 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForce-Aware Interface via Electromyography for Natural VR/AR Interaction
Oct 03, 2022


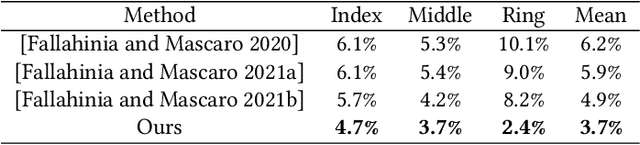
While tremendous advances in visual and auditory realism have been made for virtual and augmented reality (VR/AR), introducing a plausible sense of physicality into the virtual world remains challenging. Closing the gap between real-world physicality and immersive virtual experience requires a closed interaction loop: applying user-exerted physical forces to the virtual environment and generating haptic sensations back to the users. However, existing VR/AR solutions either completely ignore the force inputs from the users or rely on obtrusive sensing devices that compromise user experience. By identifying users' muscle activation patterns while engaging in VR/AR, we design a learning-based neural interface for natural and intuitive force inputs. Specifically, we show that lightweight electromyography sensors, resting non-invasively on users' forearm skin, inform and establish a robust understanding of their complex hand activities. Fuelled by a neural-network-based model, our interface can decode finger-wise forces in real-time with 3.3% mean error, and generalize to new users with little calibration. Through an interactive psychophysical study, we show that human perception of virtual objects' physical properties, such as stiffness, can be significantly enhanced by our interface. We further demonstrate that our interface enables ubiquitous control via finger tapping. Ultimately, we envision our findings to push forward research towards more realistic physicality in future VR/AR.
Egocentric Prediction of Action Target in 3D
Mar 24, 2022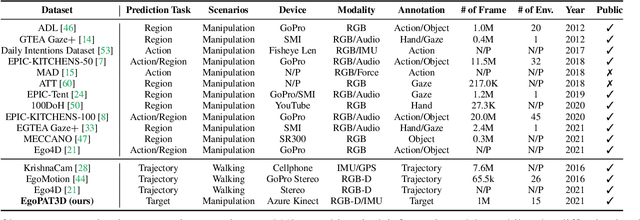
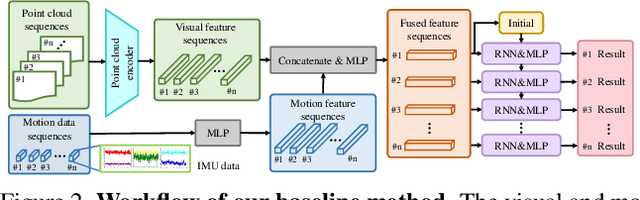
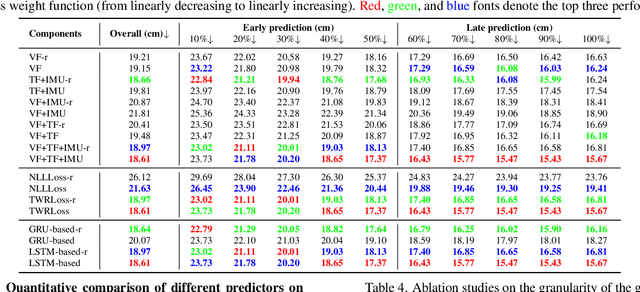

We are interested in anticipating as early as possible the target location of a person's object manipulation action in a 3D workspace from egocentric vision. It is important in fields like human-robot collaboration, but has not yet received enough attention from vision and learning communities. To stimulate more research on this challenging egocentric vision task, we propose a large multimodality dataset of more than 1 million frames of RGB-D and IMU streams, and provide evaluation metrics based on our high-quality 2D and 3D labels from semi-automatic annotation. Meanwhile, we design baseline methods using recurrent neural networks and conduct various ablation studies to validate their effectiveness. Our results demonstrate that this new task is worthy of further study by researchers in robotics, vision, and learning communities.