segmentation maps of the landslides. From this dataset, using the Hokkaido, Japan datacube, we study the feasibility of SAR-based landslide detection with supervised deep learning (DL). Our results demonstrate that DL models can be used to detect landslides from SAR data, achieving an Area under the Precision-Recall curve exceeding 0.7. We find that additional satellite visits enhance detection performance, but that early detection is possible when SAR data is combined with terrain information from a digital elevation model. This can be especially useful for time-critical emergency interventions. Code is made publicly available at https://github.com/iprapas/landslide-sar-unet.